AI Summary
About
Novita AI is a pay-as-you-go AI cloud that bundles three products under a single API: serverless model inference across 200+ open models, GPU compute (on-demand, spot, and bare-metal), and a per-second Agent Sandbox runtime for executing AI-generated code, browser workflows, and computer-use tasks. Its positioning line — “200+ models, on-demand GPUs, and secure agent runtimes — unified under one API. Free to start, scales as you grow” — captures the strategy: be the cheapest, broadest place for developers to run open-weight models and the GPUs underneath them.
The company competes with inference aggregators (Together AI, Fireworks, DeepInfra, Replicate) on the model-API side and with GPU clouds (RunPod, Lambda, Vast.ai) on the compute side. Its differentiator is doing both at once and undercutting first-party model APIs: DeepSeek, Qwen, GLM, Kimi, MiniMax, and Llama families are all listed at aggressive per-million-token rates, frequently with cache-read discounts. Novita serves individual developers and prosumers (self-serve, free to start) up through SMBs and enterprises (dedicated endpoints, bare-metal clusters, and a contact-sales Enterprise sandbox tier with a 99.95% SLA).
Pricing transparency is a notable strength: nearly every dimension — token rates for 226 models, per-image and per-video-second media rates, on-demand and spot GPU hourly rates, and per-second sandbox examples — is published openly, with “contact sales” reserved for bare-metal nodes beyond H100/B200 and the Enterprise sandbox tier.
Novita’s archived pricing pages show it started life around 2023–2024 as a credit-funded Stable-Diffusion image-generation API (footer HQ in Singapore), then pivoted through 2025 into a full inference-plus-GPU cloud and relisted its HQ in San Francisco — see Pricing evolution. Public funding is undisclosed (Crunchbase and Tracxn list no disclosed rounds), and community signal is modest rather than viral: the company has no Hacker News thread above single digits and surfaces mostly in r/LocalLLaMA model-availability chatter, so its growth has been distribution-led (cheap open-model inference) rather than launch-hype-led.
Pricing summary : How Novita AI’s pure usage-based AI cloud bills
Novita AI uses a pure usage-based model — free to start, no seats, no monthly minimum — billed across four metering dimensions:
- Per-token model inference (serverless): LLMs are billed per million tokens, split input/output, e.g. Llama 3.1 8B at $0.02/M in · $0.05/M out, DeepSeek V3.1 at $0.27/M in · $1/M out, and DeepSeek V4 Pro at $1.6/M in · $3.2/M out, with cache-read rates (often ~50% of input) on many models. Image generation is per image (from $0.001/image), video per video or per second (e.g. $0.30/video Hunyuan Video Fast), and audio per 1M characters ($15/1M characters Fish Audio TTS).
- Per-hour GPU instances: On-demand RTX-class instances from 0.33/hr/GPU (RTX 4090 24GB) to 0.77/hr/GPU (RTX 6000 Ada 48GB), with spot pricing at roughly half (RTX 4090 0.33 on-demand vs 0.17 spot) — prices shown as Novita renders them, in USD with no
$glyph. Billed per second, scale to zero. (H100 capacity moved to dedicated endpoints and bare-metal nodes.) - Per-GPU-hour dedicated endpoints + bare metal: Isolated dedicated endpoints at $0.61 (RTX 4090) / $1.99 (H100) / $2.99 (H200) per GPU-hour; bare-metal 8-GPU nodes at $1.70/GPU/hr (H100 SXM) and $4.77/GPU/hr (B200 SXM).
- Per-second agent sandbox: Billed on allocated vCPU + memory, e.g. ~$0.0034 for a 5-minute task on 1 vCPU + 512 MiB RAM.
What makes this different: Novita prices the same physical GPU three ways depending on packaging (shared-serverless token rates, on-demand hourly instances, and reserved bare-metal per-GPU-hour), letting a customer move down the cost curve as commitment rises — without ever signing an annual contract.
Pricing by product
Serverless model inference (per-token LLMs)
| Model | Context | Input | Output | Key mechanics |
|---|---|---|---|---|
| Llama 3.1 8B Instruct | 16,384 | $0.02 /M | $0.05 /M | Cheapest flagship-class LLM listed |
| Llama 3.3 70B Instruct | 131,072 | $0.135 /M | $0.4 /M | Popular mid-size open model |
| DeepSeek V3.1 | 131,072 | $0.27 /M | $1 /M | Cache read $0.135/M |
| DeepSeek V4 Pro | 1,048,576 | $1.6 /M | $3.2 /M | Flagship; cache read $0.135/M |
| DeepSeek V4 Flash | 1,048,576 | $0.14 /M | $0.28 /M | Low-cost long-context; cache read $0.028/M |
| Qwen3.7-Max | 1,000,000 | $1.25 /M | $3.75 /M | Cache read $0.25/M |
| GLM-5.1 | 204,800 | $1.38 /M | $4.4 /M | Cache read $0.26/M |
| Kimi K2.6 | 262,144 | $0.8 /M | $3.4 /M | Cache read $0.16/M |
| MiniMax-M2 | 204,800 | $0.3 /M | $1.2 /M | Cache read $0.03/M |
| OpenAI GPT OSS 120B | 131,072 | $0.05 /M | $0.25 /M | Open-weight GPT OSS |
Catalog lists 226 models across LLM, Image, Audio, Video, Embedding, Reranker, and Vision. Some models (Qwen3 Max, MiniMax-M3, MiMo-V2.5-Pro) show “Tiered pricing” instead of a flat rate. Batch inference carries an introductory 50% discount on input/output tokens for supported models.
