AI Summary
About
ScraperAPI is a web scraping API that hides the hardest parts of large-scale data collection — proxy rotation, headless-browser rendering, CAPTCHA solving, and anti-bot bypassing — behind a single HTTP endpoint. A developer sends a target URL with optional parameters (render, premium, ultra_premium, country_code) and ScraperAPI returns the page HTML or structured JSON, handling retries, IP rotation, and bot-detection bypass server-side. Core features such as JS rendering, premium proxies, JSON auto-parsing, rotating proxy pools, CAPTCHA/anti-bot detection, and unlimited bandwidth are included on every plan.
The company sells primarily to developers and data teams who would otherwise maintain their own proxy fleets and browser farms. It positions itself against both DIY scraping stacks and competitors like Bright Data, Zyte, and Oxylabs, competing on developer experience (a “dead simple API”) and predictable credit-based pricing rather than per-GB proxy bandwidth. ScraperAPI advertises being trusted by 10,000+ companies and offers a 99.9% uptime guarantee on all plans.
ScraperAPI’s origin shapes its pricing instincts. It was founded in 2018 by Daniel Ni — a Yale graduate and ex-Wall Street developer who also writes the TLDR tech newsletter — and bootstrapped, with no venture funding, to roughly $3M in revenue, 10,000 customers, and about seven employees before being acquired by SaaS.group in August 2020. That bootstrapped-then-acquired lineage helps explain a pricing page that prizes self-serve transparency and steady, defensible tier prices over aggressive enterprise gating.
In 2026 ScraperAPI extended its surface again: on 2026-04-30 it acquired Traject Data, the company behind the Rainforest API and SerpWow and a stack of ten real-time SERP and e-commerce data APIs. That deal extends the same API-credit economy across structured search-results and marketplace data, reinforcing ScraperAPI’s move from a raw-proxy abstraction toward a broader managed data-collection platform. For a contrasting take on metering a proxy-heavy product, compare Firecrawl’s credit-based scraping pricing.
Pricing summary : How ScraperAPI’s API-credit and concurrency model works
ScraperAPI uses a tiered subscription priced on two dimensions — a monthly API-credit allotment and a concurrent-thread cap — layered over a credit multiplier that makes harder requests cost more:
- Monthly API credits: Each plan bundles a fixed credit pool, from 100,000 (Hobby) to 21,500,000 (Advanced), with Enterprise starting at 22,000,000+. Credits are the spend meter, not raw request counts.
- Concurrent threads: The number of simultaneous requests allowed, from 20 (Hobby) to 500 (Advanced/Enterprise). This is the throughput governor that sits alongside the credit budget.
- Credit multiplier: A standard request costs 1 credit, but JS rendering or premium proxies cost 10, premium+render costs 25, and ultra-premium+render costs 75 credits per request. Hard-target domains carry fixed costs (Amazon 5, Google/Bing SERP 25, LinkedIn 30).
- Overage handling: Pay-as-you-go overage at a fixed per-credit rate is available only on Scaling and above; Hobby/Startup/Business must upgrade when credits run out.
- Billing cadence: Monthly or annual, with annual billing taking 10% off every paid plan.
What makes this different: the headline credit count is deceptively variable — because the multiplier can range from 1× to 75×, two customers on the same 100,000-credit plan can do anywhere from ~1,333 to 100,000 actual scrapes depending on how much JS rendering and proxy escalation each job needs. This is a credit-based billing model where the “value metric” is effectively normalized request difficulty rather than a flat request.
