AI Summary
About
Anthropic is a San Francisco-based AI safety company founded in 2021 by Dario Amodei (CEO), Daniela Amodei (President), and seven other former OpenAI researchers. Unlike OpenAI’s shift toward commercial dominance, Anthropic positions itself explicitly as a safety-focused AI lab — its public benefit corporation structure and Responsible Scaling Policy (RSP) commitments differentiate it from pure-commercial competitors.
Anthropic’s flagship product is Claude, a family of large language models competing directly with OpenAI’s GPT series, Google’s Gemini, and Meta’s Llama. The company has raised over $10B from investors including Amazon ($4B+), Google ($300M+), Spark Capital, and Salesforce Ventures. Amazon is both the largest investor and the primary cloud deployment partner — Claude is available natively on Amazon Bedrock, giving Anthropic enterprise distribution at AWS scale.
Anthropic’s revenue is driven primarily by the Claude API and a fast-growing Claude.ai subscription base, with the Claude Sonnet and Haiku tiers dominating production enterprise deployments and Claude Code/Cowork pulling the developer tools into the subscription. As of July 2026 the API spans the Claude 4.x/5 generation — Opus 4.8 ($5/$25), the newly launched Sonnet 5 (introductory $2/$10 through August 31, 2026, then $3/$15), and Haiku 4.5 ($1/$5) — plus a top band: Claude Fable 5 (generally available June 9, 2026, at $10/$50 per 1M) and Claude Mythos 5 (limited availability through Project Glasswing, same pricing). A research-preview Fast mode adds a premium speed SKU (Opus 4.8 at $10/$50; Opus 4.6/4.7 at $30/$150), and Claude Managed Agents introduces a second billing dimension — $0.08 per session-hour of runtime on top of standard token rates. The company competes with OpenAI as a near-peer on technical capability, while differentiating on safety research, interpretability transparency, and a developer experience that many engineers prefer to GPT’s API.
Pricing summary : How Anthropic’s consumer subscription and token API pricing work together
Anthropic runs the same dual-surface structure as OpenAI: a freemium subscription stack for Claude.ai users (Free → Pro → Max → Team → Enterprise) and a pure pay-per-token API for developers. The two surfaces are entirely separate billing environments.
On the consumer side, Pro is $17/mo on annual billing ($200 up front) or $20 billed monthly, Max starts at $100/mo for 5×–20× more usage, and Team Standard seats are $20/seat/mo annual or $25 monthly with a 5-seat minimum (Premium seats run $100–$125). Enterprise is custom and sales-led, anchored on a $20/seat license plus usage at API rates.
On the API, the per-token ladder now runs Haiku 4.5 ($1/$5) → Sonnet 5 (introductory $2/$10 through Aug 31, 2026, then $3/$15) → Opus 4.8 ($5/$25) → Claude Fable 5 and Mythos 5 ($10/$50, the flagship band). Claude leans on three structural pricing mechanisms layered on top: prompt caching (a cached-input read costs just 10% of the base input rate — e.g. $0.20/1M on Sonnet 5 at intro pricing), the Batch API (50% off input and output for async workloads), and a research-preview Fast mode that trades cost for latency (Opus 4.8 at $10/$50; Opus 4.7 at $30/$150, now deprecated and removed July 24, 2026). Beyond Messages-API tokens, two newer dimensions appear: Claude Managed Agents bills $0.08 per session-hour of runtime alongside tokens, and Claude Platform on AWS meters usage in Claude Consumption Units (CCU) at $0.01 per CCU (100 CCU = $1.00 of token-rated usage). A US-only data-residency setting (inference_geo: "us") applies a 1.1× multiplier on all token categories. These features make Claude disproportionately attractive for enterprise AI workflows with large, repeated system prompts.
The safety-and-capability narrative is baked into the product positioning but not the pricing structure. Anthropic does not charge a premium for safety features, and compliance functionality (SSO, SCIM, audit logs) lives in the standard Enterprise tier — not a premium safety add-on. This approach mirrors how enterprise SaaS companies bundle compliance features to drive enterprise tier conversion rather than pricing them separately.
