AI Summary
About
Lightning AI is a cloud compute platform for building, training, and deploying AI models, built by the team behind PyTorch Lightning — the widely used open-source training framework. Its core product is the “Studio”: a persistent, ready-to-code cloud workspace that can switch between CPU and GPU machines in seconds, connect to a local IDE or SSH, and run background jobs, all without the user managing infrastructure. The pricing page cites 350,000+ builders across research labs (MIT, EarthDaily Analytics) and startups (OctAI, Aeira).
The company sells the same multi-cloud compute fabric to three audiences at once: individual researchers and hobbyists on the Free and Pro tiers, small research teams on Teams, and enterprises that want to run a secure, customized AI platform inside their own VPC with their own AWS/GCP commitments. Compute is accessed through a GPU “marketplace” that spans AWS, GCP, Lightning’s own cloud, Lambda, Nebius, NScale, and Voltage, so customers pick from the world’s best clouds in one place.
Lightning AI (formerly Grid.ai, rebranded June 2022) is a venture-backed private company that has raised across a $40M Series B (2022, led by Coatue and Index Ventures) and a $50M 2024 round (Cisco Investments, J.P. Morgan, K5 Global, NVIDIA). In January 2026 it completed a merger with GPU infrastructure provider Voltage Park, forming a combined company reported at over $2.5B valuation and $500M+ ARR with a fleet of 36,000+ owned H100/B200/GB300 GPUs — a vertical-integration move from software-on-other-people’s-clouds toward owning the metal. It competes with managed ML compute and notebook platforms such as Modal, RunPod, Replicate, Paperspace, and the hyperscalers’ first-party notebook/training services — differentiating on the persistent Studio experience, second-level billing, and a credit pool that spans interruptible and on-demand machines.
Pricing summary : How Lightning AI’s credit-pool compute model works
Lightning AI uses a hybrid freemium-plus-usage model built around three dimensions:
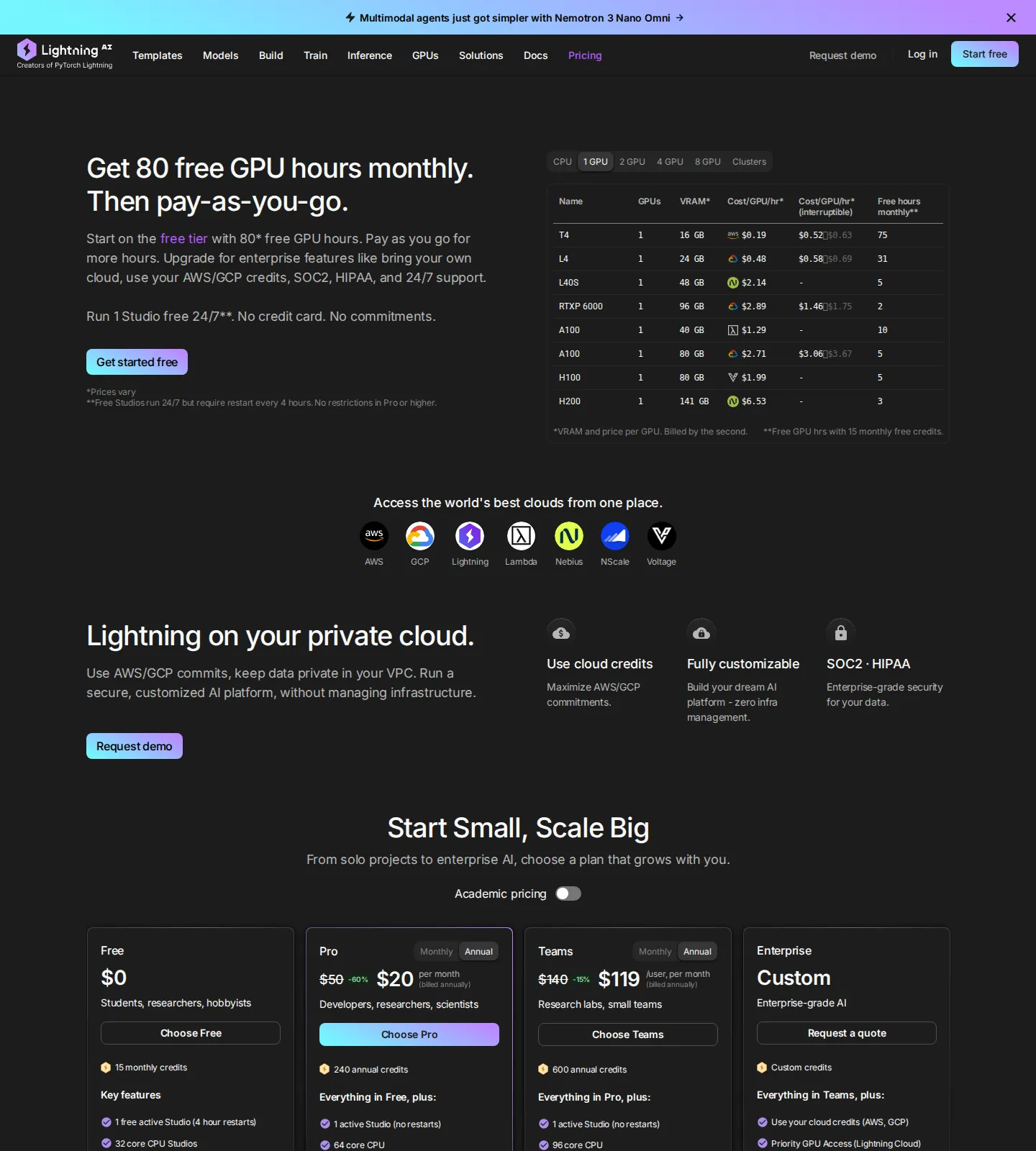
- Seat / plan tier (recurring): Free ($0), Pro ($50/mo or $20/mo billed annually), Teams ($140/user/mo or $119/user/mo billed annually), and Enterprise (custom). The plan fee mostly buys a monthly or annual credit allotment and lifts caps on concurrency, storage, and CPU/GPU size — not the compute itself.