Pricing by product
ScraperAPI core (self-serve plans)
| Tier | Price | Included | Key mechanics |
|---|---|---|---|
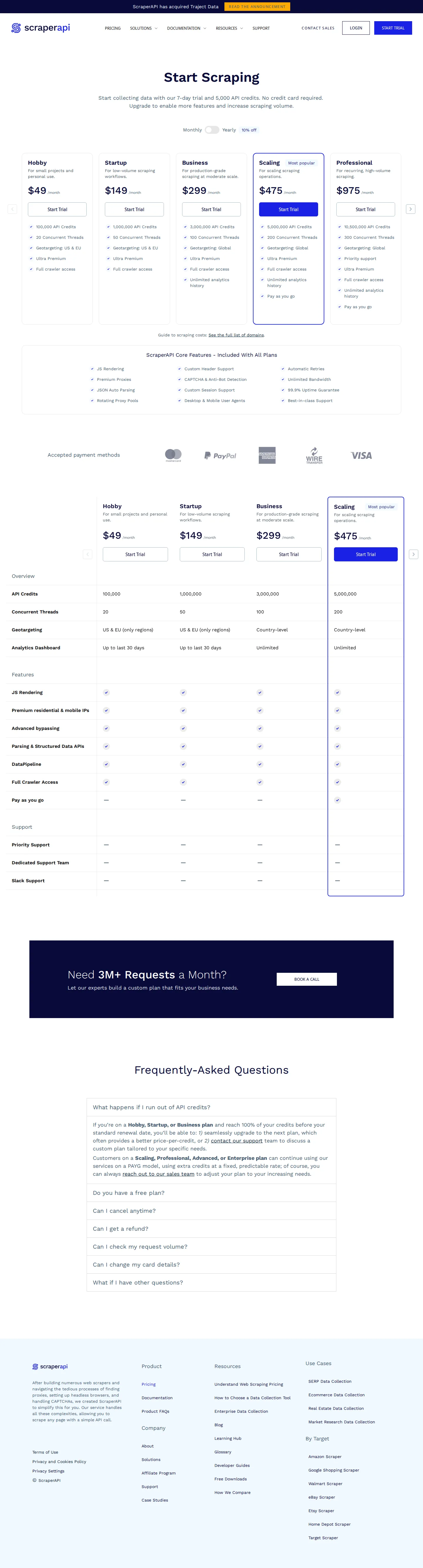
| Hobby | $49 / mo | 100,000 API credits; 20 concurrent threads; geotargeting US & EU; 30-day analytics | Entry tier; no PAYG — upgrade when credits run out |
| Startup | $149 / mo | 1,000,000 API credits; 50 concurrent threads; geotargeting US & EU | No PAYG; upgrade-to-continue |
| Business | $299 / mo | 3,000,000 API credits; 100 concurrent threads; global (country-level) geotargeting; unlimited analytics | First tier with global geotargeting + unlimited analytics |
| Scaling | $475 / mo | 5,000,000 API credits; 200 concurrent threads; global geotargeting | ”Most popular”; first tier with pay-as-you-go overage |
| Professional | $975 / mo | 10,500,000 API credits; 300 concurrent threads; priority support | PAYG overage; high-volume recurring jobs |
| Advanced | $1,975 / mo | 21,500,000 API credits; 500 concurrent threads; priority routing | PAYG overage; continuous multi-source pipelines |
ScraperAPI core (enterprise)
| Tier | Price | Included | Key mechanics |
|---|---|---|---|
| Enterprise | Custom | 22,000,000+ API credits; 500+ concurrent threads; dedicated support team + Slack; PAYG | Sales-led, quoted; “Let’s talk” |
Sales motions across products: PLG / self-serve for Hobby through Advanced (sign up, 7-day trial, pay online); sales-led for Enterprise and any custom-volume deal above ~3M requests/month.
Credit multiplier (how a request is priced)
Every request spends credits according to its difficulty. Verbatim from ScraperAPI’s docs:
| Request type | Credit cost per request |
|---|---|
| Standard request (no parameters) | 1 |
premium=true | 10 |
render=true (JS rendering) | 10 |
screenshot=true | 10 |
premium=true + render=true | 25 |
ultra_premium=true | 30 |
ultra_premium=true + render=true | 75 |
| Cloudflare / Turnstile / Datadome / PerimeterX bypass | 10 |
Parameters such as country_code, device_type, wait_for_selector, session_number, output_format, keep_headers, and autoparse incur no extra credit cost.
Hard-target domain costs (fixed multipliers)
| Domain | Credit cost per request |
|---|---|
| Amazon (e-commerce) | 5 |
| Google / Bing SERP (all subdomains) | 25 |
| 30 |
Accounts with custom discounted deals pay a higher per-request credit cost on ultra-premium domains to meet ScraperAPI’s minimum pricing of $3 per 1,000 requests without rendering and $7 per 1,000 with rendered pages.
