AI Summary
About
DeepInfra is a serverless inference cloud that runs open-weight and hosted AI models on its own GPU fleet and bills customers only for what they consume. Its core promise — stated on the pricing page itself — is “you only pay for what you use… no long-term contracts or upfront costs,” with language models billed per token and most other models billed for inference execution time. The catalog spans hundreds of open models (DeepSeek, Qwen, Llama 3/4, Gemma, Mistral, Nemotron, Phi) alongside hosted closed models (Claude, Gemini), embedding models, Flux image generation, and Voxtral audio transcription, all reachable from one account and one bill.
The company sells to developers, individual builders, and engineering teams that want frontier-model inference without standing up their own GPU infrastructure, and it competes directly with Together AI, Fireworks, Replicate, and RunPod on open-model price and breadth. Founded in 2022 by the team behind the imo messenger (200M+ users), DeepInfra closed a $107M Series B on 2026-05-04 — co-led by 500 Global and Georges Harik, with NVIDIA, Samsung Next, and Supermicro participating — and reports processing roughly five trillion tokens per week, 25× the volume at its Series A. It runs models on H100 and A100 GPUs optimized for inference, with automatic scaling and a default cap of 200 concurrent requests per account.
Beyond the per-token API, DeepInfra layers two heavier compute products on top: on-demand GPU containers (per-GPU-hour A100 through B300 cards, billed by the minute) for custom-model and training workloads, and DeepCluster — a reserved, customer-owned NVIDIA B300 cluster of 256 to 5,000 GPUs that DeepInfra procures, deploys, and operates under three-to-five-year terms. The result is a single vendor spanning the full spectrum from a single API call to a multi-million-dollar dedicated cluster.
Pricing summary : How DeepInfra’s per-token, per-GPU-hour, and reserved-cluster pricing works
DeepInfra runs a pure-usage model with no seats and no base platform fee, metered across four distinct billing dimensions plus a reserved-commitment tier:
- Per-token inference (LLMs + embeddings): Language models are priced per 1M input and output tokens, varying by model — Llama-3.1-8B at $0.02 / $0.03, DeepSeek-V3.1 at $0.25 / $0.95, Claude Opus at $5.00 / $25.00. Many models show a discounted cached-prompt input rate inline. Embeddings run $0.005–$0.01 per 1M input tokens. A per-request Service Tier multiplier sits on top of these rates: the default Standard tier bills at 1× base price, while the Priority tier schedules requests ahead of standard traffic for faster time-to-first-token at 1.5× base price (enabled per request via
service_tier: "priority"). See the broader token-based billing pattern across the corpus. - Per-output-unit media: Flux image generation is priced per image, scaled by resolution and iteration count (e.g. FLUX-2-pro $0.015/image). Voxtral audio transcription is billed per minute of audio input ($0.00100–$0.00300/min).
- Per-GPU-hour containers: On-demand dedicated GPUs bill in minute granularity (invoiced weekly): A100 $0.89, H100 $2.20, H200 $2.69, B200 $3.69, B300 $4.89 per GPU-hour. The GPU-instances product lists 1×B200 $3.69/hr up to 8×B200 $29.52/hr with no egress fees.
- Reserved DeepCluster commitment: Customer-owned B300 clusters (256–5,000 GPUs) at $2.99/GPU-hr (3-year) or $1.98/GPU-hr (5-year), all-in — the only commitment-based tier and the only sales-led surface.
What makes this different: DeepInfra collapses four different metering units (tokens, GPU-hours, images, audio minutes) and a multi-year reserved cluster into one transparent, contract-free account — and on DeepCluster it inverts the cloud model so the customer owns the hardware while DeepInfra operates it.
Pricing by product
Serverless LLM inference (per 1M tokens — representative rows)
| Model | Context | Price (in / out per 1M) | Key mechanics |
|---|---|---|---|
| DeepSeek-V4-Pro | 1024k | $1.30 / $2.60 ($0.10 cached) | Flagship DeepSeek; per-token |
| DeepSeek-V4-Flash | 1024k | $0.09 / $0.18 ($0.018 cached) | Efficiency-focused MoE |
| DeepSeek-V3.1 | 160k | $0.25 / $0.95 ($0.13 cached) | Popular open reasoning model |
| Llama-3.3-70B-Instruct-Turbo | 128k | $0.10 / $0.32 | Turbo throughput tier |
| Meta-Llama-3.1-8B-Instruct-Turbo | 128k | $0.02 / $0.03 | Lowest-cost small model |
| Qwen3-235B-A22B-Instruct-2507 | 256k | $0.09 / $0.55 | Large MoE, low input rate |
| Gemini 2.5 Pro | 976k | $1.25 / $10.00 | Hosted Google model |
| claude-sonnet-4-6 | 976k | $3.00 / $15.00 | Hosted Anthropic model |
| claude-opus-4-8 | 976k | $5.00 / $25.00 | Hosted Anthropic flagship |
Service Tiers (per-request scheduling multiplier)
| Tier | Scheduling | Price | Key mechanics |
|---|---|---|---|
| Standard | Default scheduling, best-effort during peak demand | 1× base price | Applies to every per-token request unless overridden |