Serverless media inference (per-image / per-video / per-character)
| Modality | Example API | Price | Key mechanics |
|---|---|---|---|
| Image | Text to Image (512×512, 5 steps) | $0.001 /image | Scales with dimensions, steps, upscaling |
| Image | Flux.1 Kontext Pro | $0.036 /image | Premium editing model |
| Image | Hunyuan Image 3 | $0.1 /image | High-end generation |
| Video | Hunyuan Video Fast (5s, 720p) | $0.30 /video | Per finished video |
| Video | Kling 2.5 Turbo (5s) | $0.35 /video | $0.70 for 10s |
| Video | Kling v3.0 Pro (per second) | $0.112–$0.168 /s | Audio variant is the higher rate |
| Audio | Fish Audio Text to Speech | $15 /1M characters | Per-character TTS |
| Audio | MiniMax speech-2.6-hd | $100 /1M characters | Premium HD voice |
| Audio | MiniMax Voice-Cloning | $1.5 /voice | Per cloned voice |
GPU instances (on-demand vs spot, per hour)
| GPU | VRAM | On-Demand | Spot | Key mechanics |
|---|---|---|---|---|
| RTX 4090 24GB | 24 GB | 0.33 /hr/GPU | 0.17 /hr/GPU | Cheapest on-demand instance; spot ~48% off |
| RTX 4090 24GB (High frequency) | 24 GB | 0.69 /hr/GPU | 0.35 /hr/GPU | Higher-clock variant |
| RTX 5090 32GB (High frequency) | 32 GB | 0.72 /hr/GPU | 0.36 /hr/GPU | Latest Blackwell consumer GPU |
| RTX 6000 Ada 48GB | 48 GB | 0.77 /hr/GPU | 0.39 /hr/GPU | Most VRAM in the instance lineup |
GPU instance rates above are shown exactly as Novita renders them on /en/gpus (USD per GPU per hour, no $ glyph on the source page). As of the 2026-06 capture the self-serve instance lineup is RTX-class only — L40S and H100 SXM instances are no longer listed there; H100 capacity is now sold via dedicated endpoints ($1.99/GPU-hr) and bare-metal nodes ($1.70/GPU/hr).
Dedicated endpoints (isolated GPUs, per GPU-hour)
| GPU | VRAM | Price / GPU-hour | Key mechanics |
|---|---|---|---|
| RTX 4090 | 24 GB | $0.61 | Per-second billing on running replicas |
| RTX-5090 | 32 GB | $0.73 | Newest Blackwell consumer GPU as an endpoint |
| NVIDIA H100 | 80 GB | $1.99 | Guaranteed performance, no sharing |
| NVIDIA H200 | 141 GB | $2.99 | Marked “Popular”; autoscaling + scale-to-zero |
Dedicated image endpoints are sold as monthly subscriptions: Standard $559/month and Pro $1,199/month (both: exclusive high-performance GPU, unlimited images, 24/7 support, load 500 models), via contact sales.
Bare-metal GPU servers (8 GPUs per node, per GPU/hr)
| GPU | Config | Price / GPU/hr | Key mechanics |
|---|---|---|---|
| H100 SXM | 8× per node, 80 GB HBM3 | $1.70 | ”Best value”; NVLink 900 GB/s + RDMA |
| B200 SXM | 8× per node, 192 GB HBM3e | $4.77 | ”Top performance”; NVLink 5th-gen 1.8 TB/s |
| H200 SXM | 8× per node, 141 GB HBM3e | Custom | Large-context / KV-cache workloads; contact us |
| RTX 5090 | 8× per node, 32 GB GDDR7 | Custom | Cost-efficient inference; contact us |
| RTX 4090 | 8× per node, 24 GB GDDR6X | Custom | Broadest software compatibility; contact us |
Agent Sandbox (per-second on vCPU + memory)
Novita now publishes the underlying per-unit sandbox rate card (previously only example costs were shown):
| Billing basis | Unit price | Key mechanics |
|---|---|---|
| vCPU | $0.0000098 / vCPU-second | Calculated per allocated vCPU-second |
| Memory | $0.0000032 / GiB-second | Calculated per allocated GiB-second |
| Storage | $0.00009 / GB-hour | Measured hourly, charged daily; first 60 GB included |
| Configuration | Workload example | Estimated cost | Key mechanics |
|---|---|---|---|
| 1 vCPU + 512 MiB RAM | Short-lived agent task (5 min) | ~$0.0034 | Billed per second |
| 2 vCPU + 1 GiB RAM | Code execution job (1 hr) | ~$0.0821 | No plans, no lock-ins |
| 8 vCPU + 8 GiB RAM | Multi-agent / RL workload (1 hr) | ~$0.3744 | Sub-200ms startup |
| Enterprise | Higher limits, custom regions | Custom (contact sales) | 99.95% uptime SLA; unlimited concurrency |
New sandbox users get $100 in free credits (valid 90 days, no card required). The free tier allows 5 concurrent sandboxes, 1-hour max sessions, and 2 vCPU / 4 GB RAM per sandbox; topping the balance above $0 auto-unlocks the paid tier (100 concurrent, 24-hour sessions, up to 8 vCPU / 8 GB RAM).
