AI Summary
About
Hugging Face is the de-facto home of open machine learning — often described as “the GitHub of ML.” Founded in 2016 by Clément Delangue, Julien Chaumond and Thomas Wolf, it began life as a teen-focused chatbot app (the name comes from the 🤗 hugging-face emoji) before pivoting in 2018-2019 into the open-source NLP library transformers and the model Hub that now hosts well over a million public models, hundreds of thousands of datasets, and a similar number of interactive demo “Spaces.”
The Hub is free and that is deliberate: the open corpus and community are the moat, and monetization happens around the edges. Hugging Face raised a $235M Series D in 2023 at a reported $4.5B valuation, backed by Google, NVIDIA, Amazon, Salesforce, Intel, AMD, Qualcomm and IBM — an investor list that doubles as its compute-partner list, since Inference Endpoints and Inference Providers route onto exactly those clouds and partners.
The company sits squarely in the AI-platform layer: not a single model vendor and not a raw GPU cloud, but the connective tissue between models, datasets, managed inference, and the teams that ship them. For current pricing, see Hugging Face’s pricing page.
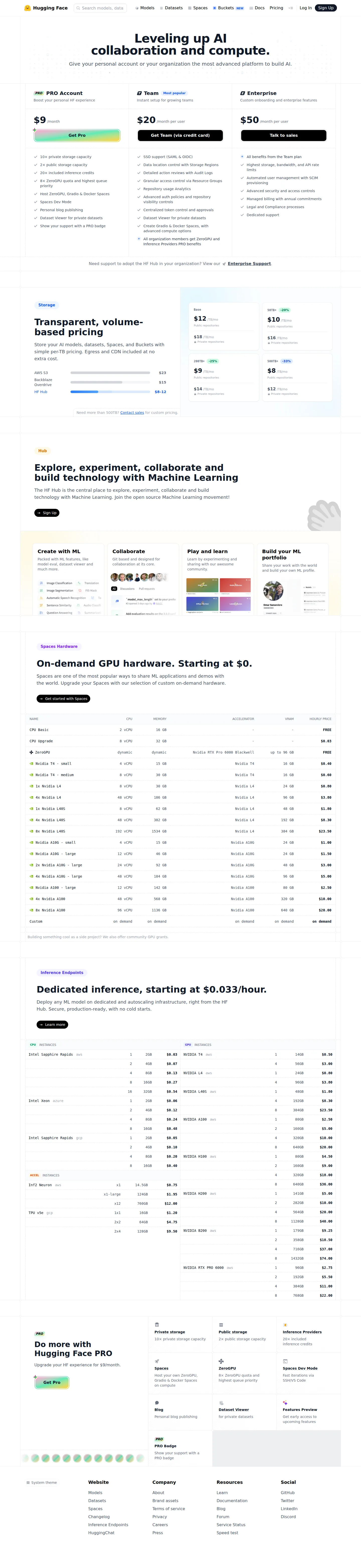
Pricing summary : How Hugging Face’s pricing model works
Hugging Face runs a hybrid model: it keeps the Hub free, then monetizes through four publicly-priced surfaces that layer on top of one another.
- Seat subscriptions — PRO at $9/mo for individuals, Team at $20/user/mo, and Enterprise at $50/user/mo. These are seat-based: they raise storage and inference quotas, unlock governance (SSO, audit logs, SCIM), and each include $2/seat of monthly Inference Providers credits (free accounts get $0.10).
- Inference Endpoints — dedicated, autoscaling managed deployments billed per-hour by instance, metered by the minute. CPU starts around $0.033/hr; GPUs span $0.50/hr (T4) up to $10.00/GPU/hr (H100 on GCP). AWS added its own H100 ($4.50/hr), plus two new Blackwell-generation options, B200 ($9.25/hr) and RTX PRO 6000 ($2.75/hr), as of the July 2026 rate card.
- Spaces hardware — per-hour GPU/CPU upgrades for hosted demos, from a $0.03/hr CPU upgrade to $23.50/hr for an 8x L40S box, with a free CPU tier and free ZeroGPU for paid accounts.
- Inference Providers — serverless, routed inference across 200+ partner models, billed pay-as-you-go per-token/request at the provider’s own rate.