| Priority | Scheduled ahead of standard traffic for faster time-to-first-token during peak demand | 1.5× base price | Enable per request via service_tier: "priority"; availability varies by model |
Embeddings, audio & image (other metering units)
| Product | Unit | Price | Key mechanics |
|---|---|---|---|
| Embeddings (bge / gte / e5 family) | per 1M input tokens | $0.005–$0.01 | Per-token, by model |
| Voxtral audio (speech-to-text) | per minute of audio | $0.00100–$0.00300 | Per-minute, Mini vs Small |
| Flux image generation | per image | from $0.0005/image | Scaled by resolution × iterations |
On-demand GPU containers (per GPU-hour)
| GPU | Memory | Price | Key mechanics |
|---|---|---|---|
| A100 | 80GB | $0.89 / GPU-hour | Custom-LLM deploy; minute granularity, invoiced weekly |
| H100 | 80GB | $2.20 / GPU-hour | SXM-connected multi-GPU |
| H200 | 141GB | $2.69 / GPU-hour | Auto-scaling on load |
| B200 | 180GB | $3.69 / GPU-hour | Also on-demand: 8×B200 $29.52/hr, no egress fees |
| B300 | 270GB | $4.89 / GPU-hour | Top single-card rate |
DeepCluster — reserved B300 (sales-led)
| Configuration | Price | Public-cloud reference | Key mechanics |
|---|---|---|---|
| 256–5,000 GPUs · 3-year term | $2.99 / GPU-hr | $6.50 / GPU-hr | 54% cheaper; customer owns hardware |
| 256–5,000 GPUs · 5-year term | $1.98 / GPU-hr | $6.50 / GPU-hr | 70% cheaper; DeepInfra operates it |
Sales motions across products: PLG / self-serve for per-token APIs, on-demand GPU instances, and DeepStart credits; sales-led for DeepCluster and enterprise (contact [email protected]).
Hidden costs : What a real DeepInfra inference bill actually adds up to
DeepInfra’s headline per-token rates look tiny, but production traffic and dedicated GPU uptime are where the bill is built. Two representative archetypes:
A mid-size app on DeepSeek-V3.1 inference
| Line item | Monthly cost |
|---|---|
| 800M input tokens @ $0.25 / 1M | $200 |
| 250M output tokens @ $0.95 / 1M | $238 |
| Embeddings: 200M tokens @ $0.01 / 1M | $2 |
| Total | $440 |
Per-token economics stay cheap at app scale — but note the account would cross into Tier 3 ($500 paid) over a few months, changing the invoicing cadence rather than the rate.
A team renting two B200 GPUs full-time for a custom model
| Line item | Monthly cost |
|---|---|
| 1×B200 @ $3.69/hr × 730 hrs | $2,694 |
| 1×B200 @ $3.69/hr × 730 hrs | $2,694 |
| Total | $5,388 |
Once a workload justifies always-on dedicated GPUs, the bill jumps two orders of magnitude versus per-token calls — the point at which DeepCluster’s $1.98–$2.99/GPU-hr reserved economics start to matter.
Want to estimate your own DeepInfra bill? Use the DeepInfra pricing calculator to model your monthly cost based on token volume, GPU-hours, and reserved-cluster terms.
Pricing evolution : From per-token inference to reserved customer-owned clusters
DeepInfra’s pricing has moved through three distinct eras: a 2023 execution-time model (pay per second of inference), a 2023–2024 shift to per-token language pricing, and a 2025–2026 expansion into multi-unit metering plus reserved capacity. Across that span the headline trend is relentless downward pressure on unit rates — a small-model token cut a developer would feel and a GPU-hour rate that fell roughly 2.5× in eighteen months.
Cadence
| Quarter | Price changes | Product / SKU additions | Notes |
|---|---|---|---|
| 2023 Q1 | 0 | 1 | Launch model: pure execution-time billing — $0.0005/second ($0.03/min) on A100, 1 hour free GPU, $0.04/GB-hr memory reservation. |
| 2023 Q4 | 1 | 1 | 2023-12 per-token LLM pricing introduced (Llama-2-70b $0.70/$0.90 in/out) alongside execution time; marketed “50% less than ChatGPT-3.5 Turbo.” |
| 2024 Q2 | 0 | 2 | 2024-04 Embeddings list ($0.005–$0.01/1M) and Custom-LLM GPU rental added (A100 $2.00, H100 $4.00 /GPU-hr); $1.80 signup credit live. |
| 2024 Q3 | 1 | 1 | 2024-09 Llama-3.1 cuts (8B $0.055, 70B $0.35/$0.40); automatic Usage Tiers ($20–$5,000) and DeepStart program enter the page. |
| 2025 Q1 | 2 | 1 | 2025-02 GPU cut (A100 $1.50, H100 $2.40, H200 added $3.00); LoRA pricing added; $1.80 signup credit removed; Tier 5 raised to $10,000. |
| 2025 Q2 | 0 | 1 | 2025-05 Execution-time pricing block retired (per-token + per-GPU-hour become the core meters); Llama 4 Scout & Maverick launch. |
| 2025 Q3 | 1 | 2 | 2025-08 aggressive GPU cut (A100 $0.89, H100 $1.69, H200 $1.99); per-provider page redesign; 2025-09 Voxtral per-minute audio added. |
| 2025 Q4 | 0 | 2 | 2025-12 inline cached-input rates appear; B200 self-serve GPU row ($2.49/GPU-hr); FLUX.2 image models launch. |
| 2026 Q2 | 1 | 2 | 2026-05 DeepCluster (customer-owned B300, $1.98–$2.99/GPU-hr) launches; B300 self-serve row added ($4.20); $107M Series B closes 2026-05-04. 2026-06 Priority Service Tier (1.5× base price) added; model catalog expands. |
Tracked range: 2023-02–2026-06. Quarters not listed above were verified stable (0 price changes, 0 SKU additions).