Sales motions across products: PLG / self-serve for serverless inference, GPU instances, dedicated endpoints, and standard sandbox usage; sales-led for bare-metal nodes beyond H100/B200, image endpoint subscriptions, and the Enterprise sandbox tier.
Hidden costs : What inference + GPU bills actually look like at volume
The “free to start” headline hides how quickly a production workload can compound across token, GPU, and sandbox dimensions. Two representative archetypes:
A startup running a DeepSeek-V3.1 chat product
| Line item | Monthly cost |
|---|---|
| 300M input tokens @ $0.27/M | $81 |
| 120M output tokens @ $1/M | $120 |
| 50M cache-read tokens @ $0.135/M | $6.75 |
| 1× dedicated H100 endpoint, ~200 hrs active @ $1.99/GPU-hr | $398 |
| Total | ~$605.75 |
The dedicated endpoint — not the tokens — dominates the bill once you reserve isolated capacity, so teams must weigh shared serverless token rates against the latency guarantees of a dedicated GPU.
An agent platform running browser + code sandboxes
| Line item | Monthly cost |
|---|---|
| 50,000 short coding tasks @ ~$0.0034 (1 vCPU/512MiB, 5 min) | $170 |
| 5,000 hour-long multi-agent jobs @ ~$0.3744 (8 vCPU/8GiB) | $1,872 |
| Spot RTX 4090 for model serving, ~300 hrs @ $0.18/hr | $54 |
| Total | ~$2,096 |
Per-second sandbox pricing looks trivial per task, but at agent-platform concurrency the long-running 8-vCPU jobs are the cost driver — exactly the line a usage-based pricing buyer should model before committing.
Want to estimate your own Novita AI bill? Use the Novita AI pricing calculator to model your monthly cost based on token volume, GPU hours, and sandbox seconds.
Pricing evolution : From a credit-funded image API to a full AI cloud stack
Novita’s archived pricing pages tell a clean origin story: it started in 2023–2024 as a Stable-Diffusion image-generation API billed out of a prepaid credit balance (USDT/Stripe top-ups, “1/10 of DALL-E2 and MJ”), then pivoted through 2025 into a broad model-inference + GPU cloud, adding LLMs, Audio, GPUs, Dedicated Endpoints, and finally a per-second Agent Sandbox — moving its listed HQ from Singapore to San Francisco along the way.
Cadence
| Quarter | Price changes | Product / SKU additions | Notes |
|---|---|---|---|
| 2024 Q1 | 0 (baseline) | 0 | Credit-funded image API; text-to-image $0.0015/image (512×512), upscale from $0.0021/image; Singapore HQ. |
| 2024 Q2 | 0 | 2 | LLM API and Audio (Text to Speech, Voice Cloning) added to the catalog; image rates unchanged. |
| 2025 Q1 | 1 | 1 | Redesign to “Model APIs / GPUs” tabs; HQ moves to San Francisco; $10,000 startup-credits program; image shown at $0.003/image (1024×1024); Hunyuan/Wan video rates listed per-second. |
| 2025 Q3 | 1 | 1 | Agent Sandbox launches; page splits into Serverless / Dedicated / GPUs / Sandbox tabs; image back to $0.001/image (512×512); full LLM rate card published (DeepSeek V3.1 $0.27/$1, Llama 3.1 8B $0.02/$0.05). |
| 2025 Q4 | 1 | 1 | GLM-4.6, Kimi K2 and DeepSeek V3.2 Exp added; V3.2 Exp output cut to $0.41/M vs V3.1’s $1/M. |
| 2026 Q2 | 1 | 1 | GPU-instance repricing: RTX 4090 on-demand cut to $0.35/hr (from $0.67), spot to $0.18 (from $0.34); lineup narrowed to RTX-class (L40S + H100 instances removed); RTX 6000 Ada added. RTX-5090 dedicated endpoint ($0.73) added; Agent Sandbox per-unit rate card published + $100 / 90-day free credits. |
Tracked range: 2024-02-25 → 2026-06-24 via Wayback + live capture. Quarters not listed (2024 Q3–Q4, 2025 Q2, 2026 Q1) showed no material pricing or packaging change in the archived snapshots reviewed.
Notable changes
- 2024-02-25 — Earliest archived surface: a credit-funded image-generation API (txt2img $0.0015/image, USDT/Stripe top-ups), tagline “1/10 of DALL-E2 and MJ,” Singapore HQ.
- 2024-05-21 — LLM API and Audio (TTS, Voice Cloning) added to the product catalog.
- 2025-02-10 — Major redesign to Model APIs + GPUs tabs; listed HQ moves to San Francisco; $10,000 startup-credits program launches.