What makes this different: the meter and the markup are decoupled. On Inference Providers, Hugging Face explicitly takes no markup — it charges the same rate as the underlying provider and passes it through. Hugging Face captures value from seats, dedicated endpoints, Spaces hardware, and storage instead, treating routed inference as a near-cost-price funnel that keeps developers inside its ecosystem.
Pricing by product
Seat subscriptions (per month), as of July 2026:
| Plan | Price | Inference Providers credits | Best for |
|---|---|---|---|
| HF Hub | Free | $0.10/mo | Individuals & OSS |
| PRO | $9 /mo | $2/mo | Power users |
| Team | $20 /user/mo | $2/seat/mo | Orgs needing SSO & governance |
| Enterprise | $50 /user/mo | $2/seat/mo | Security, SCIM, scale |
Inference Endpoints — dedicated managed compute, per-hour by instance (metered by the minute):
| Instance | VRAM | Price/hr | Cloud |
|---|---|---|---|
| CPU (intel-spr x1) | 2 GB | $0.033 | AWS |
| NVIDIA T4 | 14 GB | $0.50 | AWS |
| NVIDIA L4 | 24 GB | $0.80 | AWS |
| NVIDIA A10G | 24 GB | $1.00 | AWS |
| NVIDIA L40S | 48 GB | $1.80 | AWS |
| NVIDIA A100 | 80 GB | $2.50 | AWS |
| NVIDIA RTX PRO 6000 | 96 GB | $2.75 | AWS |
| NVIDIA A100 | 80 GB | $3.6 | GCP |
| NVIDIA H100 | 80 GB | $4.50 | AWS |
| NVIDIA H200 | 141 GB | $5.00 | AWS |
| NVIDIA B200 | 179 GB | $9.25 | AWS |
| NVIDIA H100 | 80 GB | $10.00 | GCP |
As of July 2026, AWS also offers its own H100 ($4.50/hr, cheaper than GCP’s $10.00/hr H100), plus two new Blackwell-generation instances — B200 ($9.25/hr) and RTX PRO 6000 ($2.75/hr) — not yet mirrored on the Inference Endpoints docs pricing table.
Spaces hardware — per-hour upgrades on hosted demos:
| Hardware | Price/hr |
|---|---|
| CPU Basic | Free |
| ZeroGPU (paid accounts, NVIDIA RTX Pro 6000 Blackwell, up to 96 GB) | Free |
| CPU Upgrade | $0.03 |
| NVIDIA T4 small | $0.40 |
| NVIDIA A10G small | $1.00 |
| NVIDIA A100 | $2.50 |
| NVIDIA L40S (8x) | $23.50 |
Team vs Enterprise — entitlement comparison (huggingface.co/enterprise)
| Dimension | Free | Team ($20/user/mo) | Enterprise (custom) |
|---|---|---|---|
| Storage regions | US only | US or EU | US or EU |
| Private storage included | 100 GB | 1 TB per seat | 1 TB per seat |
| Public storage included | Best-effort | 12 TB + 1 TB per seat | 200 TB + 1 TB per seat |
| ZeroGPU quota per member | 5 min/day | 40 min/day | 60 min/day |
| API rate limit | 1,000 req / 5 min | 3,000 req / 5 min | 6,000 req / 5 min |
| SSO (SAML & OIDC) | — | Included | Included |
| Audit logs | — | Included | Included |
| Token management | — | Review & approve | Adds revocation & service accounts |
| User provisioning (SCIM) | — | — | Included |
| Billing | Card required for compute | Self-serve, credit card or AWS Marketplace | Invoice, annual commitment |
| Priority support | — | — | Included |
Private storage beyond the included per-seat quota is billed at $18/TB/mo (with volume discounts), matching the standalone storage rate card above.
Sales motions across products: the Hub, PRO, Team, endpoints and Spaces are fully self-serve (PLG); Enterprise adds SCIM, advanced security and dedicated support with a sales-assisted motion for larger orgs. Inference Providers is pure pay-as-you-go pass-through.