- Usage credits (consumption): All CPU and GPU compute is billed by the second and drawn down from the credit pool. Free credits refresh monthly (15/mo ≈ 80 GPU hours on spot) and expire if unused; purchased credits expire after 12 months. When credits run out, plans pay-as-you-go for more.
- Per-GPU-hour marketplace rates: On-demand single-GPU rates span $0.19 (T4) to $6.53 (H200), with interruptible (spot) machines discounted up to 80%. Lightning’s model APIs are separately metered in requests/min and tokens/min.
What makes this different: the credit pool is the unit that bridges a hybrid pricing model and pure pay-as-you-go — your plan sets the allotment and the caps, but every second of compute is metered against credit-based billing regardless of tier.
Pricing by product
Studio compute plans (Individual plans)
| Tier | Price | Included | Key mechanics |
|---|---|---|---|
| Free | $0 | 15 monthly credits (≈80 GPU hrs on spot), 1 always-on Studio (4-hr restarts), 32-core CPU Studios, single GPUs (L40S/A100/H100/H200), up to 2 concurrent GPUs, 50 GB storage, 15 req/min + 120k tok/min model APIs | No credit card; free credits expire monthly. “Try-it-free” entry point |
| Pro | $50/mo · $20/mo billed annually | 240 annual credits, 1 active Studio (no restarts), 64-core CPU, multi-GPU (T4/L4/L40S), multi-node training (6 GPUs max), up to 6 concurrent GPUs, 200 GB storage, 20 req/min model APIs | 60% annual discount; “Pay as you go for more credits.” Most popular individual tier |
Studio compute plans (Business plans)
| Tier | Price | Included | Key mechanics |
|---|---|---|---|
| Teams | $140/user/mo · $119/user/mo billed annually | Everything in Pro plus: 600 annual credits, 96-core CPU, full-node A100/H100/H200, multi-node training (12 GPUs max), up to 12 concurrent GPUs, 2 TB storage, AWS Marketplace billing, real-time cost controls + spending limits | 15% annual discount; self-serve team setup with spend caps |
| Enterprise | Custom | Everything in Teams plus: bring your own cloud (AWS/GCP credits), priority GPU access, full-node B200s, unlimited concurrent GPUs, deploy in your own VPC, custom rate limits, Enterprise AI Hub add-on, 99.95% uptime SLA, SOC 2 Type 2, SAML/SSO, RBAC, dedicated Slack + ML engineer | Sales-led, quoted; “Request a quote” |
Sales motions across products: PLG / self-serve for Free, Pro, and Teams (online signup and checkout); sales-led for Enterprise (custom quote, VPC, and cloud-credit deals).