- 2025-08-04 — Agent Sandbox launches; pricing splits into four endpoint tabs; batch inference advertised at an introductory 50% token discount.
- 2025-09-11 — Full serverless LLM rate card published (DeepSeek V3.1 $0.27/$1, Llama 3.1 8B $0.02/$0.05, GLM-4.5 $0.6/$2.2), with several small models listed Free.
- 2025-10-03 — GLM-4.6, Kimi K2, DeepSeek V3.2 Exp added; DeepSeek V3.2 Exp output token cut to $0.41/M.
- 2026-04-21 — Per the Novita blog, Kimi K2.6 launched at $0.95/$4.00 per M tokens; by the 2026-06-02 capture the same family is listed at $0.8/$3.4 — a downward revision within ~6 weeks, consistent with Novita’s habit of trimming rates after launch.
- 2026-06-24 — GPU-instance repricing and lineup change (live capture): RTX 4090 on-demand drops to $0.35/hr ($0.18 spot) from $0.67/$0.34; the
/en/gpuspage is narrowed to RTX-class GPUs (RTX 4090, RTX 4090 HF, RTX 5090 HF, new RTX 6000 Ada 48GB at $0.77), with L40S and H100 SXM instances removed — H100 now sold only via dedicated endpoints ($1.99/GPU-hr) and bare-metal ($1.70/GPU/hr). Dedicated endpoints add RTX-5090 at $0.73/GPU-hr, and the Agent Sandbox begins publishing its per-unit rate card ($0.0000098/vCPU-second, $0.0000032/GiB-second, $0.00009/GB-hour, first 60 GB free) alongside a $100 / 90-day free-credit offer.
The model-API pivot in detail
The most consequential change is not a single price move but a product-category pivot. In early 2024 Novita’s entire pricing page was image-generation APIs billed from a prepaid credit wallet — the same packaging a hobbyist Stable-Diffusion service would use. By late 2025 the page had become a four-tab AI-cloud rate card spanning per-token LLM inference, per-hour GPUs, per-GPU-hour dedicated endpoints, and per-second agent sandboxes. The credit-wallet UX was replaced by pure pay-as-you-go metering, and the headline shifted from “cheaper than DALL-E” to “200+ models under one API.” Novita rode the open-weight model wave — DeepSeek, Qwen, GLM, Kimi — from a niche media tool into a general-purpose inference cloud in under two years.
What’s unique : One GPU, multiple prices, zero contracts
1. The same GPU is sold at multiple price points by packaging. An NVIDIA H100 is $1.99/GPU-hr as a dedicated inference endpoint and $1.70/GPU/hr on an 8-GPU bare-metal node; an RTX 4090 is $0.35/hr as an on-demand instance, $0.18/hr spot, and $0.61/GPU-hr as a dedicated endpoint. Customers self-select down the cost curve as their commitment and isolation needs rise — with no annual contract required at any step. As of the 2026-06-24 repricing the ladder has split by GPU class: the laddered self-serve product is now the RTX 4090 (instance → spot → dedicated), while data-center H100/H200 capacity is reachable only through dedicated endpoints and bare-metal — Novita pulled L40S and H100 off the self-serve instance page entirely.
2. Four metering dimensions under one API. Tokens, GPU hours, GPU-hours-per-replica, and sandbox vCPU-seconds are all billed independently, so a single customer can mix shared inference, reserved compute, and ephemeral agent runtimes on one account and one invoice.
3. Per-second billing reaches all the way to agent sandboxes. Most inference clouds stop at per-hour GPU billing; Novita extends pure-usage granularity to per-second vCPU+memory for agent execution, quoting a 5-minute task at fractions of a cent.
4. Aggressive undercutting of first-party model APIs. With 226 models and cache-read discounts (~50% of input on many), Novita positions as the cheap default for open-weight DeepSeek, Qwen, GLM, Kimi, and Llama inference rather than going to each model maker directly — leaning into the token-cost deflation that keeps compressing per-million-token rates.
Strengths & weaknesses
| Strengths | Weaknesses |
|---|---|
| Radical price transparency — 226 model rates + GPU + sandbox examples all public | Pricing surface is sprawling; comparing the “same” GPU across products is confusing |
| Pure usage, free to start, no monthly minimum or seat fees | Some flagship models show only “Tiered pricing” with no public rate |
| Spot GPUs at ~50% of on-demand, and a deep self-serve repricing (RTX 4090 on-demand cut ~48% to $0.35/hr on 2026-06-24) keep the entry rung aggressively cheap | No committed-use discounts or annual commit tier published |
| Per-second granularity down to agent sandboxes, now with a published per-unit rate card + $100/90-day starter credits | Bare-metal beyond H100/B200 and Enterprise sandbox are contact-sales only; self-serve GPU instances narrowed to RTX-class only (no L40S/H100 on-demand after 2026-06-24) |
| One API + one invoice across inference, GPUs, and agent runtimes | No public uptime SLA except the Enterprise sandbox tier (99.95%) |
| Rapid catalog refresh — new flagship models added within days of release (DeepSeek V4, Kimi K2.6, GLM-4.7) | Undisclosed funding and thin public/community signal (no HN thread above single-digit points) make durability harder to assess |
Billing UX : Tabbed pricing surface, spot toggle, and sandbox estimator
- Tabbed pricing page — the
/en/pricingsurface splits into Serverless Endpoints, Dedicated Endpoints, Agent Sandbox, and GPUs tabs, each rendering its own rate tables. - Modality filters on serverless rates — LLM / Image / Audio / Video / Cache filters let users narrow the 226-model rate table to a single modality.
