AI Summary
About
Fireworks AI is a Redwood City-based generative AI infrastructure company founded in October 2022 by Lin Qiao (former PyTorch team lead at Meta), Dmytro Ivchenko, and Pawel Garbacki. The product is a high-performance inference platform optimized for serving open-source and customer-tuned models behind production endpoints — combining a serverless per-token API for popular open-weight models with on-demand dedicated GPU deployments and a fine-tuning service. The runtime is built on Fireworks’ proprietary FireAttention kernels, FireOptimizer auto-tuning, and speculative-decoding pipelines designed to extract higher throughput from each GPU than open-source serving frameworks deliver.
By 2026 Fireworks serves Cursor, Notion, Doordash, Quora, Upwork, and roughly a thousand other paying customers across enterprise AI infrastructure (RAG systems, customer-facing assistants, agentic workflows) and developer-tooling startups serving sub-second inference SLAs. The company raised a $52M Series B in July 2024 led by Sequoia Capital at a $552M post-money valuation with Bessemer, Benchmark, and NVIDIA participation; a Series C reported in 2025 brought valuation past $4B.
Fireworks competes directly with Together AI, Baseten, Replicate, and Groq for the managed-inference market, and with first-party providers (OpenAI, Anthropic, Cohere) for general-purpose API customers. Its differentiation is the combination of PyTorch-team founder credibility, aggressive per-hour H100 pricing ($7.00/hr — among the lowest in the market), and a granular fine-tuning rate card that lets cost-conscious teams choose between LoRA (cheap, fast) and full-parameter (expensive, higher quality) workflows.
Pricing summary : How Fireworks AI’s serverless + dedicated + fine-tuning stack works
Fireworks runs three parallel pricing surfaces. Serverless inference charges per million input/output tokens by model, split into Turbo (latency-optimized, higher per-token rate) and Priority (throughput-optimized, lower per-token rate) quality-of-service tiers. Cached input tokens — prompts reusing prefixes within a session window — get a 50% discount, and the Batch API applies an additional 50% discount on top, so a batched cached workload lands at 25% of standard. Dedicated deployments are on-demand per-hour GPU rentals at published rates ($7.00/hr H100/H200, $10.00/hr B200, $12.00/hr B300). Fine-tuning is priced per 1M training tokens with rates scaling by base model parameter count and training method (LoRA versus full parameter, SFT versus DPO).
The free tier is structured as a $1 trial credit on signup — small enough to evaluate the API but not to run a meaningful production workload. Enterprise tier prices are quote-based and tied to annual usage commitments that unlock volume discounts, dedicated capacity reservations, custom SLAs, and VPC deployment. This three-SKU pure-usage architecture — token / hour / training-token — mirrors the pure-usage + commitment hybrid now standard across the inference middleware category. It is also one of the most granular rate cards in the AI infrastructure pricing landscape.
What makes this different: Cached input and Batch API discounts compound independently, which is unusual — most platforms offer one or the other but not both, and most do not let the discounts stack. The compound 25%-of-standard pricing on batched RAG workloads is a meaningful structural cost advantage for any application with high prompt-prefix re-use.