Per-GPU-hour marketplace rates (single GPU, on-demand vs interruptible)
Compute is billed by the second; the rates below are per GPU per hour. “Free hrs/mo” is the approximate hours the 15 free monthly credits buy on that machine.
| Machine | VRAM | On-demand $/GPU/hr | Interruptible (spot) $/GPU/hr | Free hrs/mo |
|---|---|---|---|---|
| T4 | 16 GB | $0.19 | $0.52–$0.63 | 75 |
| L4 | 24 GB | $0.48 | $0.58–$0.69 | 31 |
| L40S | 48 GB | $2.14 | — | 5 |
| RTXP 6000 | 96 GB | $2.89 | $1.46–$1.75 | 2 |
| A100 | 40 GB | $1.29 | — | 10 |
| A100 | 80 GB | $2.71 | $3.06–$3.67 | 5 |
| H100 | 80 GB | $3.29 | — | 3 |
| H200 | 141 GB | $6.53 | — | 3 |
CPU Studio rates (CPU-only Studios for coding and data prep)
| Machine | Cores | RAM | $/hr | Interruptible $/hr |
|---|---|---|---|---|
| Default (CPU) | 4 | 16 GB | Free | Free (unlimited) |
| Large (CPU) | 8 | 32 GB | $0.51 | $0.28 |
| X-Large (CPU) | 16 | 64 GB | $0.99 | $0.34 |
| Data prep | 32 | 128 GB | $1.48 | — |
| Data prep max | 64 | 256 GB | $2.69 | — |
| Data prep ultra | 96 | 384 GB | $4.79 | $3.17 |
8-GPU Studio rates (per-GPU, on-demand)
For multi-GPU Studios, per-GPU rates differ from single-GPU; the 8-GPU tab adds B200 at the top end: L4 $1.26, L40S $4.74, RTXP 6000 $2.78, A100 40 GB $3.46, A100 80 GB $1.79, H100 $1.99, H200 $5.90, B200 $9.86.
Hidden costs : What credit pools and spot rates really cost in practice
The $20/mo Pro headline understates real spend, because the plan fee only buys a fixed credit allotment — every additional GPU hour is metered on top. Two representative examples:
A solo Pro researcher training on an A100 80 GB
| Line item | Monthly cost |
|---|---|
| Pro plan (billed annually) | $20 |
| 240 annual credits ÷ 12 ≈ included compute | $0 |
| 40 extra on-demand A100 80 GB hours @ $2.71/GPU/hr | $108 |
| 10 GB extra persistent storage beyond 200 GB | (overage applies) |
| Total | ≈$128+ |
Once the bundled credits are exhausted, the per-GPU-hour rate — not the $20 seat — dominates the bill, so a single sustained A100 training run can be 5× the plan fee.
A 4-seat Teams lab running mixed H100 + spot T4 jobs
| Line item | Monthly cost |
|---|---|
| Teams plan, 4 seats @ $119/user/mo (annual) | $476 |
| 4 × 600 annual credits ÷ 12 ≈ included compute | $0 |
| 60 on-demand H100 hours @ $3.29/GPU/hr | $197 |
| 200 interruptible T4 hours @ ~$0.55/GPU/hr | $110 |
| Total | ≈$783 |
The lesson: Lightning’s seat fees are modest, but at moderate training volumes the metered GPU hours can match or exceed the platform seats — so the credit allotment and spot vs on-demand mix drive the bill far more than the tier label. This is the classic AI cost unpredictability and bill-shock trap that per-second metering both causes and, with spend caps, helps contain.
Want to estimate your own Lightning AI bill? Use the Lightning AI pricing calculator to model your monthly cost based on plan tier, GPU type, on-demand vs interruptible hours, and concurrency.
Pricing evolution : From Grid AI to a credit-pool GPU marketplace
Lightning AI’s pricing page is a client-rendered single-page app, so its historical plan dollar figures were not preserved in public archives — the milestones below are reconstructed from dated company and press announcements, and only the current live capture carries a verified rate card. Where a period’s plan prices are not documented, they are left unstated rather than estimated.