Hidden costs : What Hugging Face users actually pay
The headline numbers are clean, but real bills accumulate across surfaces that are easy to forget about:
| Line item | Cost |
|---|---|
| Seat subscription | $9/mo (PRO) → $20–$50/user/mo (Team/Enterprise) |
| Inference Endpoint (e.g. 1x A100) | ~$2.50/hr → ~$1,800/mo if left running 24/7 |
| Spaces GPU upgrade left on | $0.40–$23.50/hr, billed while the Space is “running” |
| Private storage | ~$18 per TB/mo (public ~$12/TB/mo) |
| Inference Providers overage | Pay-as-you-go after the $0.10/$2-per-seat credits run out |
The biggest real-world trap is idle compute. An Inference Endpoint or an upgraded Space keeps billing per-hour whenever it is running — a single A100 endpoint left on 24/7 is roughly 1,800 USD a month, regardless of how few requests it served. Scale-to-zero helps but a zeroed endpoint still counts against quota; you have to actually pause it to stop the meter. The second is storage creep: large private models and datasets bill per-TB monthly, and the cloud-vendor spread (the same A100 is $2.50/hr on AWS vs $3.60 on GCP) means instance and region choice quietly moves the bill.
Want to estimate your own Hugging Face bill? Use the Hugging Face pricing calculator to model your costs based on plan, endpoint hours, and inference usage.
Pricing evolution : Hugging Face pricing history and changes
Cadence
| Period | Price changes | Product / SKU additions | Notes |
|---|---|---|---|
| 2023 | — | Inference Endpoints launched | Per-hour managed GPUs become a core monetization surface |
| 2024 | Seat repricing | Team / Enterprise Hub consolidated | Seat-based plans with included usage + governance |
| 2025 | — | Inference Providers (router) | Serverless Inference API → multi-provider pass-through |
| 2026 H1 | Verified, stable | — | PRO $9, Team $20, Enterprise $50; endpoints per-hour |
| 2026 H2 | — | AWS H100, B200 & RTX PRO 6000 added to Inference Endpoints | GPU catalog expansion, not a reprice: AWS H100 ($4.50/hr) undercuts GCP’s H100 ($10/hr); first Blackwell-generation hardware (B200 $9.25/hr, RTX PRO 6000 $2.75/hr); ZeroGPU discloses it runs on RTX Pro 6000 Blackwell |
Tracked range: 2023–present. Rate card verified against huggingface.co/pricing and the endpoints/providers docs on 2026-07-28.
Notable changes
- 2023 — Inference Endpoints launched as dedicated, autoscaling per-hour deployments, establishing per-hour compute (alongside Spaces hardware) as primary revenue beyond the free Hub.
- 2024 — The organization tier consolidated into seat-based Team and Enterprise Hub plans bundling SSO, audit logs, SCIM and included compute credits — the formalization of the seat-plus-usage hybrid.
- 2025 — The legacy serverless “Inference API” was rebranded HF-Inference and folded into Inference Providers, a router across 200+ partner models billed pay-as-you-go at pass-through rates with no Hugging Face markup, with monthly included credits per plan.
- 2026 H1 — Rate card holds steady: PRO $9/mo, Team $20/user/mo, Enterprise $50/user/mo, with per-hour endpoints (T4 $0.50 to H100 $10/GPU/hr) and Spaces upgrades.
- 2026-07-28 — Hugging Face added AWS NVIDIA H100 ($4.50/hr) — well under half GCP’s existing $10.00/hr H100 rate — plus its first Blackwell-generation accelerators, NVIDIA B200 ($9.25/hr) and NVIDIA RTX PRO 6000 ($2.75/hr), to the AWS Inference Endpoints catalog. Spaces’ free ZeroGPU tier also disclosed for the first time that it runs on RTX Pro 6000 Blackwell hardware.
The throughline is surface accretion: rather than reprice aggressively, Hugging Face has added monetization surfaces (endpoints, then Spaces hardware, then routed providers) around an unchanging free Hub. The July 2026 GPU catalog expansion extends that same instinct one level down: instead of opening a new billing surface, Hugging Face keeps racing hardware freshness and cloud choice within the existing per-hour Endpoints meter — adding a cheaper AWS H100 and its first Blackwell-generation cards without touching seat or Inference Providers pricing at all.
What’s unique : Hugging Face’s distinctive pricing mechanics
1. Zero-markup routed inference. On Inference Providers, Hugging Face charges the exact provider rate and passes it through — a rare “we don’t mark up the meter” stance that turns serverless inference into a funnel rather than a profit center.