Pricing by product
Serverless inference (per-token)
| Model | Input ($/1M) | Output ($/1M) | Cached input | Batch |
|---|---|---|---|---|
| Llama 3.3 70B | Published in docs | Published in docs | -50% | -50% |
| DeepSeek V3.1 | Published in docs | Published in docs | -50% | -50% |
| Qwen3 32B | Published in docs | Published in docs | -50% | -50% |
| Mixtral 8x22B | Published in docs | Published in docs | -50% | -50% |
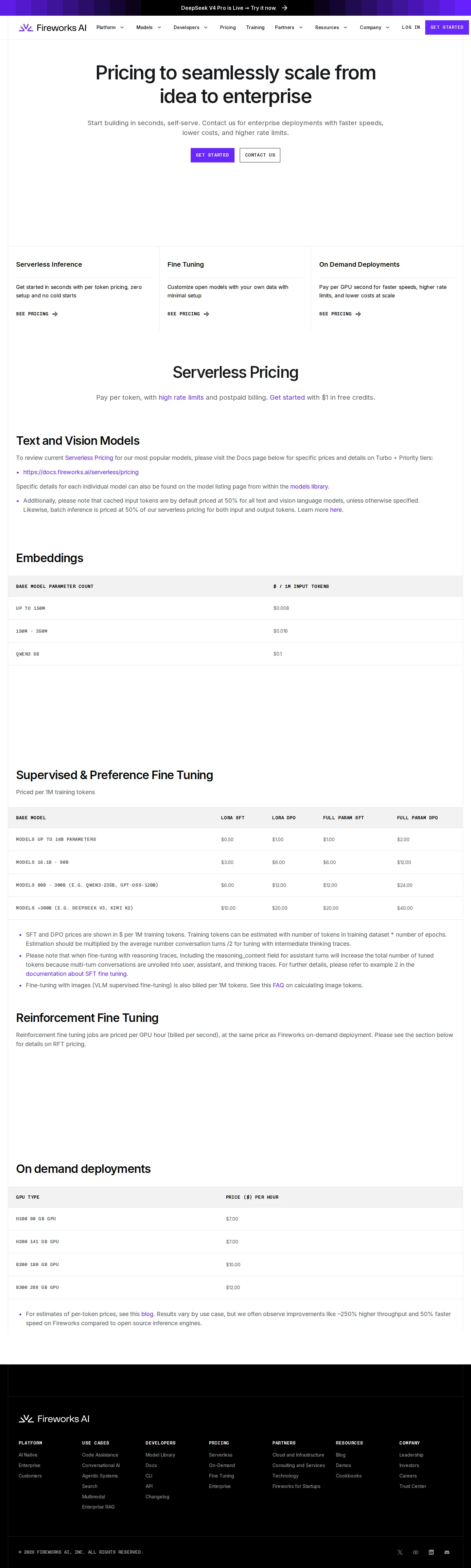
On-demand dedicated GPU (per hour)
| Instance | VRAM | Per-hour rate | Best for |
|---|---|---|---|
| H100 80GB / H200 141GB | 80 / 141 GiB | $7.00 | Frontier model serving, sustained workloads |
| B200 180GB | 180 GiB | $10.00 | Largest open models, multi-model serving |
| B300 288GB | 288 GiB | $12.00 | Frontier training and largest-context inference |
Fine-tuning (per 1M training tokens)
| Base model size | LoRA SFT | LoRA DPO | Full SFT | Full DPO |
|---|---|---|---|---|
| Up to 16B | $0.50 | $1.00 | $1.00 | $2.00 |
| 16.1B – 80B | $3.00 | $6.00 | $6.00 | $12.00 |
| 80.1B – 300B | $6.00 | $12.00 | $12.00 | $24.00 |
| Over 300B | $10.00 | $20.00 | $20.00 | $40.00 |
Embeddings (per 1M tokens)
| Model size | Rate |
|---|---|
| Up to 150M params | $0.008 |
| 150M – 350M params | $0.016 |
| Qwen3 8B | $0.10 |
Sales motions across products: PLG / self-serve for serverless, dedicated, and fine-tuning credit-card customers; sales-led for Enterprise annual commits and VPC deployments. All prices accessed 2026-05-29 from fireworks.ai/pricing.
Hidden costs : What Fireworks AI customers actually pay beyond the rate card
Archetype A: Developer-tools startup running serverless inference on DeepSeek V3.1
A growth-stage AI coding startup serving ~100K requests/day, average 2K input tokens + 500 output tokens, with high prefix re-use (system prompt + tool definitions cached):
| Line item | Monthly cost |
|---|---|
| Input tokens (3M/day × 30 = 90M, V3.1 at $0.50/1M) | $45 |
| Cached input savings (60% cache hit, -50%) | -$13.50 |
| Output tokens (15M/mo, V3.1 at $1.50/1M) | $22.50 |
| Batch API for offline analysis (negligible at this scale) | <$5 |
| Estimated total | ~$60/month |
For a developer-tools startup with strong prompt-prefix re-use, the cached input discount delivers material savings. The same workload on Together AI’s Llama 3.3 70B at $0.88/$0.88 would cost roughly $93 — Fireworks’ Llama-equivalent rate card plus 50% cached input typically lands 25–35% cheaper for prefix-heavy workloads.