Cadence
| Quarter | Price changes | Product / SKU additions | Notes |
|---|---|---|---|
| 2022 Q2 | unknown | 1 | 2022-06-16 — Grid.ai rebrands to Lightning AI; launches the open-source AI development platform alongside a $40M Series B. Plan dollar figures for this period are not documented. |
| 2024 Q4 | unknown | 0 | 2024-11-21 — $50M raise; press documents pay-as-you-go GPU pricing with a free tier of 22 GPU hours/month (240k users / 2k orgs). |
| 2025 Q3 | unknown | 1 | 2025-08-19 — GPU Marketplace launch uniting Lambda, Nebius, Voltage Park, and Nscale; claims up to 70% AI cost reduction by routing to the cheapest capacity. |
| 2026 Q1 | unknown | 1 | 2026-01-21 — Voltage Park merger completes; combined company at >$2.5B valuation, >$500M ARR, 36,000+ owned H100/B200/GB300 GPUs. |
| 2026 Q2 | 0 | 0 | First fully verified rate-card capture: Free/Pro/Teams/Enterprise credit-pool tiers, on-demand GPU rates T4 ($0.19) → H200 ($6.53), B200 at the 8-GPU tier ($9.86/GPU/hr). |
Tracked range: 2022 Q2–2026 Q2. Per-quarter price-change counts are marked unknown where archived plan prices were not recoverable; the 2026 Q2 column reflects the first capture with verified dollar figures.
Notable changes
- 2022-06-16 — Grid.ai rebrands as Lightning AI and ships an open-source AI dev platform with a $40M Series B (Coatue, Index Ventures, Bain Capital); PyTorch Lightning cited at 20M downloads.
- 2024-11-21 — $50M raise (Cisco, J.P. Morgan, K5 Global, NVIDIA) lifts total funding to ~$103M; the free tier is publicly described as 22 GPU hours/month — the earliest documented free-tier capacity, since restructured into the current 15-monthly-credit (~80 spot GPU-hour) allotment.
- 2025-08-19 — Multi-cloud GPU Marketplace launches (Lambda, Nebius, Voltage Park, Nscale), pitching up to 70% cost savings via capacity routing.
- 2026-01-21 — Voltage Park merger completes, turning a software-and-other-clouds platform into an owned-GPU AI cloud (>$2.5B valuation, >$500M ARR, 36,000+ GPUs).
- 2026-06-02 — First verified rate-card capture: Free ($0), Pro ($20/mo annual), Teams ($119/user/mo annual), Enterprise (custom), with by-the-second credit billing and on-demand GPU rates from $0.19 (T4) to $6.53 (H200).
The Voltage Park merger in detail
The January 2026 merger is the most consequential structural change in Lightning AI’s pricing trajectory because it changes what the company actually sells. Before the merger, Lightning was primarily a software experience (Studios + credit pool) brokering compute across third-party clouds — its August 2025 GPU Marketplace explicitly positioned it as a router across Lambda, Nebius, Voltage Park, and Nscale. By absorbing Voltage Park’s 36,000+ owned H100/B200/GB300 GPUs, Lightning becomes a vertically integrated AI cloud that both sets the rate card and owns much of the underlying supply. That gives it far more control over the per-GPU-hour economics it publishes — the spot/on-demand spread and the up-to-80% interruptible discounts are now backed substantially by inventory it controls rather than purely arbitraged capacity. For buyers, the practical signal is durability: the published marketplace rates are less likely to be squeezed by a single supplier’s pricing, but the company now carries depreciation risk on a large owned fleet, which is the kind of cost pressure that historically pushes infrastructure vendors toward commitment-based discounting over time.
What’s unique : Credit pool, second-level billing, and a multi-cloud GPU marketplace
1. The plan fee buys credits, not compute. Unlike pure seat pricing, a Lightning plan is really a monthly/annual credit allotment plus higher caps. The same per-second GPU rate applies on Free and Teams; the tier changes concurrency, storage, and machine ceilings — a clean separation of pure-usage metering from the subscription envelope.