Pricing by product
Claude.ai Consumer & Team Subscriptions
| Tier | Price | Key capabilities | Notable limits |
|---|---|---|---|
| Free | $0 | Limited daily usage; code, web search, files, memory | Daily usage cap; no API access |
| Pro | $17/mo annual ($200/yr) • $20 monthly | More usage; Claude Code + Cowork; more models; Projects | Single user; usage limits apply |
| Max | From $100/mo | 5× or 20× Pro usage; higher output limits; priority access | Individual plan; usage-metered |
| Team | $20/seat/mo annual • $25 monthly (Standard) | Shared admin, central billing, usage analytics, data exclusion | 5-seat minimum; Premium seats $100–$125 |
| Enterprise | $20/seat + usage at API rates (contact sales) | SSO + domain capture, SCIM, audit logs, HIPAA-ready, role-based access, spend limits | Sales-led; seat price published, usage scales with model/task |
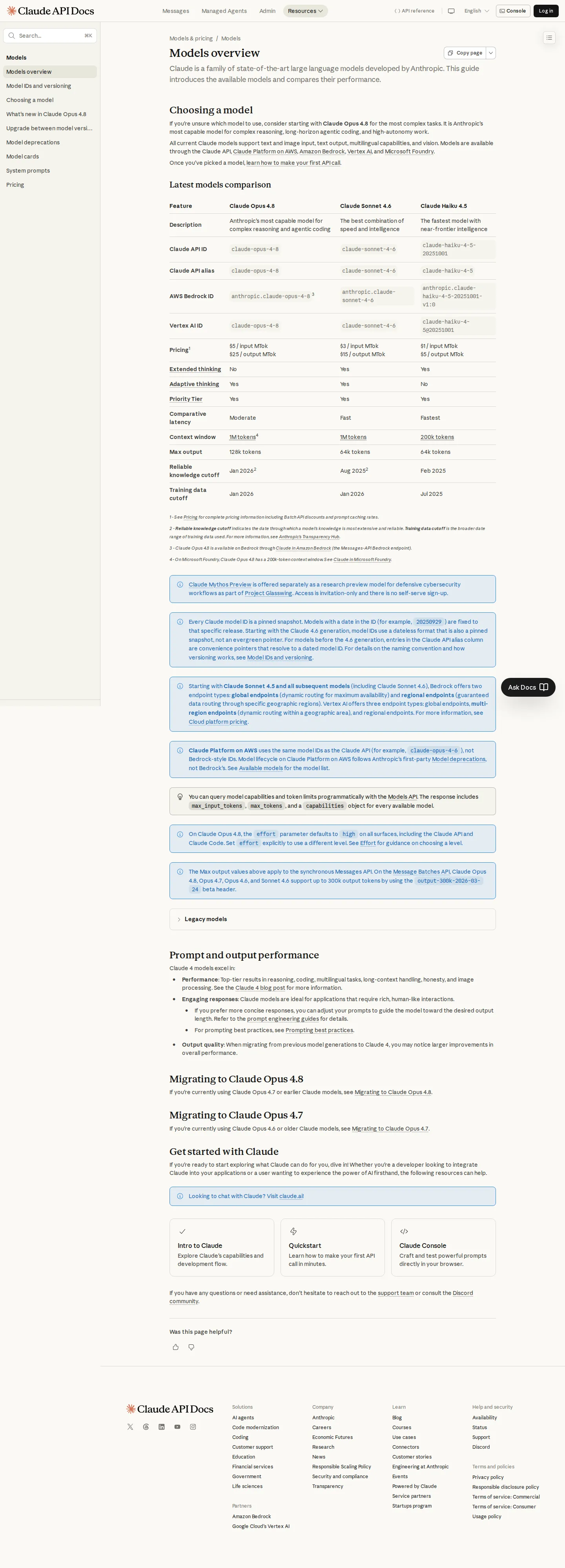
Claude API — Core Models (per 1M tokens)
| Model | Input | Output | Context | Notes |
|---|---|---|---|---|
| Claude Fable 5 | $10 | $50 | 1M | Most capable widely released model; GA June 9, 2026 |
| Claude Mythos 5 | $10 | $50 | 1M | Limited availability (Project Glasswing); same pricing as Fable 5 |
| Claude Opus 4.8 | $5 | $25 | 1M | Most capable Opus-tier; complex reasoning and agentic coding |
| Claude Opus 4.7 | $5 | $25 | 1M | Prior Opus generation; same band as 4.8 |
| Claude Sonnet 5 (intro, through Aug 31 2026) | $2 | $10 | 1M | New production standard; introductory pricing |
| Claude Sonnet 5 (standard, from Sept 1 2026) | $3 | $15 | 1M | Standard pricing takes effect after intro window |
| Claude Sonnet 4.6 | $3 | $15 | 1M | Prior Sonnet generation; superseded by Sonnet 5 |
| Claude Haiku 4.5 | $1 | $5 | 200K | Fastest; near-frontier; cheapest current model |
| Claude Opus 4.1 / 4 (deprecated) | $15 | $75 | 200K | Legacy Opus band; superseded by 4.5+ |
| Claude Haiku 3.5 (retired) | $0.80 | $4 | 200K | Retired except on Bedrock and Google Cloud |
Claude API — Cost Reduction & Usage Features
| Feature | Mechanism | Rate |
|---|---|---|
| Batch API | Async processing | 50% off input + output (e.g. Sonnet 5 $1 / $5 intro, $1.50 / $7.50 standard; Fable 5 $5 / $25) |
| Prompt cache write | Store reusable context | 5-min = 1.25× base input ($2.50/1M Sonnet 5 intro); 1-hour = 2× ($4/1M Sonnet 5 intro) |
| Prompt cache read | Reuse cached context | 10% of base input — $0.20/1M Sonnet 5 (intro), $0.50/1M Opus 4.8, $0.10/1M Haiku 4.5 |
| Fast mode (research preview) | Premium speed on Opus tier | Opus 4.8 $10 / $50; Opus 4.7 $30 / $150 (deprecated, removed July 24 2026; not on Opus 4.6, AWS, or Batch) |
| Data residency | US-only inference (inference_geo: "us") | 1.1× multiplier on all token categories (Opus 4.6+, Sonnet 4.6+) |
| Web search tool | Server-side search | $10 per 1,000 searches, plus token costs |
| Code execution | Container runtime | 1,550 free hours/mo, then $0.05/hour per container |
Claude Managed Agents & Claude Platform on AWS
| Dimension | Mechanism | Rate |
|---|---|---|
| Managed Agents — tokens | Standard model rates apply | Per Model pricing; caching multipliers apply |
| Managed Agents — session runtime | Metered while session status is running | $0.08 per session-hour (replaces container-hour billing) |
| Claude Platform on AWS / Microsoft Foundry | Token usage rated in USD, converted to CCU | $0.01 per Claude Consumption Unit (100 CCU = $1.00); arrears/postpaid via AWS or Azure Marketplace |
Sales motions across products: PLG / self-serve for Free, Pro, Max, Team, and API; sales-led for Enterprise. Amazon Bedrock and Google Cloud customers access Claude via their existing cloud billing.