Notable changes
- 2023-02 — Earliest archived pricing page bills purely by inference execution time at $0.0005/second with 1 hour free GPU; no per-token rates exist yet (source: Wayback deepinfra.com/pricing 2023-02).
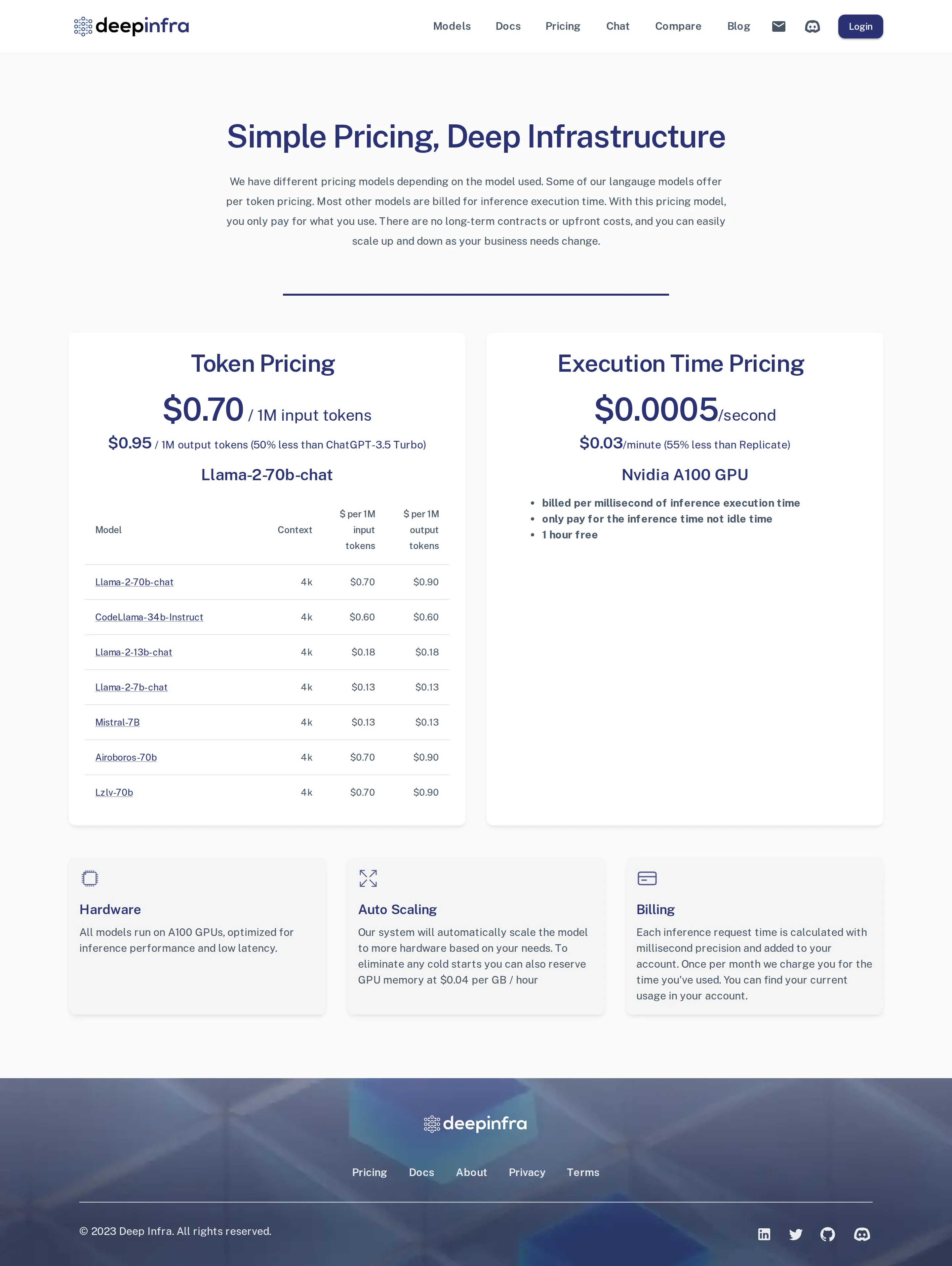
- 2023-12 — Per-token LLM pricing introduced (Llama-2-70b $0.70 in / $0.90 out per 1M), framed as “50% less than ChatGPT-3.5 Turbo” and “55% less than Replicate” on execution time (source: Wayback 2023-12).
- 2024-09 — Llama-3.1 cuts and the first automatic Usage Tiers; DeepStart startup-credit program appears in the nav (source: Wayback 2024-09).
- 2025-05 — Execution-time pricing is retired entirely, simplifying the meter set to per-token + per-GPU-hour (source: Wayback 2025-05).
- 2025-08 — Custom-LLM GPU rates cut about 40% (A100 $1.50→$0.89, H100 $2.40→$1.69, H200 $3.00→$1.99); pricing page redesigned per-provider (source: Wayback 2025-08).