2. Four meters, one account. Seats, dedicated per-hour endpoints, per-hour Spaces hardware, and per-token routed inference all bill through a single account with shared org billing — a genuinely hybrid model spanning subscription, pure-usage compute, and pass-through token pricing.
3. Credits that meter the free tier. Even free accounts get a tiny $0.10/mo inference allowance ($2/seat on paid plans), quietly making the famously free Hub a metered top-of-funnel that converts to pay-as-you-go.
Strengths & weaknesses
| Strengths | Weaknesses |
|---|---|
| Fully public, itemized rate card across every surface | Four separate meters make total cost hard to predict |
| No markup on routed Inference Providers | Idle endpoints/Spaces keep billing per-hour |
| Generous free Hub as the on-ramp | No free dedicated GPU; card required for endpoints |
| Per-minute billing on endpoints | Cloud-vendor spread (AWS vs GCP) pushed to the buyer |
| Seat plans bundle governance + usage credits | Storage costs creep with large private repos |
Billing UX : Hugging Face billing controls and transparency
- Billing controls — Per-hour endpoints metered by the minute; scale-to-zero and explicit pause to stop the meter; Team/Enterprise admins can set spending limits and disable specific Inference Providers org-wide.
- Usage visibility — A billing page and an Inference Providers usage breakdown show spend for the past month by model and provider; organizations get the same view at the org level.
- Payment options — Self-serve card checkout for subscriptions, endpoints and Spaces; centralized organization billing via the
X-HF-Bill-Toheader so individual seats consume a shared pool; Enterprise supports invoicing and dedicated support. PRO is $9/mo, Team $20/user/mo, Enterprise $50/user/mo.
Strategic wins : Why Hugging Face’s pricing decisions worked
1. Keeping the Hub free to own the on-ramp
By never charging for the core model/dataset/Spaces Hub, Hugging Face made itself the default first stop for anyone building with open models — then monetized the compute and governance around it. See how AI companies structure pricing.
2. Pass-through inference as a funnel, not a margin
Routing 200+ models at zero markup removes the reason to integrate providers directly, consolidating developer attention (and eventually endpoint and seat spend) inside Hugging Face. Related: outcome-based pricing trends.
3. Layering per-hour compute over a free base
Per-hour endpoints and Spaces hardware convert free Hub engagement into metered revenue without a paywall on the core experience — a clean example of choosing the right place to put the meter. See choosing the right usage metric.
Areas to improve : Gaps in Hugging Face’s pricing approach
1. Four meters are hard to forecast
Seats plus per-hour endpoints plus per-hour Spaces plus per-token routed inference make a unified monthly estimate genuinely difficult; a built-in cross-surface cost estimator would reduce surprise. See bill shock and cost unpredictability.
2. Idle-compute traps
Endpoints and upgraded Spaces bill per-hour whenever running, and scale-to-zero still counts against quota until paused — clearer auto-pause defaults and idle warnings would prevent silent overruns.
3. Cloud-spread opacity
Surfacing the AWS-vs-GCP price gap directly to buyers is honest but confusing, and the gap is widening: A100 sits at $2.50 (AWS) vs $3.60 (GCP), a roughly 44% spread, but as of the July 2026 AWS H100 addition, that same H100 chip now runs $4.50/hr on AWS versus $10.00/hr on GCP — more than double depending purely on which cloud a buyer happens to pick. A “cheapest available instance” recommendation would help teams optimize instead of quietly overpaying by cloud choice alone.
Monetization stack & signals : how Hugging Face builds & buys its revenue engine
Buys 2 Builds 1
Buys payments (Stripe) but builds the meter itself: a first-party Billing API runs compute and pass-through inference through a shared credit-and-threshold ledger, settling one monthly invoice — and third-party providers (Fal, Novita) integrate HF's meter to bill PAYG. No public ATS, so the hiring read is unavailable.
-
“For Inference Providers who have built support for our Billing API (currently: Fal, Novita, HF-Inference – with more coming soon), we've started enabling Pay as you go (=PAYG).”
-
“Hugging Face uses Stripe to securely process your payment information.”
-
“You also have the option to link your Hugging Face organization to your AWS account via AWS Marketplace. Hugging Face compute service usage will then be included in your AWS bill.”