Hidden costs : How the credit multiplier inflates real per-scrape cost
The headline “100,000 API credits for $49” understates real cost because most production scraping needs JS rendering or premium proxies, which cost 10× a plain request. Two worked examples:
Archetype 1 — Hobby user scraping JS-rendered pages
| Line item | Monthly cost / capacity |
|---|---|
| Hobby plan base | $49 |
100,000 credits ÷ 10 credits per render=true request | 10,000 rendered scrapes |
| Effective cost per rendered scrape | ~$0.0049 |
| What you actually get | 10,000 JS-rendered pages, not 100,000 |
A buyer reading “100,000 credits” as “100,000 scrapes” overestimates capacity 10× the moment they enable rendering.
Archetype 2 — Business user scraping Google SERPs
| Line item | Monthly cost / capacity |
|---|---|
| Business plan base | $299 |
| 3,000,000 credits ÷ 25 credits per Google SERP | 120,000 SERP requests |
| Effective cost per SERP request | ~$0.0025 |
| What you actually get | 120,000 SERPs, not 3,000,000 |
So a 3M-credit plan delivers only 120,000 Google SERP pulls — the domain multiplier, not the headline credit count, sets real capacity.
Want to estimate your own ScraperAPI bill? Use the ScraperAPI pricing calculator to model your monthly cost based on credit multipliers, target domains, and concurrent-thread needs.
Pricing evolution : From flat “API calls” to a difficulty-weighted credit economy
ScraperAPI’s pricing has been unusually stable on the surface and unusually deep underneath. The headline tier prices barely moved for years, but the unit behind them changed fundamentally in 2022 — from flat “API calls” to difficulty-weighted “API credits” — and the public tier count has expanded and contracted as the product moved upmarket.
Cadence
| Quarter | Price changes | Product / SKU additions | Notes |
|---|---|---|---|
| 2019 Q3 | 0 | 0 | Earliest archived pricing: four tiers metered in flat “API Calls” — Hobby $29 (250K calls) / Startup $99 / Business $249 / Custom Enterprise. |
| 2021 Q1 | 0 | 0 | Same $29 / $99 / $249 ladder and “API Calls” metering; ~2 years of price stability on public tiers. |
| 2022 Q3 | 4 | 1 | Major repricing and model shift: Hobby $29 → $49 (250K calls → 100K credits), Startup $99 → $149, Business $249 → $299; new Professional $999 (14M credits); metering renamed to “API Credits” + “Concurrent Threads” with the per-request multiplier introduced. |
| 2023 Q3 | 0 | 0 | ”Save 10% on Yearly Plan” annual-billing discount surfaced across tiers; per-request credit costs unchanged. |
| 2024 Q2 | 0 | 0 | Professional $999 pulled from the public self-serve grid into the sales-led path; monthly/annual toggle made prominent ($44 annual Hobby). |
| 2025 Q4 | 1 | 1 | New Scaling $475 tier (5M credits, 200 threads) added as “Most popular”; per-feature comparison matrix and DataPipeline product surfaced. |
| 2026 Q2 | 0 | 1 | Seven public tiers live (Hobby $49 → Advanced $1,975 + custom Enterprise); Traject Data acquisition (2026-04-30) folds SERP/e-commerce APIs into the credit economy. |
Tracked range: 2019-07 – 2026-06 (Wayback CDX + live capture). Quarters not listed were verified stable (0 price changes, 0 SKU additions) across the sampled snapshots.
Notable changes
- 2019-07 — Earliest archived pricing: Hobby $29 / Startup $99 / Business $249 / Custom Enterprise, metered in flat “API Calls”, with 1,000 free API calls and a 7-day refund policy (Wayback snapshot, accessed 2026-06-04).
- 2020-08-13 — ScraperAPI was acquired by SaaS.group after bootstrapping to ~$3M revenue and 10,000 customers under founder Daniel Ni.
- 2022-Q3 — The pivotal change: between the May and August 2022 snapshots ScraperAPI raised prices (Hobby $29 → $49) and replaced flat “API Calls” with the “API Credits” model and its 1–75× difficulty multiplier; a $999 Professional tier was added (Wayback snapshots, accessed 2026-06-04).
- 2023 — Annual billing introduced at a 10% discount across plans.
- 2024-Q2 — The $999 Professional tier was removed from the public self-serve grid and routed through sales (Wayback 2024-06).
- 2025-Q4 — A new Scaling tier at $475/mo (5M credits, 200 threads) was added as the “Most popular” plan; the DataPipeline scheduled-scraping product surfaced in the comparison matrix (Wayback 2025-12).