- 2026-05-04 — DeepCluster launches and DeepInfra closes a $107M Series B co-led by 500 Global and Georges Harik, with NVIDIA, Samsung Next, and Supermicro participating; the company reports ~5 trillion tokens/week and 25× token growth since Series A (source: deepinfra.com/series-b).
- 2026-06-30 — A per-request Priority Service Tier appears on the pricing page (1.5× base price for faster time-to-first-token during peak demand, set via
service_tier: "priority"), DeepInfra’s first explicit latency-vs-cost packaging knob; headline rates are otherwise unchanged (source: Wayback deepinfra.com/pricing 2026-06).
The 2025–2026 GPU-rate descent in detail
The custom-LLM GPU rate is the clearest single thread of DeepInfra’s price-cutting reputation. The A100 GPU-hour rate fell from $2.00 (2024-04) to $1.50 (2025-02) to $0.89 (2025-08) — roughly a 2.25× reduction in eighteen months — and the H100 fell even harder, from $4.00 to $1.69 over the same window. These cuts tracked falling wholesale GPU economics and intensifying competition with Together AI, Fireworks, and RunPod, and they reset the per-GPU-hour floor for the whole open-model inference market — a live case study in the token-cost deflation paradox where per-unit prices fall even as total inference spend climbs. The 2026 DeepCluster launch extends the same logic to multi-year buyers: rather than cut the on-demand rate further, DeepInfra offers customer-owned B300 capacity at $1.98/GPU-hr all-in, undercutting its own on-demand B200 ($2.79) for anyone who can commit five years.
What’s unique : Four metering units and a customer-owned reserved cluster on one bill
1. Four metering units under one account. DeepInfra meters tokens (LLMs/embeddings), images (Flux, scaled by resolution × iterations), audio minutes (Voxtral), and GPU-hours (on-demand containers) on the same account — a breadth of billing primitives few inference clouds expose in one transparent price list.
2. Customer-owned reserved hardware. DeepCluster inverts the cloud rental model: the customer owns the NVIDIA B300 hardware (balance-sheet asset, depreciation-eligible) while DeepInfra procures, deploys, and operates it — pricing it all-in per GPU-hour rather than as a lease.
3. Inline cached-prompt rates. Many per-token rows show a discounted cached-input price next to the standard rate, surfacing prompt-cache economics directly in the public price list rather than burying them in docs.
4. A public price-cut track record. DeepInfra’s pricing page is a moving target by design: it has cut GPU-hour rates roughly 2.5× since 2024 and dropped small-model token rates with every model generation, retiring its original per-second execution-time meter entirely along the way. The repeated, visible cuts are themselves a positioning device — the price list signals “we will keep getting cheaper.”
5. A per-request latency-vs-cost knob. As of 2026-06-30 a per-request Service Tier sits on top of the per-token rate: the default Standard tier bills at 1× base price while a Priority tier schedules ahead of standard traffic for faster time-to-first-token at 1.5× base price (set via service_tier: "priority"). It is DeepInfra’s first packaging dimension that is not just “cheaper” — it lets a caller pay up for speed at the request level, turning what was a single transparent price into a two-point quality-of-service ladder without adding a plan, a seat, or a contract.
Strengths & weaknesses
| Strengths | Weaknesses |
|---|---|
| Fully transparent per-model price list, published publicly | No always-free tier — card or pre-pay required to start |
| Four metering units (tokens, images, audio, GPU-hours) on one bill | Per-token rates vary model-by-model, so forecasting requires per-model math |
| Reserved DeepCluster economics down to $1.98/GPU-hr | DeepCluster is sales-led with multi-year terms and no self-serve path |
| No contracts or upfront costs for the usage products | 200 concurrent-request cap by default may throttle high-traffic apps |
| Per-request Priority tier buys faster time-to-first-token (1.5× base) without a plan or contract | The 1.5× Priority multiplier compounds the per-model rate sprawl — a third price point (base / cached / priority) to forecast per model |
Billing UX : Usage tiers, spending limits, and threshold-based invoicing
- Card-on-file or pre-pay requirement — you must add a card or pre-pay before you can use any service; there is no always-free entry path.
- Automatic usage tiers — every account sits in a usage tier (Tier 1 $20, Tier 2 $100, Tier 3 $500, Tier 4 $2,000, Tier 5 $10,000), and DeepInfra moves accounts up automatically as cumulative spend grows.
- Threshold-based invoicing — an invoice generates at the start of each month and again whenever the account hits its tier’s invoicing threshold, so heavier accounts are billed more frequently.
- Spending limit — accounts can set a spending limit “to avoid surprises,” capping run-away usage cost.
- Concurrency cap — each account is limited to 200 concurrent requests by default (raisable on request), a built-in guardrail against unbounded fan-out.
- GPU billing granularity — dedicated GPU containers are billed in minute granularity and invoiced weekly, distinct from the monthly per-token invoicing cycle.
- Per-request Service Tier control — each inference request can be sent at the default Standard tier (1× base price) or the Priority tier (1.5× base price for faster time-to-first-token during peak demand) by setting
service_tier: "priority", letting callers trade cost against latency at the request level.