Hidden costs : What Anthropic API users actually pay beyond base model rates
Archetype A: RAG application using Claude Sonnet 4.6 with large system prompts
A document Q&A app with a 50K-token system prompt + knowledge base, serving 5,000 queries/day. Each call: ~52K input tokens (system prompt + query), ~800 output tokens. (Sonnet has held the $3/1M input, $15/1M output price point across generations, so these figures track the current Sonnet 4.6 rate.)
| Scenario | Monthly token volume | Monthly cost |
|---|---|---|
| No caching — full rate | 7.8B input, 120M output | $23,400 + $1,800 = $25,200 |
| With prompt caching (80% hit) | 1.6B standard + 6.2B cached | ~$4,800 + $1,860 + $1,800 = $8,460 |
| With Batch API (latency-tolerant) | Same volume | $4,230 (50% off) |
Prompt caching can reduce this workload’s cost by 66%. Combining caching and Batch API gives a 83% cost reduction vs uncached real-time. These compound savings are not obvious without modeling — most teams discover them only after their first month’s bill.
Archetype B: 20-person team on Claude.ai Team (annual billing, Standard seats)
| Line item | Monthly cost |
|---|---|
| 20 Standard seats × $20/mo (annual) | $400 |
| API for custom integrations | $200–$1,500 |
| Estimated total | $600–$1,900 |
Note: Team requires a 5-seat minimum. Standard seats are $20/seat/mo on annual billing or $25 monthly — so monthly billing adds 25% per seat. Power users can be put on Premium seats ($100/mo annual, $125 monthly) instead of buying everyone Max. There are no self-serve options for mid-term seat reduction on annual Team plans.
Use the Anthropic pricing calculator to model your monthly cost based on model selection, token volume, caching strategy, and batch vs. real-time split.
Pricing evolution : Anthropic’s pricing history from Claude beta to Claude 4
Cadence
| Quarter | Price changes | Product / SKU additions | Notes |
|---|---|---|---|
| 2023 Q1 | 0 | 1 | Claude API limited beta (invite-only; pricing unpublished) |
| 2023 Q3 | 0 | 1 | Claude 2 launched publicly; 100K context; first public pricing |
| 2024 Q1 | 1 | 3 | Claude.ai Pro $20/mo; Claude 3 Haiku/Sonnet/Opus launched |
| 2024 Q2 | 0 | 1 | Claude 3.5 Sonnet — Opus performance at Sonnet price |
| 2024 Q3 | 0 | 2 | Prompt caching + Batch API launched; both structural cost tools |
| 2024 Q4 | 1 | 1 | Claude 3.5 Haiku ($0.80/$4) launched; 3.5 Sonnet updated |
| 2025 Q1 | 0 | 1 | Claude 3.7 Sonnet with extended thinking |
| 2025 Q3 | 0 | 2 | Claude Sonnet 4 + Opus 4 launched |
| 2026 H1 | 0 | 5+ | Claude 4.x line (Opus 4.8, Sonnet 4.6, Haiku 4.5); Max plan + Claude Code/Cowork; Fable 5 / Mythos 5 flagship band ($10/$50); Fast mode + Managed Agents |
| 2026 Q3 | 1 | 1 | Claude Sonnet 5 launched (intro $2/$10 through Aug 31, then $3/$15); Fast mode Opus 4.7 deprecated; Microsoft Foundry CCU billing |
Tracked range: 2023 Q1–2026 Q3. The Sonnet input/output anchor ($3/$15 per 1M) has held from Claude 3 Sonnet through Sonnet 5’s standard band (Sonnet 5 launches at an introductory $2/$10 through August 31, 2026). Consumer pricing now spans Pro ($17/mo annual, $20 monthly), Max (from $100/mo), and Team (Standard $20/seat annual, $25 monthly; Premium $100–$125).
Notable changes
- 2024-01-01 — Claude.ai Pro launched at $20/month, matching ChatGPT Plus price exactly. First consumer revenue.
- 2024-03-04 — Claude 3 family (Haiku/Sonnet/Opus) launched with all models at 200K context. Claude 3 Opus priced identically to GPT-4 Turbo ($15/$75 per 1M); immediately scored higher on MMLU, HumanEval, and reasoning benchmarks. (Anthropic announcement)
- 2024-06-20 — Claude 3.5 Sonnet launched at identical Sonnet pricing ($3/$15) but outperformed Claude 3 Opus — making Opus obsolete for most workloads within weeks of its $15/1M launch.
- 2024-08-14 — Prompt caching launched. Cache read at $0.30/1M (vs $3/1M standard for Sonnet) represents the most significant structural cost reduction Anthropic has offered. (Anthropic blog)
- 2025-02-24 — Claude 3.7 Sonnet extended thinking launched. First Anthropic model to expose chain-of-thought reasoning tokens, billed at output rate. Direct response to OpenAI o1’s reasoning capabilities. (Anthropic announcement)
- 2025-07-07 — Claude 4 family launched (Sonnet 4, Opus 4). Sonnet 4 maintained $3/$15 per 1M pricing with improved performance and a 64K output limit.
- 2026-05 — The Claude 4.x line is Opus 4.8 ($5/$25 per 1M, 1M context), Sonnet 4.6 ($3/$15, 1M context), and Haiku 4.5 ($1/$5, 200K context). Opus moved to a $5/$25 band — well below the legacy Opus $15/$75 — while Haiku rebased to $1/$5. On the consumer side, Pro sits at $17/mo (annual), the Max plan offers 5×–20× usage from $100/mo, and Team Standard seats are $20/seat/mo annual ($25 monthly).