2. By-the-second billing across CPU and GPU. Every Studio — CPU or GPU, on-demand or spot — is billed by the second and drawn from one credit pool, so switching a Studio from CPU to GPU mid-session is a billing non-event rather than a new instance.
3. Spot economics are first-class. Interruptible machines are discounted up to 80%, and the rate table lists on-demand and interruptible side by side, encouraging users to default to spot for tolerant workloads (a T4 drops from $0.19 on-demand math to $0.52/GPU/hr interruptible band; data-prep CPUs run as low as $0.28/hr spot).
4. A multi-cloud GPU marketplace. Lightning brokers capacity across AWS, GCP, its own cloud, Lambda, Nebius, NScale, and Voltage — so the same Studio abstraction runs on whichever cloud has the GPU, and Enterprise can route it onto its own AWS/GCP commitments.
5. Free expires, paid lasts a year. Free credits reset and expire monthly, while purchased credits last 12 months — a deliberate nudge that keeps the free tier non-stockpilable while giving paying customers runway. It mirrors the broader shift from entitlements to credits in LLM billing, where the credit itself becomes the durable unit of value.
Strengths & weaknesses
| Strengths | Weaknesses |
|---|---|
| Transparent per-GPU-hour rate card published publicly for Free/Pro/Teams | Plan fee + credit pool + per-second rates make total cost hard to predict up front |
| By-the-second billing avoids rounding-up waste common to hourly clouds | Free credits expire monthly, so unused allotment is lost |
| Spot discounts up to 80% with on-demand and interruptible shown side by side | Spot interruptions add operational risk for long training runs |
| Multi-cloud marketplace (7 providers) avoids single-cloud GPU scarcity | Bring-your-own-cloud and AWS/GCP credits gated behind Enterprise only |
| Generous Free tier (≈80 GPU hrs/mo, 1 always-on Studio) for evaluation | Enterprise pricing is fully custom — no public floor for VPC/B200/SLA |
Billing UX : Credit meters, spend caps, and Monthly/Annual toggles
- Credit pool meter — every plan shows a monthly/annual credit allotment (15/mo Free, 240/yr Pro, 600/yr Teams) that all CPU/GPU compute draws down by the second.
- Monthly vs Annual toggle — per-plan switch on the pricing cards surfaces the annual discount inline (Pro $50→$20, Teams $140→$119).
- Real-time cost controls + spending limits — Teams and above expose organization-level cost management and hard spend caps to prevent runaway GPU bills.
- Interruptible (spot) selection — the rate table lets users pick on-demand vs interruptible per machine, with the discount shown side by side.
- Credits Auto-Reload — automatic credit top-ups (listed in the feature matrix) keep Studios running once the allotment is exhausted.
- AWS Marketplace billing — Teams can route Lightning spend through their existing AWS Marketplace contract; Enterprise can apply AWS/GCP commits.
Strategic wins : Why the credit-pool-plus-marketplace structure works
1. Decoupling the seat from the compute lets one price serve five segments
By making the plan an allotment-and-caps envelope and metering compute identically across tiers, Lightning serves hobbyists, developers, labs, and enterprises with the same rate card. This is a textbook application of separating the access fee from the usage meter, and it keeps the free tier genuinely useful without cannibalizing paid compute revenue.
2. Publishing the full GPU rate card builds trust in a murky market
GPU cloud pricing is notoriously opaque; Lightning publishes T4-through-H200 on-demand and interruptible rates openly, which lowers buyer friction and makes the platform comparable. Transparent metered rates are exactly the signal usage-based buyers look for, as we cover in usage invoicing and billing cycles.
3. Spot-first defaults align cost incentives with Lightning’s supply
Showing interruptible rates beside on-demand — and discounting them up to 80% — nudges price-sensitive users onto spare capacity, improving Lightning’s marketplace fill rate while genuinely lowering customer cost. It’s a rare win-win in usage-based pricing for SaaS and AI where the cheap option is also the operationally efficient one.
4. Vertical integration via the Voltage Park merger backs the rate card with owned supply
The January 2026 merger that absorbed Voltage Park’s 36,000+ owned GPUs turned a capacity-router into a vertically integrated AI cloud, so the published per-GPU-hour rates and up-to-80% spot discounts now sit on inventory Lightning controls rather than purely arbitraged third-party capacity. This is the same supply-side leverage that lets cost-led infrastructure players sustain aggressive metered rates, and it strengthens the credibility of the marketplace’s “70% cheaper” positioning — a durability signal usage-based buyers care about when they price in forecasting and budgeting AI usage costs.