- 2026-04-30 — ScraperAPI acquired Traject Data (Rainforest API, SerpWow, ten SERP/e-commerce APIs), extending the API-credit model to structured data products.
The 2022 model shift in detail
The single most consequential pricing decision in ScraperAPI’s history was not a price increase — it was a change of unit. Before mid-2022, a “request” was a request: Hobby’s 250,000 “API Calls” meant 250,000 fetches regardless of difficulty. After the shift, the same Hobby plan bought 100,000 “API Credits”, and a credit was no longer one fetch — a JS-rendered or premium-proxy request now cost 10 credits, and an ultra-premium rendered request up to 75. The nominal capacity fell (250K → 100K) and the price rose ($29 → $49), but the deeper move was decoupling price from raw volume and re-coupling it to cost-to-serve. That single change is why ScraperAPI could hold the same $49 / $149 / $299 headline prices for years afterward: as anti-bot defenses hardened and rendering got more expensive, the multiplier — not the sticker price — absorbed the cost. It is a textbook example of the broader entitlement-to-credits billing shift.
What’s unique : Difficulty-weighted credits and concurrency caps
1. Credits are difficulty-weighted, not request-flat. The same credit pool buys wildly different scrape counts depending on whether you need JS rendering (10×), premium proxies (10×), or ultra-premium + render (75×). This makes ScraperAPI’s value metric closer to “normalized request difficulty” than raw requests.
2. Concurrency is a separate, hard governor. Beyond the credit budget, each plan caps concurrent threads (20 → 500). Two customers with identical credit pools can have very different throughput ceilings, so concurrency is a deliberate up-sell lever independent of volume.
3. Overage is a tier privilege, not a default. Pay-as-you-go overage only unlocks on Scaling and above; lower tiers are forced to upgrade when they exhaust credits. ScraperAPI uses PAYG as a retention/expansion feature for larger accounts rather than a universal safety valve.
Strengths & weaknesses
| Strengths | Weaknesses |
|---|---|
| Fully public, self-serve pricing across six tiers | Headline credit counts overstate real capacity once multipliers apply |
| Predictable monthly credit pools simplify budgeting | No permanent free plan — only a 7-day, 5,000-credit trial |
| Difficulty multiplier aligns price with request cost | 75× ultra-premium+render multiplier can burn a plan fast |
| All core features (JS render, premium proxies, parsing) on every plan | PAYG overage gated to upper tiers; lower tiers must hard-upgrade |
| Concurrency caps give a clean throughput up-sell lever | Domain multipliers (SERP 25, LinkedIn 30) are easy to overlook |
Billing UX : Credit-cost lookups and per-request cost headers
- Monthly / Yearly toggle — a switch on the pricing page flips all plan prices between monthly and annual billing, where annual takes 10% off every plan.
- Domain Multiplier lookup — an in-dashboard tool to look up the exact credit cost for any target URL before scraping it.
- API Playground — lets users test target URLs and see actual credit usage per request before running jobs at scale.
urlcostAPI endpoint —https://api.scraperapi.com/account/urlcost?api_key=…&url=…&render=truereturns the credit cost of a specific request programmatically.sa-credit-costresponse header — every API response includes this header showing the exact credit cost of that request.- API credit spend limits — users can set caps on API credit expenditure to control runaway spend.
- Analytics dashboard — request-volume and credit-usage history (last 30 days on lower tiers; unlimited on Business and above).
Strategic wins : Decisions that fit the scraping market
1. Difficulty-weighted credits keep margins safe as targets harden
By charging 10–75× more for rendered and ultra-premium requests, ScraperAPI ties price directly to the underlying proxy/compute cost. As anti-bot defenses escalate, the multiplier absorbs the cost increase without forcing a headline price change — a cleaner version of the entitlement-to-credits shift playing out across usage-based products.
2. Concurrency as an independent up-sell lever
Separating throughput (threads) from volume (credits) gives ScraperAPI two orthogonal expansion paths. A customer who is not volume-constrained but is latency-constrained still has a reason to move up a tier, which widens the addressable upgrade surface. See our guide to choosing the right usage metric.
3. Fully public pricing in a sales-gated category
Most enterprise proxy and scraping vendors hide pricing behind sales calls; ScraperAPI publishes six self-serve tiers with exact credit counts and thread caps, plus a transparent multiplier table in its docs. That transparency is a strong first-click acquisition advantage with developer buyers who evaluate by reading the pricing page, not by booking a demo.