Archetype B: Mid-market team running a fine-tuned Llama 70B on dedicated H100
A team that fine-tuned Llama 3.3 70B (full-parameter SFT, 10M training tokens) and serves it on a dedicated H100 with autoscaling:
| Line item | Monthly cost |
|---|---|
| Initial fine-tuning (one-time, 10M tokens × $6.00) | $60 |
| H100 dedicated (8h/day × 30 × $7.00) | $1,680 |
| Warm-pool retention (avoid cold starts during business hours, ~4h/day) | $840 |
| Bandwidth + storage (negligible at this scale) | <$10 |
| Estimated total | ~$2,530/month (after one-time $60 fine-tune) |
The H100 dedicated rate dominates the bill — and the customer is paying for warm-pool retention to maintain latency SLAs. The fine-tuning cost is amortized over many months of inference, which makes the unit economics of fine-tuned dedicated deployment far better than per-token serverless once sustained QPS rises above ~10/second.
Want to estimate your own Fireworks AI bill? Use the Fireworks AI pricing calculator to model serverless tokens, dedicated GPU hours, and fine-tuning costs by model size.
Pricing evolution : Fireworks AI’s pricing history from per-token serverless to multi-SKU platform
Cadence
| Quarter | Price changes | Product / SKU additions | Notes |
|---|---|---|---|
| 2022 Q4 | 0 | 1 | Fireworks founded; closed alpha for Llama and Stable Diffusion |
| 2023 Q3 | 0 | 1 | Public serverless API launch |
| 2024 Q1 | 0 | 1 | Dedicated deployments + LoRA fine-tuning launched |
| 2024 Q3 | 0 | 0 | Series B ($52M); no public price changes |
| 2024 Q4 | 1 | 1 | Turbo + Priority QoS tiers + cached input 50% discount |
| 2025 Q1 | 1 | 1 | Batch API at 50% discount launched |
| 2025 Q3 | 0 | 1 | B200 + B300 GPU availability ($10/hr, $12/hr) |
| 2026 Q1 | 1 | 1 | Differential embeddings pricing by parameter size |
Tracked range: 2022 Q4–2026 Q1. Quarters not listed above were verified stable (0 price changes, 0 SKU additions).
Notable changes
- 2023-08-17 — Public serverless API launch; first major positioning as “faster, cheaper Llama 2 hosting.”
- 2024-01-31 — Dedicated deployments + LoRA fine-tuning launched; pricing model expanded from single-SKU per-token to multi-SKU platform.
- 2024-11-04 — Turbo + Priority QoS tiers + cached input 50% discount launched; quality-of-service segmentation became a self-serve API choice rather than a tier upgrade.
- 2025-03-25 — Batch API launched at 50% discount across all models; compounded with cached input to enable 25%-of-standard pricing on batched cached workloads.
- 2025-08-19 — B200 + B300 added at $10/hr and $12/hr; Hopper-class H100/H200 remained at $7/hr, positioning Blackwell as a premium for largest-model workloads.
- 2026-02-10 — Differential embeddings pricing launched; sub-150M-parameter models at $0.008/1M undercut OpenAI text-embedding-3-small by 60%.
What’s unique : Fireworks AI’s distinctive pricing mechanics
1. Cached input and Batch API discounts stack independently. Most inference platforms offer either cached input OR batch discounts. Fireworks offers both, and they compound: a batched cached workload pays 25% of standard input. For RAG systems and agent loops with high prefix re-use, this is a meaningful structural cost advantage that does not require negotiating a custom contract.
2. Turbo + Priority QoS as a per-request API parameter, not a tier. Quality-of-service segmentation lets customers select per-request whether to optimize for latency (Turbo) or throughput (Priority) without changing API keys, plans, or contracts. Most competitors force QoS into a seat-tier or commitment structure; Fireworks’ parameter-based approach lets a single application route interactive requests through Turbo and background batch through Priority without operational overhead.
3. Fine-tuning rate card scales linearly with base model size AND training method. Most platforms offer either a flat per-token fine-tuning rate or a per-base-model rate card that ignores training method. Fireworks’ 16-cell grid (4 size tiers × 4 method tiers: LoRA SFT, LoRA DPO, Full SFT, Full DPO) lets cost-conscious teams trade quality for cost with a granularity competitors do not match.
4. Differential embeddings pricing by parameter size. Most embedding APIs (OpenAI text-embedding-3, Voyage, Cohere) price embeddings as a flat rate regardless of model size. Fireworks’ three-tier embeddings schedule ($0.008 / $0.016 / $0.10 per 1M) lets retrieval-pipeline operators pick a model that matches their accuracy target without paying for over-engineered embeddings. For usage-aggregation strategies at scale, the 60–90% savings on small-model embeddings are material.