5. Open-source flywheel (PyTorch Lightning) lowers the cost of acquiring paying compute users
Lightning’s biggest community moments are technical, not promotional: a how-to on finetuning GPT-like models drew a 498-point, 122-comment Hacker News thread (2023-05-25), “LoRA from scratch” hit 339 points (2024-01-22), and “Takeaways from hundreds of LoRA experiments” reached 258 points (2023-10-13) — all published as runnable Lightning Studios. That content-as-distribution motion seeds the free tier with already-warm developers, so the freemium credit allotment functions as a conversion surface for an audience the open-source framework already acquired, a pattern we explore in usage-based pricing for SaaS and AI.
Areas to improve : Predictability gaps and gated cloud-credit access
1. Give buyers a credit-to-dollar and credit-to-GPU-hour estimator on the page
The plan cards quote credits (15/mo, 240/yr, 600/yr) but the dollar and GPU-hour value of a credit is only implied (“15 credits ≈ 80 GPU hrs on spot”). A built-in estimator mapping credits → on-demand vs spot hours per machine would cut the biggest source of bill-shock anxiety for new users.
2. Offer a mid-tier path to bring-your-own-cloud before Enterprise
AWS/GCP credit usage and VPC deployment are Enterprise-only, which forces any cost-conscious team with existing cloud commits straight into a sales motion. A self-serve “Teams + BYOC” add-on would capture the large middle of startups that already hold cloud credits but aren’t ready for a custom contract.
3. Let Free and Pro users carry a small credit balance forward
Monthly expiry of free credits is a sound anti-stockpiling rule, but a modest rollover cap (e.g. one month) would reduce the “use-it-or-lose-it” friction that pushes bursty researchers toward competitors with pure pay-as-you-go and no expiry. The free tier has also already shifted once — from the 22 GPU hours/month documented at the November 2024 raise to today’s 15-credit (~80 spot GPU-hour) framing — and re-expressing the free allowance in credits rather than hours makes period-over-period comparison harder for the same researchers the open-source community brings in. (No pricing-backlash thread above Hacker News / Reddit trust-event thresholds was found in this review; Lightning’s high-engagement community activity is technical tutorial content, not pricing complaint.)
Monetization stack & signals : how Lightning AI builds & buys its revenue engine
Buys 2 Builds 1 4 signal roles
Lightning buys the revenue spine — HubSpot (CRM) and NetSuite (ERP/rev-rec, mid-implementation) — but builds the usage→invoice meter behind its GPU credit pricing in-house, with billing owned inside the core Go platform team. The tell is the RevOps hire below: a post-merger consumption cloud standing up order-to-cash "processes that today are manual" and pulling in Deal Desk — an enterprise quote-to-cash bridge grafted onto a self-serve credit core.
-
“Reconcile usage, billing, and cash, including matching platform/metering data and CRM order data to invoices and bank/payment records. Help build CRM, billing/revenue, and ERP tooling and the integrations between them; write desktop procedures, design controls, and scale processes that today are manual.”
-
“Lead the completion of the NetSuite implementation across procure-to-pay and order-to-cash, in partnership with cross-functional teams. Drive integration of ancillary systems (Ramp, Jira, Rippling, Justworks) into NetSuite with audit-clean data flow.”
-
“Champion data integrity and accuracy using HubSpot to track activity and manage sales opportunities through the funnel.”
-
Pricing is owned per-product by the PM, not a central monetization function — the experimentation/post-training surface is being packaged and priced as its own SKU, a sign Lightning is layering value-based product tiers on top of the flat credit-pool meter.
“Own Lightning AI's experimentation and post-training product end to end—from product strategy and roadmap through launch, adoption, pricing, and go-to-market.”
-
The canonical quote-to-cash tell: a post-merger consumption GPU cloud standing up its order-to-cash plumbing largely by hand. It buys CRM (HubSpot) and ERP/rev-rec (NetSuite) but is building the usage→invoice metering/reconciliation layer in-house — and explicitly partners with Deal Desk on contract structuring, the enterprise quote-to-cash bridge onto its self-serve credit core.