Areas to improve : Make real capacity legible up front
1. Surface effective scrape counts, not just credits
The pricing page leads with raw credit counts that overstate capacity 10–75× once rendering or premium proxies are on. A toggle that re-expresses each plan as ”≈ X rendered pages / Y SERP requests” would prevent the most common buyer miscalculation and reduce churn from capacity surprise. See our guide to thresholding and alerting.
2. Extend PAYG overage to entry tiers
Forcing Hobby/Startup/Business users to hard-upgrade when credits run out creates friction at exactly the moment a customer is succeeding. A capped PAYG option on lower tiers would smooth the upgrade path and capture revenue that currently turns into a failed request or an abrupt plan jump.
3. Add a permanent free tier, not just a 7-day trial
A 7-day, 5,000-credit trial expires before many developers finish evaluating, and there is no standing free allowance to keep light users in the funnel. A small always-free tier (e.g. 1,000 credits/month) would lower the activation barrier and feed the upgrade path, a pattern that works well for credit-metered AI products where trial-to-paid conversion is fragile.
Key takeaways
- Weight your usage meter by cost-to-serve. ScraperAPI’s 1–75 credit multiplier shows how to keep a single value metric (credits) while still charging more for genuinely more expensive work, protecting margin without constant price changes.
- Headline units can mislead — design for that. A “100,000 credits” anchor reads as 100,000 scrapes but can be 1,333; teams should publish effective-capacity examples so the buyer’s mental model matches the bill.
- Separate throughput from volume. Concurrency caps independent of credit pools create a second expansion axis without touching the price of volume.
- Gate overage deliberately. Reserving PAYG for upper tiers turns a safety valve into an expansion feature, but at the cost of entry-tier friction — a real trade-off, not a free lunch.
- Fixed domain multipliers price hard targets honestly. Charging 25 credits for a SERP and 30 for LinkedIn ties price to the difficulty of specific high-value sources.
UBP implications
- Difficulty-normalized credits are a maturity signal for usage-based pricing. Instead of one flat unit, ScraperAPI normalizes heterogeneous work into a single credit currency with multipliers — a pattern any API with variable cost-to-serve (LLMs, rendering, proxies) can adopt.
- Two-axis metering (volume + concurrency) expands the upgrade surface. When throughput and volume are billed separately, vendors capture customers constrained on either axis without a packaging overhaul.
- Overage placement is a packaging decision, not a default. Whether PAYG is universal or tier-gated materially changes both churn and expansion economics, and should be modeled explicitly rather than assumed.
Sources
- ScraperAPI pricing page (accessed 2026-06-04)
- ScraperAPI credits and request costs docs (accessed 2026-06-04)
- ScraperAPI contact sales (accessed 2026-06-04)
Bottom line
ScraperAPI sells a single value metric — the API credit — but bends it with a 1-to-75 difficulty multiplier so price tracks the real cost of rendering, premium proxies, and hard-target domains. The headline credit counts are generous on paper and far smaller in practice, making effective-capacity literacy the key to buying it well; concurrency caps and tier-gated overage give the company two clean expansion levers on top of raw volume.
Want to compare ScraperAPI against other data-platform pricing? Browse the pricing blueprint.
Pricing timeline : Major events on a vertical axis
Each milestone below corresponds to a public pricing change, product launch, or material adjustment. Major events use a filled marker; minor adjustments use a faded one.
Seven-tier credit ladder with PAYG on upper tiers
ScraperAPI publishes seven public plans (Hobby $49 through Advanced $1,975, plus custom Enterprise) priced on monthly API credits and concurrent threads, with a credit multiplier for JS rendering, premium/ultra-premium proxies, and hard-target domains. The Professional ($975) and Advanced ($1,975) tiers re-surfaced publicly, and pay-as-you-go overage is enabled on Scaling and above.
Traject Data acquisition
ScraperAPI announced its acquisition of Traject Data — the company behind the Rainforest API and SerpWow, with ten real-time SERP and e-commerce data APIs — extending the same API-credit economy across structured search-results and marketplace data.