- On-Demand vs Spot toggle — the GPU Instance page shows on-demand and spot rates side by side per GPU, surfacing the ~50% spot saving.
- Pricing Calculator links — image and video rate tables explicitly point to a Pricing Calculator for dimension-dependent estimates (“varies based on image dimensions, inference steps, and upscaling”).
- Sandbox rate card + cost estimator — the Agent Sandbox page now publishes the per-unit billing basis ($0.0000098/vCPU-second, $0.0000032/GiB-second, $0.00009/GB-hour with the first 60 GB included) alongside sample configurations with workload examples and estimated per-task costs (e.g. ~$0.0034 / ~$0.0821 / ~$0.3744), plus a $100 / 90-day free-credit start.
- Scale-to-zero controls — dedicated endpoints advertise “per-second billing on running replicas only. Scale to zero, pay zero.”
Strategic wins : Why Novita’s packaging decisions work
1. Bundling inference and GPUs captures the whole workload
By selling both the model API and the GPU underneath it, Novita captures customers at whichever layer they prefer to operate — and can route them up or down the stack as needs change. This is the same full-funnel logic that makes hybrid platforms sticky, applied to pure usage.
2. GPU laddering by class monetizes commitment without contracts
Offering the same GPU at instance, dedicated, and bare-metal prices lets customers trade flexibility for cost on their own terms. The 2026-06-24 repricing sharpened that ladder along GPU class rather than blurring it: the RTX 4090 now carries the full self-serve rung (on-demand $0.35 → spot $0.18 → dedicated $0.61), while H100/H200 data-center capacity is sold only as dedicated endpoints or bare-metal. By cutting the RTX 4090 on-demand rate ~48% and pulling H100 off the self-serve instance page, Novita keeps a deliberately cheap on-ramp for prosumers while routing serious-capacity buyers straight to the reserved products — earning more from each segment without an annual commitment.
3. Per-second sandbox pricing lands the agent wave early
Pricing agent execution per vCPU-second positions Novita squarely in front of the 2026 surge in coding agents, browser automation, and RL environments — a use case many GPU clouds price too coarsely to win, even as agentic workflows become a cost monster for buyers who don’t meter them tightly. The 2026-06-24 move doubled down here: the sandbox went from publishing only illustrative task costs to a full per-unit rate card ($0.0000098/vCPU-second, $0.0000032/GiB-second, $0.00009/GB-hour, first 60 GB free), and paired it with a $100 / 90-day no-card free-credit offer — a transparency-plus-acquisition play aimed at winning agent builders before they standardize on a competing runtime.
Areas to improve : Where the pricing surface creates friction
1. Consolidate the “same GPU, multiple prices” confusion — now worse after the lineup split
A buyer comparing H100 options sees $1.99 (dedicated endpoint) and $1.70 (bare-metal) across separate pages — and after 2026-06-24 the self-serve instance page no longer even lists H100, only RTX-class GPUs — with no single comparison view. The lineup split actually raises the navigation burden: a buyer who lands on /en/gpus expecting a datacenter GPU now has to discover that H100/H200 live on entirely different products. A unified “choose your GPU packaging” matrix — which class is available as instance vs dedicated vs bare-metal, with break-even hours — would convert better than forcing the buyer to reconcile separate tabs, and would blunt the bill-shock and cost-unpredictability risk that scares finance teams away from raw usage pricing.
2. Publish rates for “Tiered pricing” models
Flagship models like Qwen3 Max and MiniMax-M3 show only “Tiered pricing” with no number, undercutting the otherwise-excellent transparency. Even a starting rate or a published tier table would remove a sales-friction point for the most in-demand models.
3. Offer a committed-use discount tier
Novita has no public annual-commit or reserved-capacity discount outside bare-metal. A self-serve committed-use option (prepay credits for a discount) would give predictable workloads a reason to consolidate spend on Novita, echoing how credit-pool models reward commitment.
Monetization stack & signals : how Novita AI builds & buys its revenue engine
2 signal roles
No monetization vendor is sourceable — the read is the GTM build-out below. Novita's first quota-carrying AE, paired with a presales Solutions Engineer, layers an enterprise sales-led motion onto its self-serve, public-rate-card inference cloud.
- Account Executive Deal desk seen Apr 1, 2026
Novita's first dedicated quota-carrying sales hire — a full-cycle AE closing CTO/VP-Eng deals — layers an enterprise sales-led motion onto its self-serve, published-rate-card core. The deal desk and negotiated contracts this implies sit alongside, not instead of, the public per-token/per-GPU-hour metering.
“Own the entire sales process from prospecting and lead generation to negotiation and closing. Conduct deep-dive discovery calls with technical buyers (CTOs, VP of Engineering, Lead AI Scientists).”