“Own the revenue operations function end to end—from how usage gets billed, to how revenue is recognized under U.S. GAAP, to how cash gets collected and reconciled... the technical owner of revenue recognition for a consumption-based GPU cloud business spanning multiple legal entities. Help build CRM, billing/revenue, and ERP tooling... processes that today are manual.”
-
Billing is owned inside the core Go platform engineering team, not a separate finance-tooling function — reinforcing that the metering-to-invoice layer behind the credit pool is an in-house build, not a Stripe/Metronome/Orb integration named anywhere in the postings.
“We're looking for a Backend Engineer to help develop and scale the Lightning AI platform, spanning APIs, infrastructure, billing, security, and integrations... Write readable/testable/efficient code in Go (Golang).”
-
Post Voltage-Park merger, FP&A must model software margins against owned-GPU-fleet infrastructure economics in one driver-based P&L — the gross-margin discipline that backs the published per-GPU-hour rate card and up-to-80% spot discounts now sitting on inventory Lightning owns and depreciates.
“Own the company-wide operating model... built on a driver-based framework that reflects both software and infrastructure dynamics... a blend of SaaS and consumption metrics alongside infrastructure economics.”
Signals reviewed · derived from public job posts
Job postings fill and close over time — once a posting is filled we keep it as a dated citation (the quoted evidence remains); use View open roles for current listings.
Key takeaways
- Separate the access fee from the usage meter. Lightning’s plan tier sets the credit allotment and caps while every second of compute is metered identically — letting one rate card serve hobbyists through enterprises without per-segment repricing.
- Bundle usage as credits, then meter against them. Quoting plans in credits (15/mo, 240/yr, 600/yr) instead of dollars lets the vendor adjust per-machine rates without re-pricing the plan, but teams must translate credits to dollars to budget.
- Make spot a visible, defaulted choice. Showing on-demand and interruptible rates side by side, with up-to-80% discounts, steers price-sensitive demand onto spare capacity — improving marketplace economics while lowering customer cost.
- Use credit expiry as a behavioral lever. Free credits expire monthly (anti-stockpiling) while purchased credits last 12 months (runway for buyers) — a deliberate split that protects free-tier economics.
- Publish the rate card in a transparency-poor market. Open per-GPU-hour pricing is a competitive wedge against opaque GPU clouds and a trust signal for usage-based buyers.
UBP implications
- Credit pools are the bridge between subscription and pure usage. Lightning shows how a credit allotment can wrap pay-as-you-go metering so customers get a predictable monthly envelope while the vendor still captures heavy-usage upside second by second.
- Marketplace pricing makes the unit rate a supply lever, not just a price. When the same meter routes across seven clouds, the per-GPU-hour rate doubles as a yield-management tool — spot discounts move demand to spare capacity.
- Expiry policy is part of the pricing model. Differential credit expiry (monthly for free, 12 months for paid) is a usage-based-pricing design choice that shapes stockpiling, churn, and free-tier cost as much as the headline rates do.
Sources
- Lightning AI pricing page — independently re-rendered to confirm plan prices and the H100 single-GPU on-demand rate (accessed 2026-06-02)
- Lightning AI billing FAQ docs (accessed 2026-06-02)
- Lightning AI GPU marketplace docs (accessed 2026-06-02)
- Lightning AI enterprise (accessed 2026-06-02)
Bottom line
Lightning AI prices a multi-cloud GPU/CPU Studio platform as a credit pool: a modest freemium seat tier (Free, $20 Pro, $119 Teams, custom Enterprise) buys a monthly credit allotment and higher caps, while all compute is billed by the second from those credits at publicly listed rates from $0.19 (T4) to $6.53 (H200), with spot discounts up to 80%. The structure is buyer-friendly and transparent, but the plan-fee-plus-credit-pool-plus-per-second-rate stack means the GPU hours, not the seat, decide the bill.
Want to compare Lightning AI against other GPU cloud and AI infrastructure pricing? Browse the pricing blueprint.
Pricing timeline : Major events on a vertical axis
Each milestone below corresponds to a public pricing change, product launch, or material adjustment. Major events use a filled marker; minor adjustments use a faded one.