Strategic wins : Why DeepInfra’s transparent multi-unit pricing works
1. Radical price transparency as a developer-acquisition wedge
By publishing a per-1M-token rate for nearly every open model — including discounted cached-input rates inline — DeepInfra lets a developer estimate cost before signing up, lowering the friction that often gates usage-based pricing adoption. Transparency is itself the marketing, and it scales across hundreds of token-billed models without a sales call.
2. Compounding price cuts as a moat
DeepInfra has cut unit rates repeatedly and publicly — the A100 GPU-hour fell from $2.00 (2024-04) to $0.89 (2025-08), and small-model token rates fell with each generation. Aggressive, legible price-cutting earns word-of-mouth in cost-sensitive communities like r/LocalLLaMA and makes the company the reflexive “cheap inference” reference, a position reinforced by every fresh cut rather than eroded by it — and one that compounds as the trillion-token economy drives ever-larger volumes through the cheapest provider.
3. One account spanning four metering units
Offering tokens, images, audio minutes, and GPU-hours on a single bill captures a customer’s full inference footprint rather than just the LLM slice, increasing account stickiness as workloads diversify. This mirrors the multi-meter direction seen at peers like Replicate but with a more transparent rate card.
4. Customer-owned reserved capacity
DeepCluster’s “you own the hardware, we operate it” framing converts a pure-opex cloud spend into a balance-sheet asset for large buyers — a differentiated commitment-based pitch versus standard reserved-instance leases, and a way to win the largest accounts without discounting the self-serve rate card.
5. Latency as a new pricing axis — raising ARPU without cutting price
The 2026-06-30 Priority Service Tier (1.5× base for faster time-to-first-token) is the first time DeepInfra has monetized quality of service rather than just raw compute. For a vendor whose entire reputation is downward price pressure, this is a strategically important hedge: it opens an upward revenue lane — latency-sensitive workloads (agents, real-time UX) self-select into paying 1.5× — without touching the headline rate that wins cost-sensitive developers. It also rations scarce peak capacity by willingness-to-pay instead of throttling everyone, and it does so with zero packaging overhead: one API flag, no plan, no contract. In a commoditizing market where the floor rate is a race to the bottom, charging for speed is the cleaner margin lever than cutting price further.
Areas to improve : Closing the free-tier and forecasting gaps
1. No self-serve free tier raises the trial barrier
Requiring a card or pre-pay before any usage is a higher bar than peers that offer trial credits. A small always-free monthly token allowance (separate from the gated DeepStart program) would lower first-call friction.
2. Per-model rate sprawl makes forecasting hard
With hundreds of models each carrying its own input/output/cached rate, finance teams struggle to forecast spend. A first-party cost estimator or budget-projection tool tied to the usage tiers would reduce bill-shock risk.
3. DeepCluster has no self-serve on-ramp
The reserved-cluster product is entirely sales-led with multi-year terms, so a team that knows it wants a 256-GPU cluster still has to email [email protected]. A published configurator that quotes indicative GPU-hour pricing for a given GPU count and term — even gated behind a short form — would shorten the path from interest to contract and let buyers self-qualify before sales engages.
Monetization stack & signals : how DeepInfra builds & buys its revenue engine
Buys 1 Builds 2
DeepInfra builds the meter behind its own usage pricing — its first-party Usage API records per-token/per-second units, rates and cost itself — and buys only the invoicing edge (Stripe Invoice IDs, a hosted billing portal). The margin under its relentless public price cuts is defended by in-house inference-cost engineering (Blackwell + NVFP4 → 5¢/M tokens), not by a bought FinOps tool.
-
“DeepInfra's first-party Usage API returns per-model UsageItem records keyed on `units` ("billed seconds or tokens"), `rate` ("rate in cents/sec or cents per token"), `cost` ("model cost in cents") and `pricing_type` — the company meters its own per-token / per-second consumption rather than buying a Metronome/Orb metering layer.”
-
“NVIDIA: "DeepInfra reduced the cost per million tokens from 20 cents on the NVIDIA Hopper platform to 10 cents on Blackwell … further cut that cost to just 5 cents — for a total 4x improvement in cost per token" (on a large MoE model) — cost-per-token engineering DeepInfra does in-house to defend the margin on its publicly-cut rate card.”
Signals reviewed · derived from press & filings, product docs
Key takeaways
- Publish the full price list. DeepInfra’s per-model transparency turns the pricing page itself into a developer-acquisition asset — buyers can model cost before they sign up, the opposite of a gated quote-only motion, and a clean example of the usage-based pricing models playbook.
- Make price cuts a public ritual — then sell speed on top. DeepInfra cut GPU-hour rates ~2.5× in eighteen months and let the market see every step; in a commoditizing category, visible, repeated cuts buy mindshare that a single quiet discount never would. Its 2026 Priority Service Tier (1.5× base for faster time-to-first-token) then opens an upward revenue lane — pricing latency as a separate axis captures willingness-to-pay from real-time workloads without touching the headline rate that wins cost-sensitive buyers.
- One account, many meters. Spanning tokens, images, audio, and GPU-hours on a single bill captures the whole inference footprint instead of just the LLM slice.
- Surface cache economics inline. Showing discounted cached-input rates next to standard rates makes prompt-cache savings legible without docs spelunking — a transparency edge over peers that bury caching in API docs.