- Solutions Engineer (AI Cloud Infrastructure) Customer success seen Aug 27, 2025
A presales SE paired with the AE confirms the enterprise GTM build-out: POC-led technical selling of GPU/inference workloads, with the SE owning post-sale onboarding. The pairing is the canonical two-role enterprise motion bolted onto a PLG inference cloud.
“Partner with Account Executives to deeply understand customer needs... Design, manage, and execute successful POCs, proving the value and performance of our platform... provide initial onboarding support and architectural guidance.”
Signals reviewed · derived from public job posts
Job postings fill and close over time — once a posting is filled we keep it as a dated citation (the quoted evidence remains); use View open roles for current listings.
Key takeaways
- Sell the same resource at multiple price points by packaging — and segment the ladder by tier. Novita’s instance/dedicated/bare-metal ladder (now run on the RTX 4090, with H100/H200 reserved for dedicated and bare-metal only) shows how to monetize commitment without contracts, and how trimming a self-serve lineup can steer high-end demand toward higher-commitment products.
- Transparency is a competitive weapon in usage-based markets. Publishing 226 model rates plus GPU and sandbox examples lets developers self-qualify and reduces sales friction versus gated competitors.
- Extend metering granularity to match the workload. Per-second sandbox billing fits agent execution far better than per-hour GPU billing — the unit should mirror how the customer actually consumes.
- Cache-read discounts reshape effective token cost. Listing cache-read rates (~50% of input) on many models materially changes real bills and should be modeled, not ignored.
- “Free to start” still needs a cost model. The headline hides four compounding dimensions; the buyers who win are the ones who model token, GPU, and sandbox spend together before scaling.
UBP implications
- Multi-dimensional metering is becoming table stakes for AI clouds. Novita bills on tokens, GPU hours, replica-hours, and vCPU-seconds simultaneously — a sign that single-metric usage pricing is insufficient for stacked AI infrastructure.
- Packaging, not just price, is the lever — and which SKUs you withdraw is part of it. The same silicon at multiple prices proves that how usage is packaged (shared vs dedicated vs reserved) is itself a pricing dimension; Novita’s 2026-06-24 move to pull H100 off self-serve while cutting the RTX 4090 ~48% shows that removing a packaging option can be as deliberate a lever as adding one.
- Per-second billing is the new frontier for agent economies. As AI agents proliferate, the vendors that meter execution at second-level granularity will out-price those still selling hourly compute blocks.
Sources
- Novita AI pricing page (accessed 2026-07-06)
- Novita AI GPU Instance pricing (accessed 2026-07-06)
- Novita AI Bare Metal GPU servers (accessed 2026-07-06)
- Novita AI Agent Sandbox (accessed 2026-07-06)
- Novita AI model catalog (accessed 2026-07-06)
- Novita AI LLM API product page (accessed 2026-06-02)
- Novita AI Dedicated Endpoints product page (accessed 2026-06-02)
Bottom line
Novita AI is one of the most transparent pure-usage AI clouds in the corpus: 226 model rates, on-demand and spot GPUs, bare-metal nodes, and per-second agent sandboxes (now with a published per-unit rate card) are all open, with GPUs laddered across price points by packaging so customers buy exactly the commitment they want. The 2026-06-24 repricing sharpened that ladder by class — a deeply cut RTX-class self-serve on-ramp (RTX 4090 on-demand ~48% cheaper at $0.35/hr) with H100/H200 reserved for dedicated and bare-metal — while widening the navigation gap a buyer must cross to compare options. The cost of all this breadth remains a sprawling, multi-tab pricing surface that asks buyers to reconcile token, GPU, and sandbox math themselves — a transparency-versus-clarity trade-off worth watching.
Want to compare Novita AI against other AI-infrastructure pricing? Browse the pricing blueprint.
Pricing timeline : Major events on a vertical axis
Each milestone below corresponds to a public pricing change, product launch, or material adjustment. Major events use a filled marker; minor adjustments use a faded one.
Base RTX 4090 instance trimmed; catalog refresh
Self-serve RTX 4090 24GB instance nudged down to $0.33/hr on-demand ($0.17 spot) from $0.35/$0.18; RTX 4090 HF ($0.69/$0.35), RTX 5090 HF ($0.72/$0.36) and RTX 6000 Ada ($0.77/$0.39) held. Serverless catalog refreshed with new flagships (GLM 5.2 $1.4/$4.4, GLM-4.7 $0.6/$2.2, Kimi K2.7 Code $0.95/$4, MiniMax M2.7/M2.5) while referenced SKUs (DeepSeek V3.1/V4 Pro, Llama 3.1 8B, Qwen3.7-Max, GLM-5.1, Kimi K2.6, GPT OSS 120B) held rates. Dedicated endpoints, bare-metal, and Agent Sandbox rate cards unchanged.