- 2026-06-09 — Anthropic introduced a new flagship band above Opus: Claude Fable 5 (generally available) and Claude Mythos 5 (limited availability via Project Glasswing) at $10/$50 per 1M with a 1M context window — double the Opus 4.8 rate. The same window added a research-preview Fast mode premium speed SKU (Opus 4.8 $10/$50; Opus 4.6/4.7 $30/$150) and Claude Managed Agents, which bills $0.08 per session-hour of runtime on top of standard token rates. Claude.ai consumer and Team pricing was unchanged.
- 2026-07-06 (current) — Claude Sonnet 5 launched as the new production-standard Sonnet tier at introductory $2/$10 per 1M input/output through August 31, 2026, after which the standard $3/$15 band takes effect (the same anchor Sonnet has held since Claude 3). Batch pricing is $1/$5 (intro) then $1.50/$7.50, and Sonnet 5 includes the full 1M-token context at standard rates. Fast mode for Opus 4.7 was deprecated (removal July 24, 2026), and Microsoft Foundry joined AWS as a Claude Consumption Unit marketplace platform. Claude.ai consumer, Team, and Enterprise pricing was unchanged. (Claude API pricing)
What’s unique : Anthropic’s distinctive pricing mechanics
1. Prompt caching creates a structural cost advantage for long-context applications. A cached-input read costs 10% of the base input rate — a 10× gap versus uncached input (e.g. $0.20/1M read vs $2/1M input on Sonnet 5 at intro pricing). For RAG applications, agent systems, and any workflow with a large, repeated system prompt, this creates an 80–90% effective input cost reduction that OpenAI’s standard caching (50% off) cannot match. This makes Claude disproportionately attractive for the enterprise agentic workloads where context size matters most.
2. Large context is standard, not a premium gate. The frontier and production tiers ship a 1M-token context window at standard pricing — Fable 5, Opus 4.8, and Sonnet 5 all include the full 1M window with no per-token premium, and even the cheapest tier, Haiku 4.5, carries 200K. Context length is not a monetization lever; a 900k-token request bills at the same per-token rate as a 9k-token one. This value metric design choice means Anthropic customers rarely face an “upgrade for longer context” wall.
3. The Sonnet anchor held flat for four generations — and Sonnet 5 briefly undercut it. Claude 3.5 Sonnet (June 2024), Claude 3.7 Sonnet (Feb 2025), Claude Sonnet 4 (July 2025), and Sonnet 4.6 all held $3/1M input, $15/1M output while performance improved with each version. Sonnet 5 (July 2026) breaks the pattern in the customer’s favour: an introductory $2/$10 through August 31, 2026 — the first time the production Sonnet tier has been priced below the anchor — before reverting to the familiar $3/$15 on September 1. The intro cut is a launch-adoption lever, not a permanent repricing, but it reinforces the same deflationary value delivery narrative: developers who built on 3.5 Sonnet have received every later capability gain at the same-or-lower rate, deepening switching-cost loyalty.
4. Safety-first brand does not carry a pricing premium. Anthropic’s Constitutional AI, RSP commitments, and interpretability research are central to its enterprise pitch, but not priced as add-ons. Unlike some enterprise software vendors that charge for compliance features, Anthropic includes safety/governance features in the standard Enterprise tier. This reflects a market judgment that safety is a prerequisite in the enterprise segment, not a premium — and that pricing it separately would undermine the safety positioning.
5. Amazon Bedrock integration as an enterprise distribution channel. AWS customers can access Claude through Amazon Bedrock under their existing AWS billing, at rates that include a Bedrock markup. This effectively gives Anthropic a sales channel through every AWS Enterprise Discount Program customer without requiring a direct Anthropic contract. The tradeoff: Bedrock pricing is slightly higher than direct API, and Anthropic sees less revenue per token. For enterprise buyers, the consolidated billing convenience is worth the premium.
Strengths & weaknesses
| Strengths | Weaknesses |
|---|---|
| Prompt caching gives 90% effective input discount — best structural cost lever in the API market | Free tier has lower daily message limits than ChatGPT Free; hurts top-of-funnel adoption |
| 1M context on Fable 5, Opus 4.8, and Sonnet 5 at standard pricing (200K even on Haiku) | Enterprise pricing is fully opaque; zero published rates |
| Sonnet anchor held $3/$15 across four generations, and Sonnet 5’s intro $2/$10 undercuts it through Aug 31 — strong developer trust | The API SKU surface has multiplied (Fable/Mythos flagship, Fast mode, Managed Agents session-hours, AWS/Azure CCU) — harder to reason about total cost |
| Amazon Bedrock integration provides enterprise distribution at AWS scale | Revenue (~$2–3B ARR) still significantly below OpenAI; smaller distribution advantage |
| Constitutional AI and RSP safety positioning is a credible differentiator for regulated industries | No DALL-E / image generation equivalent in the product; API is text/vision only |
| Batch API + prompt caching combination enables aggressive cost optimization for background workloads | Rate limits are more restrictive than OpenAI at equivalent tiers |
| Sonnet 5 intro cut ($2/$10) gives price-sensitive teams a window to migrate before the $3/$15 revert | Claude.ai consumer products have less feature breadth than ChatGPT (no advanced voice, limited integrations) |
Billing UX : Anthropic’s subscription controls and API payment experience
- Self-serve plans — Claude.ai Free, Pro, Max, and Team plans are all self-serve via
claude.ai/settings. No sales call required up to Team tier. - Annual vs monthly — Pro is $17/mo on annual billing ($200 up front) or $20 billed monthly. Team Standard seats are $20/seat/mo annual or $25 monthly; Premium seats $100 annual or $125 monthly. Max starts at $100/mo.
- API prepaid credits — API usage is billed against a prepaid balance or directly to credit card. There is no free trial credit tier.
- Spend monitoring — API dashboard shows per-model usage and spend in near-real-time. No default hard cap; users must configure limits manually.