Credit-pool plans with per-GPU-hour marketplace rates
Lightning AI lists Free ($0, 15 monthly credits), Pro ($20/mo billed annually, 240 annual credits), Teams ($119/user/mo billed annually, 600 annual credits), and Enterprise (custom). Compute is billed by the second and drawn from credits, with on-demand GPU rates from $0.19 (T4) to $6.53 (H200) and spot discounts up to 80%.
Voltage Park merger — combined AI-native cloud
Lightning AI completes a merger with GPU infrastructure provider Voltage Park, forming a combined company valued at over $2.5B with reported ARR above $500M and a fleet of 36,000+ owned H100/B200/GB300 GPUs. A Wayback snapshot from 2026-02 confirms the live 'Lightning merged with Voltage Park, adding 36K GPUs' banner; the SPA pricing body still did not hydrate, so no archived rate card was captured.
GPU Marketplace uniting NeoClouds and hyperscalers
Lightning AI launches a multi-cloud GPU marketplace uniting hyperscalers and NeoClouds (Lambda, Nebius, Voltage Park, Nscale), claiming AI cost reductions up to 70% by routing the same Studio across the cheapest available capacity. The release positions per-GPU-hour rate transparency and no vendor lock-in but does not publish specific rates.
$50M raise; pay-as-you-go GPU pricing with free GPU hours
Lightning AI announces a $50M raise (Cisco Investments, J.P. Morgan, K5 Global, NVIDIA), bringing total funding to ~$103M, and reports 240,000 users across 2,000 organizations. Press describes pay-as-you-go pricing with a free tier of 22 GPU hours per month — the earliest publicly documented free-tier capacity, later restructured into the current 15-monthly-credit (~80 spot GPU-hour) allotment. Archived pricing snapshots did not preserve plan dollar figures.
Grid.ai rebrands to Lightning AI + $40M Series B
Grid.ai rebrands as Lightning AI and launches an open-source AI development platform alongside a $40M Series B led by Coatue and Index Ventures (with Bain Capital, Mantis VC, First Minute Capital), bringing total raised to ~$58.6M. PyTorch Lightning is cited at 20M downloads. Archived pricing snapshots from this period did not preserve plan prices (the SPA pricing page did not hydrate in the Wayback capture), so no period rates are asserted.
- · Lightning AI is built by the team behind PyTorch Lightning, the open-source training framework with 350,000+ builders cited on its pricing page.
- · Every GPU and CPU Studio is billed by the second and drawn down from a credit pool — the headline plan fee mostly buys you a monthly credit allotment, not the compute itself.
- · The Free tier gives 15 monthly credits that map to roughly 80 GPU hours per month on interruptible (spot) machines — but those free credits expire every month if unused, while purchased credits last 12 months.
Questions & answers
- Is Lightning AI free to use?
- Yes — the Free tier costs $0, requires no credit card, and includes 15 free Lightning credits per month (about 80 GPU hours on interruptible machines) plus one always-on Studio that restarts every 4 hours. Free credits expire at the end of each month.
- How much does Lightning AI Pro cost?
- Pro is $50/month month-to-month or $20/month billed annually (a 60% annual discount), and includes 240 annual credits, up to 6 concurrent GPUs, and 200 GB of persistent storage.
- How much does the Lightning AI Teams plan cost?
- Teams is $140/user/month month-to-month or $119/user/month billed annually (a 15% annual discount), and includes 600 annual credits, up to 12 concurrent GPUs, and 2 TB of persistent storage.
- How are GPU hours billed on Lightning AI?
- Compute is billed by the second and deducted from your credit pool. On-demand single-GPU rates range from $0.19/GPU/hr (T4) and $0.48 (L4) to $3.29 (H100), $2.71 (A100 80 GB), and $6.53 (H200); interruptible (spot) instances are discounted up to 80%.
- When do Lightning AI credits expire?
- Free credits expire every month if unused. Purchased Lightning credits expire 12 months after purchase.
- Can I use my own AWS or GCP cloud credits with Lightning AI?
- Only on the Enterprise tier. Enterprise lets you bring your own cloud, apply AWS/GCP commitments, and deploy Lightning inside your own VPC, alongside SOC 2 Type 2, SAML/SSO, and a 99.95% uptime SLA.