GPU-instance repricing + published sandbox rate card
Self-serve GPU instances (/en/gpus) cut and re-lined-up to RTX-class only: RTX 4090 24GB drops to $0.35/hr on-demand ($0.18 spot) from $0.67/$0.34, with RTX 4090 HF $0.69, RTX 5090 HF $0.72, and a new RTX 6000 Ada 48GB at $0.77 — L40S and H100 SXM instances removed (H100 now sold via dedicated endpoints $1.99/GPU-hr and bare-metal $1.70/GPU/hr). Dedicated endpoints add RTX-5090 at $0.73/GPU-hr. Agent Sandbox now publishes per-unit rates ($0.0000098/vCPU-second, $0.0000032/GiB-second, $0.00009/GB-hour with first 60 GB free) and a $100 / 90-day free-credit offer.

Pricing snapshot — per-token inference, per-hour GPU, per-second sandbox
Novita lists 226 models on per-token/per-image/per-video pricing; on-demand GPUs from $0.55/hr; bare-metal H100 $1.70 and B200 $4.77 per GPU/hr; dedicated endpoints H100 $1.99 / H200 $2.99 per GPU-hour; agent sandbox billed per-second on vCPU + memory.
GLM-4.6, Kimi K2, DeepSeek V3.2 Exp added; output-token cuts
Catalog expands with zai-org/glm-4.6 ($0.6/$2.2), moonshotai/kimi-k2-instruct ($0.57/$2.3) and deepseek-v3.2-exp at $0.27/$0.41 — a sharp output-token cut versus V3.1's $1. DeepSeek V3.1 input/output held at $0.27/$1. Wayback web.archive.org/web/20251003030153/novita.ai/pricing.

Full serverless LLM rate card published
Serverless Endpoints tab renders the full per-million-token catalog: DeepSeek V3.1 $0.27/$1, Llama 3.1 8B $0.02/$0.05, Llama 3.3 70B $0.13/$0.39, GLM-4.5 $0.6/$2.2, Qwen3-Coder-480B $0.29/$1.2, with several small models (Llama 3.2 1B, Qwen3 4B, Gemma 3 1B) listed Free. Wayback web.archive.org/web/20250911221805/novita.ai/pricing.

Agent Sandbox launches; pricing splits into four endpoint tabs
Pricing page restructured into Serverless Endpoints / Dedicated Endpoints / GPUs / Agent Sandbox tabs — the per-second Agent Sandbox product is now live. Batch inference advertised at an introductory 50% token discount. Image rate back to $0.001/image (512×512, 5 steps); MiniMax speech-02-hd $80/1M characters, Voice-Cloning $2.4/voice. Wayback web.archive.org/web/20250804005313/novita.ai/pricing.
Redesign to Model APIs + GPUs; HQ moves to San Francisco
Pricing page redesigned to a light-theme 'Model APIs / GPUs' tabbed layout; footer HQ changes to 156 2nd Street, San Francisco. A '$10,000 in credits' startup program launches. Image rate shown at $0.003/image (1024×1024, 20 steps); Text to Speech $15/1M characters. Wayback web.archive.org/web/20250210165912/novita.ai/pricing.
LLM API and Audio added alongside image/video
An 'LLMs' tab and an LLM API product appear in the catalog; Audio (Text to Speech, Voice Cloning) is added. Still credit-based with the same image rates (txt2img $0.0015/image). Wayback web.archive.org/web/20240521203043/novita.ai/pricing.
Credit-funded image-generation API (Singapore)
Earliest archived pricing surface: Novita was a Stable-Diffusion image API billed from a prepaid USDT/Stripe credit balance, tagline 'The price is only 1/10 of DALL-E2 and MJ.' Text-to-image quoted at $0.0015/image (512×512, 20 steps), upscale from $0.0021/image. Footer listed a Singapore HQ (14 Robinson Road). Wayback web.archive.org/web/20240225192128/novita.ai/pricing.