5. $1 trial credit is a deliberate sales-led signal. The trial credit shrank from a more generous initial offer to $1 — small enough to test the API but not enough to evaluate a real workload. This signals that Fireworks now optimizes for sales-led enterprise pipeline rather than self-serve viral growth — a pricing-as-positioning shift typical of the post-Series-B inference middleware category.
Strengths & weaknesses
| Strengths | Weaknesses |
|---|---|
| H100/H200 at $7.00/hr is among the lowest published rates in managed inference | A100 not available on the on-demand page — must contact sales for A100 capacity |
| Cached input + Batch API discounts stack (25% of standard for batched cached) | $1 trial credit is one of the smallest in the market — limits self-serve evaluation |
| Turbo + Priority QoS as a per-request API parameter, not a tier upgrade | Per-model serverless rates require docs lookup — not surfaced on pricing page directly |
| Granular fine-tuning grid (4 size × 4 method) for cost-quality trade-offs | Image generation pricing not listed on the on-demand pricing page — only docs |
| PyTorch-team founder credibility (Lin Qiao) builds platform-runtime trust | Free tier is too small for meaningful evaluation; competitors offer $5–$100 |
| Embeddings pricing tiered by parameter size — 60% cheaper than OpenAI for small models | No published path between credit-card serverless and Enterprise commit — friction at scale |
Billing UX : Fireworks AI’s account controls and payment experience
- Self-serve signup — Sign up at
app.fireworks.aiwith email; $1 trial credit applied automatically. Credit card required for production usage. - Real-time usage console — Per-account view of serverless token consumption, dedicated GPU hours, fine-tuning training tokens, and embeddings — broken down by model and SKU.
- Per-request cost meter — API responses include usage metadata (input tokens, output tokens, cached input tokens) so client applications can compute per-request cost in real time.
- Spend alerts — Configurable email alerts at $X spend per period; no hard spend caps documented on credit-card billing.
- Payment methods — Credit card and ACH on self-serve; wire transfer, invoice billing, and AWS/GCP/Azure Marketplace on Enterprise.
- Annual commit pricing — Enterprise customers receive volume discounts in exchange for annual usage commitments; over-commitment overages bill at standard rates.
- Cached input transparency — API responses report cached input token count separately, letting customers verify cache-hit rates in real time.
- Audit logging + RBAC — Workspace-level RBAC on Pro+; SOC 2 audit-log exports on Enterprise.
- Multi-region availability — US and EU regions standard; APAC and other regions available on Enterprise via dedicated capacity reservations.
Strategic wins : Why Fireworks AI’s pricing decisions worked
1. PyTorch-team founder credibility as the runtime-optimization moat
Lin Qiao led the PyTorch team at Meta and shipped PyTorch 1.0; her co-founding of Fireworks gave the company immediate credibility with ML engineering teams evaluating inference runtimes. When customers compare Fireworks’ FireAttention kernels and FireOptimizer auto-tuning claims against open-source vLLM or TensorRT-LLM, the founder credentials act as a trust-multiplier that pure-marketing positioning cannot replicate. This made the $7/hr H100 rate believable rather than skeptical.
2. Stackable discounts (Cached input + Batch) as a competitive moat
By making cached input and Batch API discounts compound independently, Fireworks created a structural pricing advantage for RAG and agent-loop workloads that competitors offering only one or the other cannot match. For sustained high-volume customers with prefix re-use, the 25%-of-standard effective rate makes Fireworks materially cheaper at scale — a pricing-mechanic moat that procurement leaders can validate without sales conversations.
3. Per-request QoS parameter removed friction between latency and throughput optimization
By making Turbo and Priority a per-request API parameter rather than a contract-level commitment, Fireworks let a single application route interactive requests through low-latency Turbo and background batch through high-throughput Priority — without operational complexity or tier negotiations. This granular value-metric design is a meaningful UX advantage over platforms that force QoS into seat-tier or commitment structures.
4. Granular fine-tuning grid captured cost-conscious teams competitors missed
The 16-cell fine-tuning rate card (4 size tiers × 4 method tiers) gave cost-conscious teams a way to dial cost versus quality with precision: pick LoRA for cheap iteration, full-parameter for production quality, SFT for instruction following, DPO for preference alignment. Most competitors’ coarse-grained fine-tuning pricing forced over-payment for unnecessary capabilities. The granular grid let Fireworks capture both “fast cheap iteration” and “high-quality production” buyers with the same SKU surface.