- Prompt cache billing — Cache writes are charged at creation; cache reads are charged separately at the discounted rate. Cache entries expire after approximately 5 minutes (or 1 hour) of inactivity.
- Batch API billing — Billed at 50% off standard rates upon batch completion. Batches process within 24 hours.
- Managed Agents session runtime — Claude Managed Agents bills a second meter: $0.08 per session-hour, measured to the millisecond and accruing only while the session status is
running(idle, rescheduling, and terminated time do not count). This replaces Code Execution container-hour billing for agent sessions. - Claude Consumption Units (AWS) — On Claude Platform on AWS, token usage is rated in USD then converted to CCU at $0.01 each and reported to AWS Marketplace hourly; the AWS bill shows a single CCU line item, billed in arrears with no prepaid credits.
- Fast mode / data residency modifiers — Research-preview Fast mode and the US-only
inference_geo: "us"setting are per-request modifiers that stack on top of caching and batch multipliers; both raise per-token cost (Fast mode is a premium speed SKU, data residency a flat 1.1× multiplier). - Amazon Bedrock — AWS customers access Claude via Bedrock at Bedrock-specific rates (slightly higher than direct API to cover AWS margins). Billed through AWS account.
- Enterprise billing — Invoice-based with custom payment terms. SCIM provisioning, SSO, and audit log access included at the Enterprise tier.
- Refund policy — Anthropic does not publish a standard refund policy; requests are handled case-by-case via support.
Strategic wins : Why Anthropic’s pricing decisions worked
1. Claude 3.5 Sonnet redefined the price-performance frontier
By launching Claude 3.5 Sonnet (June 2024) at $3/$15 per 1M tokens — the same price as Claude 3 Sonnet — while outperforming Claude 3 Opus ($15/$75), Anthropic made Opus obsolete within weeks of its own launch. This was a deliberate strategic choice: instead of protecting Opus revenue by price-protecting 3.5 Sonnet, Anthropic collapsed the performance-price curve to drive developer adoption. The result: Claude 3.5 Sonnet became the most-used model in the Anthropic portfolio within 60 days of launch. See how AI companies compete on pricing for the broader context.
2. Prompt caching created a structural moat in long-context workloads
Launching prompt caching with a 90% read discount ($0.30 vs $3/1M for Sonnet) in August 2024 was a decisive move in the enterprise AI cost war. For any workload with large, repeated context — RAG systems, agent loops, document analysis — Claude’s effective input cost dropped to levels that OpenAI couldn’t match until its own caching launched. This usage-based cost optimization feature converted price-sensitive developers from GPT-4o to Claude Sonnet, often without requiring a direct sales conversation.
3. Matching ChatGPT pricing eliminated the “Anthropic costs more” objection
By launching Claude.ai Pro at $20/month — identical to ChatGPT Plus — Anthropic eliminated the pricing friction in enterprise procurement comparisons. AI tool evaluations rarely choose between “identical price” options on price; they choose on capability, safety, or trust. Anthropic’s parity pricing converted the conversation from “which is cheaper” to “which is better for our use case” — a superior positioning that plays to Anthropic’s capability and safety strengths.
4. Amazon Bedrock integration gave enterprise sales distribution at no direct cost
Rather than building an enterprise sales organization from scratch, Anthropic leveraged Amazon Bedrock to reach every AWS enterprise customer through an existing procurement relationship. AWS customers can use Claude on their existing AWS commitment, bill through their existing AWS invoice, and access Claude with no additional vendor vetting. This channel pricing strategy sacrifices some margin per token (Bedrock adds a markup) in exchange for access to AWS’s ~$100B+ enterprise customer base.
5. Sonnet 5’s time-boxed intro cut buys migration without a permanent repricing
Launching Sonnet 5 (July 2026) at an introductory $2/$10 — a third below the $3/$15 anchor — through August 31, then snapping back to $3/$15 on September 1, is a disciplined go-to-market move. It gives price-sensitive teams a concrete window and a concrete reason to port workloads onto the newest model now, capturing switching cost while adoption is being decided, without conceding the Sonnet price floor that anchors Anthropic’s enterprise budget-predictability story. Because the revert is published up front, it reads as a launch promotion rather than a bait-and-switch — the same transparent-pricing discipline that protects developer trust. The 30% higher token count from Sonnet 5’s newer tokenizer partly offsets the headline discount, so the net effective cut is smaller than $2/$10 vs $3/$15 suggests — a nuance sophisticated buyers will model before migrating.
Areas to improve : Gaps in Anthropic’s pricing approach
1. Free tier daily limits are too restrictive for top-of-funnel adoption
Claude.ai Free’s message caps are among the most restrictive in the consumer AI space. ChatGPT Free offers unlimited GPT-4o conversations (with rate limits); Gemini Free is similarly accessible. A user who hits Claude’s daily free limit during their first serious use session is likely to switch to ChatGPT rather than upgrading to Pro. This acquisition funnel friction means Anthropic is underinvesting in free-tier generosity at the exact point where developer and consumer mindshare is won. Loosening free tier limits, even modestly, would improve top-of-funnel conversion.
2. Prompt caching complexity creates a two-tier developer experience
Prompt caching requires explicit implementation — developers must deliberately structure prompts to enable caching, understand cache TTL mechanics, and monitor cache hit rates. Many developers using Claude via LangChain, LlamaIndex, or simple API wrappers never enable caching and overpay significantly. An automatic caching mode (where repeated context is cached without explicit prefix marking) would democratize the savings and reduce the implementation complexity barrier for less sophisticated API users.