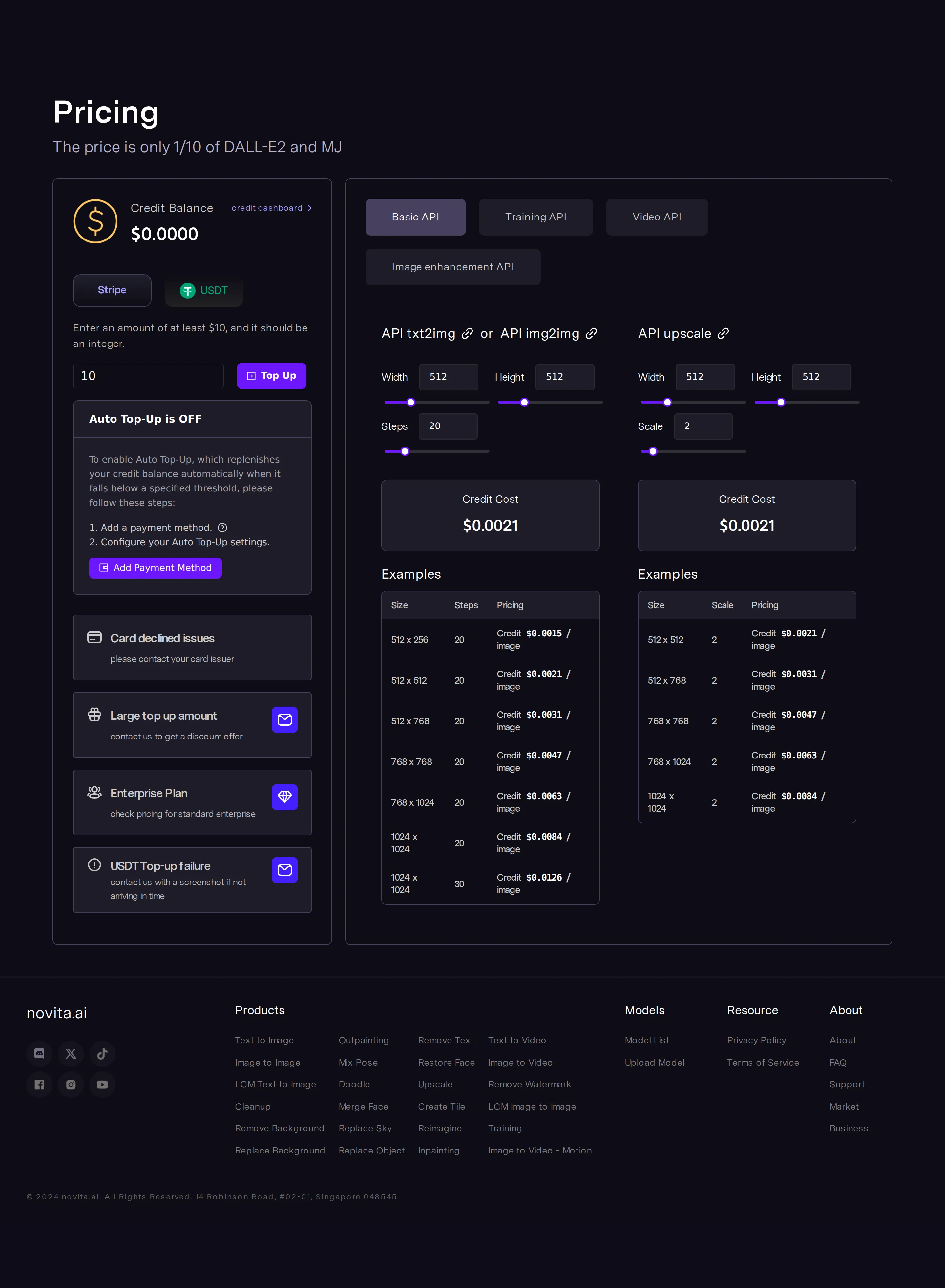
- · Novita publishes per-second billing for both GPU instances and agent sandboxes — a 5-minute coding-agent task on 1 vCPU + 512 MiB RAM is quoted at roughly $0.0034.
- · The same NVIDIA H100 appears at two prices depending on product: $1.99/GPU-hour as a dedicated endpoint and $1.70/GPU/hr on an 8-GPU bare-metal node — and Novita has stopped listing H100 on its self-serve GPU-instance page entirely, which is now RTX-class only.
- · Novita lists 226 models on its catalog and undercuts first-party APIs — DeepSeek V3.1 runs $0.27 input / $1 output per million tokens versus DeepSeek's own rates.
Questions & answers
- How does Novita AI pricing work?
- Novita is pure pay-as-you-go. Model inference is billed per million tokens (LLMs), per image, per video-second, or per 1M characters (audio); GPUs are billed per hour (on-demand or spot); and agent sandboxes are billed per second on vCPU and memory. There is no monthly minimum and you can start for free.
- How much does an NVIDIA H100 cost on Novita AI?
- It depends on the product. A dedicated inference endpoint on H100 80GB is $1.99 per GPU-hour, and an 8-GPU bare-metal H100 SXM node is $1.70 per GPU/hr. As of mid-2026 H100 is no longer listed on Novita's self-serve GPU-instance page, which carries RTX-class GPUs (RTX 4090 from $0.33/hr on-demand, $0.17/hr spot).
- Does Novita AI have a free tier?
- Yes. Novita advertises 'Free to start, scales as you grow' — you can sign up and call the model APIs without a subscription, paying only for the tokens, images, GPU hours, or sandbox seconds you consume.
- What is the cheapest LLM on Novita AI?
- Among flagship-class models, Llama 3.1 8B Instruct is among the cheapest at $0.02/M input and $0.05/M output. Larger models like DeepSeek V4 Pro run $1.6/M input and $3.2/M output. As of the 2026-07-06 capture, the base RTX 4090 24GB instance is $0.33/hr on-demand ($0.17/hr spot).
- How is the Novita Agent Sandbox billed?
- The Agent Sandbox is billed per second based on the vCPU and memory you allocate, with no plans or lock-ins. Example quotes include ~$0.0034 for a 5-minute task on 1 vCPU + 512 MiB RAM and ~$0.3744 for a 1-hour multi-agent workload on 8 vCPU + 8 GiB RAM.
- Does Novita AI offer bare-metal GPU servers?
- Yes. Bare-metal nodes ship 8 GPUs per node with zero virtualization overhead and contractual SLAs. Published rates are $1.70/GPU/hr for H100 SXM and $4.77/GPU/hr for B200 SXM; H200, RTX 5090, and RTX 4090 nodes are quoted via contact sales.