Areas to improve : Gaps in Fireworks AI’s pricing approach
1. Per-model serverless rates should be on the pricing page, not buried in docs
Today the pricing page lists discount mechanics (cached, batch) and tier definitions (Turbo, Priority) but routes customers to the docs for actual per-model per-token rates. For self-serve buyers comparing Fireworks to Together AI (which lists per-model rates inline), this routing friction loses deals. Surfacing top-10-model rates directly on the pricing page would materially improve self-serve conversion.
2. $1 trial credit is too small for meaningful evaluation
Together AI typically provides $5 trial credit; Anyscale offers $100; Baseten provides variable credits that historically reached $30. Fireworks’ $1 trial covers a few thousand tokens of inference but is insufficient to evaluate even a single non-trivial RAG workflow. Increasing to $5–$25 would let self-serve developers reach proof-of-value without sales conversations and likely accelerate self-serve revenue growth.
3. A100 pricing not on the on-demand page creates a coverage gap
The on-demand dedicated page lists only H100/H200, B200, and B300 — no A100. For cost-sensitive workloads that fit comfortably on A100, customers must contact sales rather than self-serve. Publishing an A100 rate (even at a “limited availability” disclaimer) would broaden the on-demand TAM and reduce friction for non-frontier workloads.
4. No published bridge between credit-card self-serve and Enterprise commit
Self-serve customers grow into the $10K–$50K/month band before hitting the Enterprise commit tier — and there is no published mid-tier discount schedule for this band. Publishing a volume discount ladder (e.g., 10% off above $10K/mo, 15% above $25K/mo) would let mid-market customers self-qualify without sales friction and reduce churn at the boundary.
Monetization stack & signals : how Fireworks AI builds & buys its revenue engine
Buys 5 Builds 1 6 open roles
Fireworks builds the usage→revenue spine in-house — a Data Platform Engineer owns the order-to-cash pipeline on a BigQuery + dbt warehouse — but buys the pieces around it: Orb for billing, NetSuite as ERP/GL, Salesforce as CRM. The revenue org is staffing RevOps, ASC-606 revenue accounting, and growth.
-
“...build and own the end-to-end OTC data pipeline (usage → billing → payments → revenue → GL → reporting) ... usage metering and invoice generation through revenue recognition.”
-
“Proficiency in CRM and marketing automation software; Salesforce is required.”
-
“Strong SQL and BigQuery proficiency — you can design schemas, write complex analytical queries, build dbt models, and maintain production data pipelines.”
-
“...write complex analytical queries, build dbt models, and maintain production data pipelines.”
-
“You will work hands-on with our billing platform (Orb, etc).”
-
“Working knowledge of accounting systems (QuickBooks or NetSuite) and the ability to map billing events to GL journal entries, manage sub-ledger reconciliation, and support month-end close.”
- Member of Technical Staff, Data Platform Engineer Billing engineeringData platform Jun 11, 2026
- Director, Revenue Strategy & Analytics Data platformRevOpsRetention Jun 11, 2026
- Head of Marketing Operations RevOpsGrowth Jun 11, 2026
- Sales Strategy Lead RevOps Jun 11, 2026
- Paid Growth Marketer Growth Jun 11, 2026
- Revenue Accounting Lead Deal desk Jun 4, 2026
Signals reviewed · derived from public job posts, product docs
Job postings fill and close over time — once a posting is filled we keep it as a dated citation (the quoted evidence remains); use View open roles for current listings.
Key takeaways
-
Founder credibility in the runtime layer is the most durable inference-platform moat. Lin Qiao’s PyTorch leadership made Fireworks’ optimization claims believable in a way that pure-marketing positioning cannot replicate. Infrastructure commercializations that lack maintainer or core-team alignment must invest disproportionately in published benchmarks to compensate.
-
Stackable discounts (Cached + Batch) are a structural competitive moat for RAG. Independent stacking of cached input and batch discounts lets Fireworks land at 25% of standard for prefix-heavy workloads — a cost-advantage durability that competitors offering only one discount cannot match without contract negotiation.
-
Per-request QoS parameters beat tier-locked QoS. Letting customers route interactive requests through Turbo and batch through Priority within the same API key removes operational complexity and tier-negotiation friction. Other platforms still using QoS-as-tier should consider per-request parameter selection.