- Invert the reserved model when you can. DeepCluster’s customer-owned hardware framing reframes a multi-year commitment as a balance-sheet asset, not just a discount, and protects the self-serve rate card from being undercut by the enterprise deal.
UBP implications
- Multi-unit metering is becoming table stakes for inference clouds — and latency is the next axis. Charging per token, per image, per audio minute, and per GPU-hour on one account shows usage-based pricing fragmenting into product-specific value metrics. DeepInfra’s 2026 Priority tier (1.5× base for faster time-to-first-token) extends that fragmentation to quality-of-service: as token costs deflate, vendors look beyond the per-token rate to speed and priority scheduling as the next premium buyers will pay for.
- Transparency lowers UBP adoption friction. A fully public per-model rate card counters the “unpredictable bill” objection that slows usage-based pricing — visibility is a feature.
- Reserved commitments still anchor the top of a usage funnel. Even a pure-usage vendor needs a commitment tier (DeepCluster) to serve the largest, most cost-sensitive buyers.
Sources
- DeepInfra pricing page (accessed 2026-07-14)
- DeepInfra GPU instances (accessed 2026-07-14)
- DeepInfra DeepCluster (accessed 2026-07-14)
- DeepInfra models directory (accessed 2026-07-14)
- DeepInfra DeepStart startup credits (accessed 2026-07-14)
- DeepInfra contact sales (accessed 2026-07-14)
Bottom line
DeepInfra is one of the most transparent open-model inference clouds in the market: pure-usage per-token APIs that publish a rate for nearly every model, three more metering units (images, audio, GPU-hours) on the same account, and a customer-owned DeepCluster reserved tier from $1.98/GPU-hr for buyers who outgrow on-demand. Its 2026 Priority Service Tier (1.5× base for faster time-to-first-token) adds a latency-vs-cost lever on top of the rate card — the first time it has charged for speed rather than only cutting price. The absence of a self-serve free tier is the main on-ramp gap, but for teams that already know they’ll pay for inference, the price clarity is hard to beat.
Want to compare DeepInfra against other inference-cloud pricing? Browse the pricing blueprint.
Pricing timeline : Major events on a vertical axis
Each milestone below corresponds to a public pricing change, product launch, or material adjustment. Major events use a filled marker; minor adjustments use a faded one.
GPU-hour rates raised; DeepSeek-V3.1 token price up
DeepInfra raises its dedicated GPU-hour rates for the first time in the tracked span: custom-LLM H100 $1.79→$2.20, H200 $2.19→$2.69, B200 $2.79→$3.69, B300 $4.20→$4.89 per GPU-hour (A100 holds at $0.89); on-demand B200 instances move in lockstep (1×B200 $2.79→$3.69/hr, 8×B200 $22.32→$29.52/hr). DeepSeek-V3.1 per-token rises to $0.25 in / $0.95 out (from $0.21 / $0.79) and Llama-3.1-8B-Turbo output drops to $0.03. The model catalog expands (DeepSeek-V4-Flash $0.09/$0.18, gemini-3.x, gemma-4, claude-fable-5 $10/$50, claude-sonnet-5). DeepCluster ($1.98–$2.99/GPU-hr), usage tiers ($20–$10,000), and the Priority service tier (1.5×) are unchanged (source: deepinfra.com/pricing & /gpu-instances 2026-07-14).

Priority Service Tier added (1.5× per-token multiplier)
DeepInfra adds a per-request Service Tier control to the pricing page: the default Standard tier bills at 1× base price, while a new Priority tier schedules requests ahead of standard traffic for faster time-to-first-token at 1.5× base price (set via service_tier: "priority"). Headline per-token, per-GPU-hour, and DeepCluster rates are unchanged; the model catalog expands (DeepSeek-V4-Flash, Gemini 3.x, Gemma 4, Nemotron-3, Claude Haiku/Sonnet/Opus 4.x), and Qwen3-235B-A22B-Instruct-2507 input edges to $0.09 (source: deepinfra.com/pricing 2026-06-30).

Per-token + per-GPU-hour + DeepCluster reserved capacity
Current pricing: per-1M-token LLM rates (DeepSeek-V3.1 $0.21/$0.79, Llama-3.1-8B $0.02/$0.05, Claude Opus $5.00/$25.00), embeddings $0.005–$0.01/1M, Voxtral audio $0.00100–$0.00300/min, Flux per-image, on-demand B200 GPU $2.79/hr, custom-LLM A100 $0.89/H100 $1.79/H200 $2.19/B200 $2.79/B300 $4.20 per GPU-hour, and DeepCluster reserved B300 from $1.98/GPU-hr (5-yr). Usage tiers $20–$10,000 invoicing thresholds.

DeepCluster (customer-owned B300) and $107M Series B
DeepCluster launches: a customer-owned NVIDIA B300 cluster (256–5,000 GPUs, 99.982% uptime SLA) that DeepInfra procures and operates, all-in at $2.99/GPU-hr (3-yr, 54% cheaper than a $6.50 cloud reference) or $1.98/GPU-hr (5-yr, 70% cheaper). DeepInfra closes a $107M Series B on 2026-05-04 (source: Wayback deepcluster 2026-05; deepinfra.com/series-b).
Inline cached-input rates and self-serve B200
Per-token rows begin showing discounted cached-input prices inline (e.g. DeepSeek-V3.1 $0.21 / $0.168 cached). B200 appears as a self-serve custom-LLM GPU row at $2.49/GPU-hour; FLUX.2 image models launch (source: Wayback 2025-12).