3. Enterprise pricing opacity creates evaluation friction for mid-market buyers
Anthropic Enterprise has no published pricing. A 25-person company evaluating Claude for an internal knowledge base cannot budget without a sales call. Given that Anthropic’s strongest competitive advantage over OpenAI is safety and API quality — not sales service — requiring a sales conversation to access pricing information loses deals to competitors with published rates. Publishing at least a range (“Enterprise typically starts at $X/seat/year”) would accelerate evaluation cycles for the mid-market segment that most benefits from Anthropic’s safety positioning.
4. Model-tier and billing-dimension sprawl is outpacing the pricing page’s legibility
Through mid-2026 the API surface has multiplied fast: a Fable 5 / Mythos 5 flagship band above Opus, a research-preview Fast mode with its own premium rates, a per-session-hour Managed Agents meter, a US-only 1.1× data-residency multiplier, and Claude Consumption Unit metering on AWS and Azure — layered on top of an intro-vs-standard Sonnet 5 rate that changes on a calendar date. A buyer now has to reconcile up to four billing dimensions (token rate × caching × batch × session-hours, then a possible CCU conversion) plus a tokenizer that emits ~30% more tokens on the newest models. A published, side-by-side “total cost of a workload” worksheet — or an intro-vs-standard toggle on the pricing page itself — would reduce the cost-modeling burden that now falls entirely on the customer and blunts the clarity that has been an Anthropic strength.
Monetization stack & signals : how Anthropic builds & buys its revenue engine
Buys 6 Builds 1 3 signal roles
A true hybrid: one usage meter feeds both motions — the PLG API on Stripe, sales-negotiated enterprise through Zuora and a Deal Desk. The tell is the Staff Billing Platform role below, hired to build the in-house layer bridging the two.
-
“The first thing you will inherit is our homegrown ledger application and the integrations that connect it to Workday, NetSuite, Zuora, Stripe, Tesorio, and Salesforce... the team is moving beyond configuring off-the-shelf platforms and into building homegrown, production-grade financial applications that no vendor has built for us yet.”
-
“Optimize QTC solutions with Salesforce and other systems (Ironclad, Stripe and Metronome).”
-
“In this hands-on engineering role, you will both configure and extend the third-party platforms that run our financial operations including Zuora, Stripe, and Tesorio.”
-
“...both configure and extend the third-party platforms that run our financial operations including Zuora, Stripe, and Tesorio... the integrations that connect [the homegrown ledger] to Workday, NetSuite, Zuora, Stripe, Tesorio, and Salesforce.”
-
“...the integrations that connect [the homegrown ledger] to Workday, NetSuite, Zuora, Stripe, Tesorio, and Salesforce.”
-
“...configure and extend the third-party platforms that run our financial operations including Zuora, Stripe, and Tesorio...”
-
“As a Salesforce Administrator at Anthropic, you will play a key role in building and maintaining world-class CRM systems for our GTM team.”
-
Anthropic is staffing a finance lead "building sophisticated models to optimize inference infrastructure costs and performance" and to "scale novel unit economic metrics... including LTV, contribution margin" that feed "pricing and packaging" — i.e. it prices the API off measured per-token inference margin, making the cost of inference the value metric behind the price.
-
The Billing Platform team "build[s] and operate[s] the infrastructure that turns product usage into revenue across everything Anthropic ships," shipping "pricing primitives, payment flows, contract and entitlement models" so product teams "launch a paid SKU without becoming billing experts" — the metering/contract layer is an in-house build on top of Stripe/Zuora, not a packaged meter.
-
A Deal Desk hire runs "deal profitability modeling" and reviews "enterprise deals exceeding standard parameters, focusing on pricing structures, contract terms" — confirming a sales-led enterprise motion with negotiated, margin-checked custom pricing layered over the published self-serve list.
Signals reviewed · derived from public job posts
Job postings fill and close over time — once a posting is filled we keep it as a dated citation (the quoted evidence remains); use View open roles for current listings.
Key takeaways
-
Prompt caching is the most important cost lever in the AI API market today. Anthropic’s 90% discount on cached input tokens ($0.30 vs $3/1M for Sonnet) is more aggressive than any competitor. For any application with large, repeated context, this is a primary reason to choose Claude over GPT-4o. See AI cost optimization strategies.
-
Deflationary value delivery builds developer loyalty. Holding Sonnet pricing flat across four model generations (3.0, 3.5, 3.7, 4) while delivering substantial performance improvements creates deep developer trust — and Sonnet 5’s introductory $2/$10 (July 2026, reverting to $3/$15 on September 1) delivers the next capability step at a temporary discount rather than a hike. Teams that built for Claude 3.5 Sonnet have received every later improvement at the same-or-lower rate. This predictable pricing strategy — capability up, price flat or down, with any intro cut published as time-boxed — is more valuable for developer adoption than surprise repricing.
-
Safety positioning is not a pricing lever — it is a procurement accelerator. Anthropic does not charge for Constitutional AI or RSP commitments. Instead, these reduce procurement friction in regulated industries where AI safety is a vendor requirement. Safety-first positioning speeds enterprise sales cycles without requiring a premium SKU.
-
Channel distribution (Bedrock) trades margin for reach. Anthropic sacrifices per-token margin on Bedrock traffic in exchange for access to AWS’s enterprise customer base without building an enterprise sales organization. For AI platform companies, distribution partnerships at a margin discount can be more efficient than direct enterprise sales investment, especially at early scale.
-
Large context at standard pricing removes context as a gating mechanic. The current frontier and production tiers (Fable 5, Opus 4.8, Sonnet 5) include a 1M-token window at the standard per-token rate, and the cheapest tier (Haiku 4.5 at $1/$5 per 1M) still carries 200K. This simplifies customer decisions and prevents the “unexpected context window upgrade cost” that surprises enterprise buyers when their production workloads scale.