-
Granular fine-tuning grids capture both cost-conscious and quality-conscious buyers. The 4×4 size × method matrix lets a single rate card serve fast-iteration teams (LoRA SFT) and production-quality teams (full DPO) without forcing oversized SKU choices. Granular value-metric pricing is the canonical solution to fine-tuning rate-card design.
-
Trial credit size signals GTM mode. A $1 trial credit signals sales-led; a $100 trial signals self-serve PLG. Pricing teams should align trial credit generosity with their stated GTM strategy — mismatches confuse buyers and slow conversion.
UBP implications
-
Discount stacking is the next frontier in token-based pricing competition. When cached input becomes table stakes, the marginal differentiator shifts to which platforms stack additional discounts (batch, time-of-day, commitment). Usage-based platforms should design discount mechanics to compound independently rather than override each other.
-
Per-request QoS as an API parameter outperforms tier-locked QoS for any usage-aggregated billing surface where customers run heterogeneous workloads on the same key. The architecture should generalize beyond inference into any multi-QoS UBP product.
-
Granular fine-tuning rate cards capture more buyer segments than flat per-token training rates. The 4×4 grid (size × method) is the canonical structure; competitors with coarser fine-tuning rate cards lose cost-conscious and quality-conscious buyers simultaneously.
Sources
- Fireworks AI pricing page (accessed 2026-05-30)
- Fireworks AI docs — Serverless pricing (accessed 2026-05-30)
- Fireworks AI docs (accessed 2026-05-29)
- Fireworks blog — Series B announcement (accessed 2026-05-29)
- Fireworks blog — FireOptimizer (accessed 2026-05-29)
- Fireworks AI model library (accessed 2026-05-29)
- Related infra blueprint — Baseten
- Related infra blueprint — Anyscale
- Blueprint corpus index
Bottom line
Fireworks AI built its pricing architecture on three structural ideas: that PyTorch-team founder credibility justifies aggressive per-hour GPU pricing ($7/hr H100 is among the lowest in managed inference), that stackable discounts (cached input + Batch API) create a structural cost moat for RAG and agent-loop workloads, and that per-request QoS parameters (Turbo, Priority) eliminate the operational friction of tier-locked quality-of-service. The granular fine-tuning grid (4×4 size × method) and differential embeddings pricing (by parameter count) extend the same granularity philosophy to adjacent SKUs.
For AI engineering teams running prefix-heavy RAG workloads or evaluating between cost and quality on fine-tuning, Fireworks delivers one of the most legible commercial inference platforms in the market. The remaining gaps ($1 trial too small, per-model rates buried in docs, no published mid-market discount ladder, A100 missing from on-demand) are GTM polish problems rather than structural pricing flaws.
Compare with peers via the blueprint corpus, or model your own spend with the Fireworks AI pricing calculator.
Pricing timeline : Major events on a vertical axis
Each milestone below corresponds to a public pricing change, product launch, or material adjustment. Major events use a filled marker; minor adjustments use a faded one.
Embeddings Pricing by Parameter Size
Fireworks published differential embeddings pricing by base model parameter count: <150M params at $0.008/1M tokens, 150–350M at $0.016/1M, Qwen3 8B at $0.10/1M. The schedule undercuts OpenAI text-embedding-3-small ($0.02/1M) by 60% for the smallest tier and creates a granular cost ladder for retrieval-pipeline cost optimization.
B200 and B300 GPU Availability — Frontier Pricing
Fireworks added NVIDIA B200 (180GB) at $10.00/hr and B300 (288GB) at $12.00/hr on-demand dedicated. The H100/H200 rate remained at $7.00/hr, positioning B200/B300 as a premium for largest-model workloads while keeping Hopper-class pricing as the volume default.
Batch API at 50% Discount Across All Models
Fireworks launched a Batch API for asynchronous inference at a flat 50% discount versus serverless. Combined with cached input, batched RAG workloads can land at 25% of standard rates. The Batch API mirrors OpenAI's batch pricing structure and competes directly with Together AI's batch tier.
Turbo + Priority Tiers + Cached Input Discount
Fireworks introduced Turbo (latency-optimized) and Priority (throughput-optimized) tiers on serverless inference, with cached input tokens discounted 50% on both. The tiers let customers self-select for low-latency interactive workloads versus high-throughput batch workloads from the same API.