Voxtral per-minute audio transcription added
Voxtral speech-to-text models are added as a fourth metering unit, billed per minute of audio input ($0.00100/min Mini, $0.00300/min Small) — joining per-token, per-image, and per-GPU-hour on one bill (source: Wayback 2025-09).

Aggressive GPU price cut and per-provider page redesign
Custom-LLM GPU rates cut hard: A100 $1.50→$0.89, H100 $2.40→$1.69, H200 $3.00→$1.99 per GPU-hour. The pricing page is redesigned into per-provider model sections (DeepSeek, Qwen, Llama 4, Gemma, Phi); "Contact Sales" enters the nav; B200 clusters referenced for dedicated buyers (source: Wayback 2025-08).

Execution-time pricing retired; Llama 4 launched
The per-second "Execution Time Pricing" block disappears from the pricing page, leaving per-token (LLM/embeddings) and per-GPU-hour as the core meters. Llama 4 Scout & Maverick go live; GPU rates hold at A100 $1.50 / H100 $2.40 / H200 $3.00 (source: Wayback 2025-05).
GPU price cut, H200 added, LoRA pricing, signup credit removed
Custom-LLM GPU rates cut: A100 $2.00→$1.50, H100 $4.00→$2.40, H200 added at $3.00/GPU-hr. LoRA-tuned model pricing appears. Llama-3.1-8B cut to $0.03/$0.05; Tier 5 threshold raised to $10,000; the $1.80 signup credit is removed (card or pre-pay now required) (source: Wayback 2025-02).
Llama-3.1 price cuts and automatic Usage Tiers
Llama-3.1 rates fall sharply vs Llama-2: 8B to $0.055/$0.055, 70B to $0.35/$0.40, 405B at $1.79 in. Automatic five-step Usage Tiers appear (Tier 1 $20 → Tier 5 $5,000 threshold) and the DeepStart startup program enters the nav (source: Wayback 2024-09).
Embeddings, custom-LLM GPU rental, and $1.80 signup credit
Page adds an Embeddings price list ($0.005–$0.01 per 1M tokens) and Custom-LLM dedicated-GPU rental (A100 $2.00, H100 $4.00 per GPU-hour, billed by the minute, invoiced weekly). Billing copy notes "$1.80 when you sign up" as starter credit (source: Wayback 2024-04).
Per-token pricing introduced alongside execution time
DeepInfra adds per-token LLM pricing — Llama-2-70b-chat $0.70 in / $0.90 out per 1M, Mistral-7B $0.13/$0.13 — marketed as "50% less than ChatGPT-3.5 Turbo," while execution-time billing ($0.0005/sec, "55% less than Replicate") remains for image/audio models (source: Wayback 2023-12).
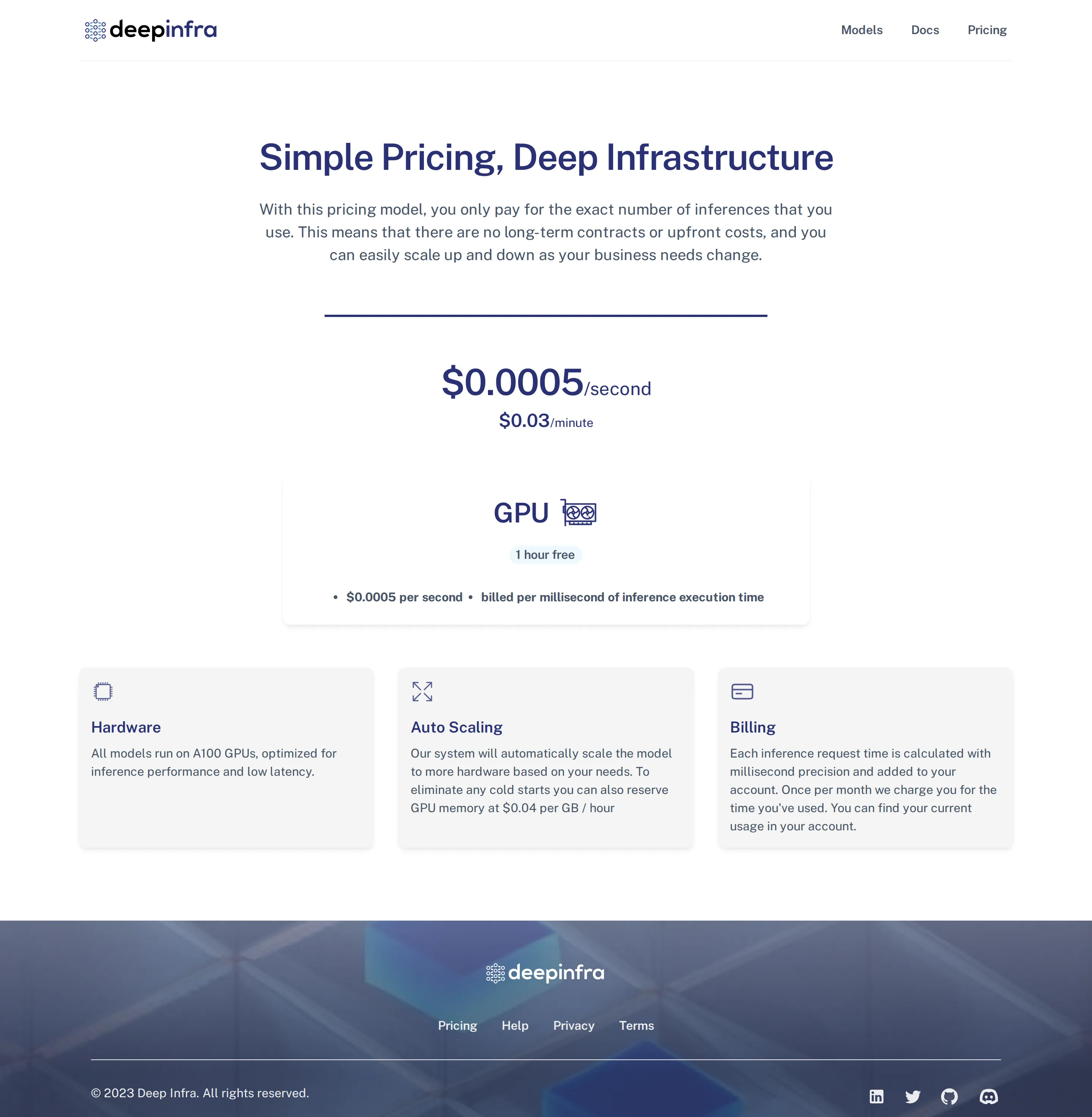
Launch: per-second execution-time billing only
Earliest archived pricing page bills purely by inference execution time — $0.0005/second ($0.03/minute), billed per millisecond on A100 GPUs, with 1 hour of GPU free and reservable GPU memory at $0.04 per GB/hour. No per-token pricing exists yet (source: Wayback deepinfra.com/pricing 2023-02).
- · DeepInfra publishes a per-million-token rate for nearly every open model it hosts — from Llama-3.1-8B at $0.02 in / $0.03 out to flagship DeepSeek-V4-Pro at $1.30 in / $2.60 out — making it one of the most transparent open-model inference price lists in the market, with prompt-cache rates shown inline.