Scaling tier added at $475
By December 2025 ScraperAPI added a 'Scaling' tier at $475/mo (5,000,000 credits, 200 concurrent threads) positioned as 'Most popular', sitting between Business and Enterprise. The public ladder became Hobby / Startup / Business / Scaling + Enterprise, and a per-feature comparison matrix and DataPipeline product appeared (Wayback 2025-12).
Professional tier pulled from the public page
By mid-2024 the public pricing page showed only Hobby $49 / Startup $149 / Business $299 plus a Custom Enterprise tier — the $999 Professional plan was removed from the self-serve grid and folded into the sales-led path, with a monthly/annual toggle ($44 annual Hobby) made prominent (Wayback 2024-06).
Annual billing 10%-off introduced
By September 2023 the four visible tiers held ($49 / $149 / $299 Business / $999 Professional, plus Enterprise) and ScraperAPI surfaced a 'Save 10% on Yearly Plan' annual-billing discount across plans (Wayback 2023-09). Per-request credit costs and the multiplier model were unchanged.
Repricing + shift from 'API Calls' to credit multiplier
Between the May and August 2022 snapshots ScraperAPI both raised prices and changed its value metric. Hobby moved $29 → $49 and its allotment from 250,000 'API Calls' to 100,000 'API Credits' (20 threads); Startup $99 → $149 (1M credits); Business $249 → $299 (3M credits); and a new Professional tier appeared at $999/mo (14,000,000 credits, 400 threads). Terminology became 'API Credits' + 'Concurrent Threads', and the free option became a 5,000-credit 7-day trial plus a 1,000-page/month forever-free plan — the birth of the difficulty-weighted credit model.
Prices held flat through 2021
Through January 2021 the same $29 / $99 / $249 / Custom ladder and 'API Calls' metering remained in place (Wayback 2021-01), with Business now bundling JS Rendering and residential proxies. The free-call allowance and refund policy were unchanged — roughly two years of price stability on the public tiers.
Original four-tier 'API Calls' pricing
The earliest archived pricing (Wayback 2019-07) shows four tiers metered in flat 'API Calls', not credits: Hobby $29/mo (250,000 calls, 10 concurrent), Startup $99/mo (1,000,000 calls, 25 concurrent), Business $249/mo (3,000,000 calls, 50 concurrent), and custom Enterprise (10,000,000+ calls, 200+ concurrent). The free option was 1,000 free API calls (max 5 concurrent), no card required, with a 7-day refund policy.
- · ScraperAPI prices on a credit multiplier, not flat requests: a plain page costs 1 credit, but JS rendering or premium proxies cost 10, and ultra-premium + render costs 75 credits per request — so a 100,000-credit Hobby plan can be anywhere from 1,333 to 100,000 actual scrapes.
- · Hard-target domains carry fixed multipliers regardless of plan: Amazon is 5 credits, any Google/Bing SERP is 25 credits, and LinkedIn is 30 credits per request.
- · Only the four largest plans (Scaling and up) get pay-as-you-go overage; on Hobby, Startup, and Business, running out of credits forces an upgrade rather than metered overage.
Questions & answers
- How much does ScraperAPI cost?
- ScraperAPI's self-serve plans run from $49/month (Hobby, 100,000 API credits, 20 concurrent threads) to $1,975/month (Advanced, 21,500,000 credits, 500 threads). Annual billing saves 10%, and Enterprise pricing is custom.
- What is an API credit on ScraperAPI?
- An API credit is the unit ScraperAPI meters. A plain request costs 1 credit, but JS rendering or premium proxies cost 10 credits, premium+render costs 25, and ultra-premium+render costs 75 credits per request. Hard-target domains have fixed costs: Amazon 5, Google/Bing SERP 25, LinkedIn 30.
- Does ScraperAPI have a free plan?
- There is no permanent free plan. ScraperAPI offers a 7-day free trial with 5,000 API credits and no credit card required; after that you must pick a paid tier.
- What happens if I run out of API credits?
- On Hobby, Startup, and Business plans you must upgrade to the next plan (or arrange a custom plan) when credits run out. On Scaling, Professional, Advanced, and Enterprise plans you can keep going on a pay-as-you-go model at a fixed per-credit rate.
- What are concurrent threads on ScraperAPI?
- Concurrent threads are the number of simultaneous requests a plan allows, from 20 on Hobby up to 500 on Advanced and Enterprise. They govern throughput independently of your monthly credit budget.