Series B ($52M) at $552M Valuation
Fireworks raised a $52M Series B led by Sequoia Capital at a $552M post-money valuation. Bessemer, Benchmark, and NVIDIA participated. The round funded the launch of Turbo + Priority quality-of-service tiers and the FireOptimizer auto-tuning service.
Dedicated Deployments + LoRA Fine-Tuning
Fireworks added on-demand dedicated GPU deployments (per-hour A100, H100) and LoRA-based fine-tuning. Pricing established the per-1M-training-token model that remains the canonical fine-tuning SKU, with rates scaling by base model parameter count.
Public Launch — Per-Token Serverless API
Fireworks launched its serverless API publicly, offering Llama 2, Code Llama, Mistral, and Stable Diffusion at competitive per-token rates. Pricing was a flat per-million-token rate that varied by model. Positioned as a faster, lower-cost alternative to OpenAI for open-source workloads.
Fireworks AI Founded
Lin Qiao (former PyTorch team lead at Meta), Dmytro Ivchenko, and Pawel Garbacki founded Fireworks AI to build a high-performance serving platform for open-source generative models. Initial product was a developer preview of optimized inference for Llama 2 and Stable Diffusion.
- · Fireworks AI's $7.00/hour H100 (and H200) on-demand price is one of the lowest published rates among managed inference platforms — roughly 30% below Together AI's $5.49–$6.49 H100 dedicated rates only because Together's listed rate excludes Fireworks' full-stack optimization layer.
- · Fireworks was founded in 2022 by Lin Qiao (ex-Meta), Dmytro Ivchenko, and Pawel Garbacki — Lin Qiao led the PyTorch team at Meta when PyTorch 1.0 shipped, giving Fireworks unusual inference-runtime credibility.
- · Fireworks' fine-tuning rate card is one of the most granular in the industry: LoRA SFT at $0.50 per 1M training tokens for <16B models, LoRA DPO at $1.00, full-parameter SFT at $1.00, full-parameter DPO at $2.00 — and it scales linearly through the 16B → 300B+ model size tiers.
Questions & answers
- How much does Fireworks AI cost per month?
- Fireworks has no monthly subscription fee — you pay only for serverless tokens consumed, dedicated GPU hours running, and fine-tuning training tokens processed. A small RAG application using DeepSeek V3.1 at 30M input + 10M output tokens would cost roughly $25–$30/month on serverless; the same workload on a dedicated H100 ($7/hr) running 4h/day would cost ~$840/month.
- What does Fireworks charge per GPU hour for dedicated deployments?
- Fireworks publishes three on-demand dedicated rates: H100 80GB / H200 141GB at $7.00/hour, B200 180GB at $10.00/hour, and B300 288GB at $12.00/hour. There is no published A100 rate on the on-demand page — A100 capacity is available via Enterprise commitments. Dedicated deployments include the platform optimization layer (request batching, KV cache management) on top of the GPU rate.
- How do Fireworks Turbo and Priority tiers differ?
- Turbo is latency-optimized — lower time-to-first-token and lower per-request latency, billed at a higher per-token rate than Priority. Priority is throughput-optimized — higher concurrent capacity and lower per-token cost, with slightly higher latency. Customers select per-request via API parameter; cached input discount applies to both tiers.
- Does Fireworks have a free tier?
- Yes, but it is small: new accounts receive $1 in trial credits — enough to evaluate a few thousand tokens of inference but not to run a meaningful production workload. The $1 trial is significantly smaller than Together AI's typical free credit and suggests Fireworks now relies on sales-led conversion rather than generous self-serve trials.
- How does Fireworks fine-tuning pricing work?
- Fine-tuning is priced per 1M training tokens, with rates scaling by base model parameter count and training method. For <16B models: LoRA SFT $0.50, LoRA DPO $1.00, full SFT $1.00, full DPO $2.00. For 16–80B models the schedule scales to $3–$12; 80–300B at $6–$24; >300B at $10–$40. Hosted serving of the fine-tuned model bills separately at the standard serverless or dedicated rate.
- What discounts apply to batch and cached inference?
- Batch API gets a flat 50% discount versus serverless on the same model. Cached input tokens (prompts re-using prefixes within a session window) get a 50% discount on input pricing. The two discounts compound — a batched RAG workload with high prefix re-use lands at 25% of standard rates.