- · The same DeepInfra account spans four billing primitives at once: per-token LLM and embedding APIs, per-image Flux generation priced by resolution and step count, per-minute Voxtral audio transcription, and per-GPU-hour on-demand B200/H200 containers — a single bill across four metering units.
- · DeepInfra raised a $107M Series B to scale its inference cloud, and runs a DeepStart program granting qualifying startups 1,000,000,000 free tokens (valued at DeepSeek-V3.1 prices) for companies that have raised $250K–$10M and were founded within the last two years.
Questions & answers
- How much does DeepInfra cost per token?
- Per-1M-token rates vary by model. Examples: DeepSeek-V3.1 $0.25 in / $0.95 out, DeepSeek-V4-Pro $1.30 / $2.60, Llama-3.3-70B-Turbo $0.10 / $0.32, Llama-3.1-8B $0.02 / $0.03, Claude Sonnet $3.00 / $15.00, Claude Opus $5.00 / $25.00, Gemini 2.5 Pro $1.25 / $10.00. Many models also show a discounted cached-prompt input rate inline. These are the default Standard-tier (1×) rates; sending a request at the Priority service tier bills 1.5× the base per-token price for faster time-to-first-token.
- Does DeepInfra charge per GPU-hour for dedicated hardware?
- Yes. Custom-LLM deployments on dedicated GPUs bill in minute granularity (invoiced weekly): A100 $0.89, H100 $2.20, H200 $2.69, B200 $3.69, B300 $4.89 per GPU-hour. The on-demand GPU-instances product lists 1×B200 $3.69/hr, 2×B200 $7.38/hr, 4×B200 $14.76/hr, 8×B200 $29.52/hr with no egress fees.
- What is DeepInfra DeepCluster pricing?
- DeepCluster is a reserved, customer-owned NVIDIA B300 GPU cluster (256–5,000 GPUs) that DeepInfra procures and operates. All-in pricing is $2.99/GPU-hr on a 3-year term and $1.98/GPU-hr on a 5-year term, marketed as up to 54%–70% cheaper than a $6.50/GPU-hr public-cloud reference. Terms are 3 to 5 years and are sales-led (contact [email protected]).
- Does DeepInfra have a free tier?
- No published free tier — a card on file or pre-payment is required before you can use the service. However, the DeepStart program grants qualifying startups 1,000,000,000 free tokens (valued at DeepSeek-V3.1 prices) for companies that raised $250K–$10M and were founded within the last 2 years.
- How does DeepInfra billing work?
- DeepInfra bills pay-as-you-go with no contracts or upfront costs. Every account sits in a usage tier (Tier 1 $20 threshold up to Tier 5 $10,000); an invoice generates at the start of each month and whenever the tier's invoicing threshold is reached. You can set a spending limit, and accounts are capped at 200 concurrent requests by default.
- How are DeepInfra image and audio models priced?
- Image and audio models are billed per output unit rather than per token. Flux image generation is priced per image scaled by resolution and iteration count (e.g. FLUX-1-schnell $0.0005 × (w/1024) × (h/1024) × iters; FLUX-2-pro $0.015/image). Voxtral audio transcription is billed per minute of audio input ($0.00100/min Mini, $0.00300/min Small).