UBP implications
-
Caching creates an asymmetric cost structure that rewards architectural discipline. The 10× gap between cached and uncached input tokens means that well-architected applications (consistent system prompt prefixes, explicit cache markers) pay dramatically less than naive implementations of the same workload. For product teams, this usage aggregation dynamic means that cost optimization is an engineering priority, not just a pricing decision. The companies that invest in cache-aware prompt engineering will have 3–5× better AI infrastructure economics than those that don’t.
-
Batch API + prompt caching together enable a new category: AI background processing. The combination of 50% Batch discount plus 90% cache read discount means that a well-structured background processing workflow can cost 5–10× less than a real-time equivalent. This opens up AI-enrichment use cases (bulk document classification, async data augmentation, nightly report generation) that were not economically viable at standard rates. Usage-based billing transparency makes these savings visible to finance teams, accelerating investment.
-
A stable Sonnet anchor with time-boxed intro cuts creates a predictable API cost baseline for enterprise budgeting. Unlike OpenAI where model pricing shifts with each launch, Anthropic’s $3/$15 Sonnet anchor has held across four generations, and Sonnet 5’s July 2026 launch moved down — an introductory $2/$10 through August 31 that reverts to the same $3/$15 on September 1. The lesson for UBP strategy: publishing an intro discount with an explicit end date lets a vendor pull adoption forward without repricing risk, because finance teams can still build AI cost forecasts against the known standard rate. This predictability is a genuine enterprise procurement advantage — budget-certainty rivals safety-certification as a buying criterion in large organizations.
Sources
- Claude pricing page (accessed 2026-07-06)
- Claude API pricing — developer docs — second-source validation (accessed 2026-07-06)
- Claude Team plan — help center — second-source validation of seat pricing (accessed 2026-07-06)
- Anthropic Claude models documentation (accessed 2026-06-15)
- Anthropic blog — Claude 3 family (accessed 2026-05-29)
- Anthropic blog — Prompt caching with Claude (accessed 2026-05-29)
- Anthropic blog — Claude 3.5 Sonnet (accessed 2026-05-29)
- Anthropic blog — Claude 3.7 Sonnet (accessed 2026-05-29)
- Amazon Bedrock — Anthropic Claude pricing (accessed 2026-05-29)
Bottom line
Anthropic has built the most technically sophisticated API billing system in the consumer AI market — prompt caching, Batch API, per-model token pricing, and now a session-runtime meter and CCU marketplace billing combine to give enterprise developers more cost-optimization levers than any competitor. The Claude Sonnet price anchor ($3/$15) has held flat across four model generations while performance improved, and Sonnet 5’s July 2026 introductory $2/$10 (through August 31, reverting to $3/$15) moved the price down rather than up — the strongest developer cost-predictability story in the API market. The gaps are real and growing: a restricted free tier that hurts top-of-funnel adoption, fully opaque enterprise pricing, prompt caching that requires developer effort to activate, and a fast-multiplying SKU surface (Fable/Mythos flagship band, Fast mode, Managed Agents, AWS/Azure CCU) that is starting to tax buyers’ ability to model total cost. But for sophisticated engineering teams building production AI applications with large context, Anthropic’s combination of 1M context on the production tiers, 90% caching discounts, and safety-first positioning makes it the most compelling alternative to OpenAI for enterprise workloads.
Browse the full pricing blueprint to compare Anthropic against OpenAI, DeepSeek, and other AI platforms.
Pricing timeline : Major events on a vertical axis
Each milestone below corresponds to a public pricing change, product launch, or material adjustment. Major events use a filled marker; minor adjustments use a faded one.
Claude Sonnet 5 launches — intro $2/$10 per 1M
Anthropic launched Claude Sonnet 5 as the new production-standard Sonnet tier, priced at introductory $2/$10 per 1M input/output tokens through August 31, 2026, after which standard pricing of $3/$15 takes effect (matching the long-held Sonnet band). Batch pricing is $1/$5 (intro) then $1.50/$7.50. Sonnet 5 includes the full 1M-token context at standard rates and supersedes Sonnet 4.6. Fast mode for Opus 4.7 was deprecated (removal July 24, 2026) and Microsoft Foundry joined AWS as a CCU marketplace platform. Claude.ai consumer, Team, and Enterprise pricing is unchanged (Pro $17/$20, Team Standard $20/$25, Premium $100/$125).

Claude Fable 5 / Mythos 5 + Fast mode + Managed Agents
A new flagship API band arrives: Claude Fable 5 (GA June 9, 2026) and Claude Mythos 5 (limited availability via Project Glasswing) price at $10/$50 per 1M — double the Opus 4.8 band ($5/$25). A research-preview Fast mode adds a premium speed SKU (Opus 4.8 $10/$50; Opus 4.6/4.7 $30/$150), and Claude Managed Agents introduces a session-runtime meter at $0.08/session-hour on top of token rates. Claude.ai consumer and Team pricing is unchanged (Pro $17/$20, Team Standard $20/$25, Premium $100/$125).


Claude 4.x current lineup + Max plan
The current generation is Opus 4.8 ($5/$25 per 1M, 1M context), Sonnet 4.6 ($3/$15, 1M context), and Haiku 4.5 ($1/$5, 200K context). Opus rebased from the legacy $15/$75 band to $5/$25; Haiku moved to $1/$5. On Claude.ai, Pro is $17/mo (annual), the Max plan offers 5×–20× usage from $100/mo, and Team Standard seats are $20/seat/mo annual ($25 monthly).
Claude 4 Family (Sonnet 4, Opus 4)
Anthropic launched Claude Sonnet 4 and Claude Opus 4. Sonnet 4 maintained the $3/$15 per 1M token price with a 64K output token limit and 200K context. Opus 4 at $15/$75 per 1M provided the highest-capability tier. Both models available via API and Claude.ai.
Claude 3.7 Sonnet — Extended Thinking (Reasoning)
Claude 3.7 Sonnet launched at $3/$15 per 1M standard tokens, with an extended thinking mode that uses additional reasoning tokens billed at the same output rate. First Anthropic model with visible chain-of-thought reasoning, competing directly with OpenAI o1.
Claude 3.5 Haiku + Upgraded 3.5 Sonnet
Claude 3.5 Haiku launched at $0.80/$4 per 1M tokens, replacing 3.0 Haiku at a 3× input price increase but with substantially improved performance. Claude 3.5 Sonnet (October 2024 version, 20241022) upgraded with improved coding and reasoning.
Prompt Caching Launched — 80% Input Cost Reduction
Anthropic launched prompt caching for Claude 3.5 Sonnet and Claude 3 Haiku. Cache write costs $3.75/1M tokens (Sonnet); cache read costs $0.30/1M — a 90% discount on cached input. Batch API also launched with 50% discount on all models.
Claude 3.5 Sonnet — Better than Opus at Sonnet Price
Claude 3.5 Sonnet launched at the same $3/$15 per 1M tokens as Claude 3 Sonnet, but outperformed Claude 3 Opus on most benchmarks. This made Opus obsolete for most workloads, proving Anthropic could deliver frontier performance at mid-tier pricing.
Claude 3 Family Launched (Haiku, Sonnet, Opus)
Anthropic launched three simultaneous models: Haiku ($0.25/$1.25 per 1M tokens), Sonnet ($3/$15), and Opus ($15/$75). Opus outperformed GPT-4 on multiple benchmarks at the same price point. All models feature 200K context.
Claude.ai Pro Plan Launched at $20/month
Anthropic launched Claude.ai Pro at $20/month — identical to ChatGPT Plus. Pro included 5× usage vs free, priority access, and early feature access. First consumer revenue for Anthropic.
Claude 2 Launched — 100K Context Window
Claude 2 launched publicly with a 100K token context window — 8× larger than GPT-4's 8K default. Pricing was usage-based per token. The long context capability was the primary differentiation against OpenAI.
Claude API Limited Beta
Anthropic launched the Claude API in limited private beta. Pricing was not publicly published; access was by invitation only. Claude 1 targeted developers seeking a GPT-4 alternative.
- · Anthropic introduced the 'Constitutional AI' training method — a technique where a model critiques and revises its own outputs against a set of written principles — and published it openly in December 2022, before Claude was even publicly available.
- · Claude 3 Opus launched in March 2024 at the same $15/1M input token price as GPT-4 Turbo, but scored higher on key benchmarks — marking the first time a non-OpenAI model had credibly topped the frontier leaderboard on a flagship model launch.
- · Anthropic's prompt caching feature, launched August 2024, charges $3.75/1M write tokens but only $0.30/1M read tokens — a 12.5× read discount that can reduce effective input costs by 80%+ for applications with large, repeated system prompts.
Questions & answers
- How much does Claude.ai cost per month?
- Claude.ai offers five tiers: Free (limited daily usage), Pro ($17/month on annual billing or $20 monthly), Max (from $100/month for 5×–20× more usage), Team (Standard seats $20/seat/month annual or $25 monthly, minimum 5 seats; Premium seats $100–$125), and Enterprise (custom pricing, sales-led). The API is priced separately per token, starting at $1/1M input for Claude Haiku 4.5.
- What is the difference between Claude Pro and Team?
- Claude.ai Pro ($17/mo annual, $20 monthly) gives one user more usage than Free, access to more Claude models, Claude Code and Cowork, Projects, and Research. Team (Standard seats from $20/seat/mo annual, $25 monthly) adds central billing, an admin console, usage analytics, data exclusion from training, and a 5-seat minimum.
- Which Claude model is cheapest for API use?
- Claude Haiku 4.5 is the cheapest current Claude model at $1/1M input and $5/1M output, with a 200K context window. Claude Sonnet 5 (introductory $2/$10 per 1M through August 31, 2026, then $3/$15) is the new production standard, Claude Opus 4.8 ($5/$25) is the top Opus tier, and Claude Fable 5 ($10/$50, GA June 9, 2026) is the flagship band (with Mythos 5 at the same price in limited availability). With prompt caching, a cached-input read costs 10% of the base input rate — e.g. $0.20/1M on Sonnet 5 at intro pricing or $0.10/1M on Haiku 4.5.
- How does Anthropic's prompt caching work?
- Prompt caching lets you mark parts of a prompt (typically a large system prompt or document) for reuse. A cache write costs 1.25× the base input rate for the 5-minute TTL or 2× for the 1-hour TTL (so $2.50 or $4 per 1M on Sonnet 5 at intro pricing); a subsequent cache read costs just 10% of the base input rate ($0.20/1M on Sonnet 5 intro). Reads pay off after a single hit on the 5-minute cache.
- Does Anthropic offer a free API tier?
- Anthropic does not offer a free API tier. Claude.ai has a free consumer tier with limited daily usage, but the API requires a paid account. There are no published free trial credits — access requires a credit card or enterprise agreement. AWS Bedrock customers can trial Claude via their AWS account.
- How does Anthropic's Batch API work?
- The Batch API allows submitting multiple requests in a single file for async processing. Batch requests cost 50% less than synchronous API calls for all models. Results are returned within 24 hours. Ideal for large-scale data processing, classification, and evaluation workloads where latency is not a constraint.