Signals reviewed · derived from engineering blogs, product docs
Key takeaways
- Hugging Face is a hybrid model — seat subscriptions ($9/$20/$50) plus per-hour compute plus pass-through per-token inference, all on a free Hub. For the underlying model, see the introduction to usage-based pricing.
- The free Hub is the strategy, not a loss leader — it owns the on-ramp and everything paid layers on top.
- Inference Providers takes no markup — routed inference is a funnel that keeps developers in-ecosystem rather than a profit center.
- Per-hour endpoints and Spaces are the real meters — and idle compute, not headline rates, is the biggest hidden cost.
- Surface accretion over repricing — Hugging Face grows revenue by adding monetization surfaces (endpoints → Spaces → providers) around an unchanging free core.
UBP implications
- A free core can coexist with multiple paid meters. Hugging Face shows you can keep the headline product free and still monetize through seats, per-hour compute, and pass-through usage layered around it.
- Zero markup can be a strategic price. Charging cost-price for routed inference sacrifices margin on one surface to defend the funnel and capture spend on higher-margin surfaces.
- Per-minute metering plus pause controls manage usage risk both ways. Fine-grained billing rewards efficient users, but the vendor must pair it with visible idle/pause controls or usage-based pricing becomes bill-shock pricing.
Sources
- Hugging Face pricing (accessed 2026-07-28)
- Inference Endpoints pricing (docs) (accessed 2026-07-28)
- Inference Providers pricing & billing (docs) (accessed 2026-07-28)
- Hugging Face PRO (accessed 2026-07-28)
- Hugging Face Hub billing (docs) (accessed 2026-07-28)
- Hugging Face Series D announcement (accessed 2026-06-15)
Bottom line
Hugging Face is the clearest example of a hybrid AI-platform pricing model: a free model/dataset Hub that monetizes through seat subscriptions (PRO $9/mo, Team $20 and Enterprise $50 per user/mo), per-hour dedicated Inference Endpoints (T4 $0.50 up to H100 $10/GPU/hr), per-hour Spaces hardware, and pass-through per-token Inference Providers with no markup. The strategy is to keep the core free, own the developer on-ramp, and layer multiple meters around it — which is also its main weakness, since four billing surfaces and idle per-hour compute make total cost hard to forecast. Browse the pricing blueprint for more fully-researched company profiles, or compare Hugging Face against other Infrastructure, Compute & MLOps companies.
Pricing timeline : Major events on a vertical axis
Each milestone below corresponds to a public pricing change, product launch, or material adjustment. Major events use a filled marker; minor adjustments use a faded one.
AWS adds H100 and first Blackwell GPUs (B200, RTX PRO 6000) to Inference Endpoints
Hugging Face expanded the AWS instance catalog behind Inference Endpoints with NVIDIA H100 ($4.50/hr, undercutting GCP's $10/hr H100 by more than half) plus its first Blackwell-generation accelerators, B200 ($9.25/hr) and RTX PRO 6000 ($2.75/hr); Spaces' free ZeroGPU tier also disclosed for the first time that it runs on RTX Pro 6000 Blackwell hardware.
Current rate card verified
PRO $9/mo, Team $20/user/mo, Enterprise $50/user/mo (each with $2/seat Inference Providers credits). Endpoints per-hour: T4 $0.50, A100 $2.50, H100 $10/GPU/hr (GCP), H200 $5. Spaces: CPU upgrade $0.03/hr to L40S 8x $23.50/hr. Storage $12/$18 per TB/mo.
Inference Providers replaces the serverless Inference API
The old serverless 'Inference API' was rebranded HF-Inference and folded into Inference Providers — a router across 200+ partner models billed pay-as-you-go at pass-through rates with no HF markup, plus monthly included credits per plan.
Enterprise Hub repriced to per-seat with included usage
The organization tier consolidated into seat-based Team/Enterprise plans (around $20-$50 per user/mo) bundling governance (SSO, audit logs, SCIM) and included compute credits, formalizing the seat-plus-usage hybrid.
Inference Endpoints launched; per-hour managed GPUs
Hugging Face moved managed inference to dedicated per-hour Inference Endpoints across CPU and GPU instances, alongside per-hour Spaces hardware upgrades, establishing per-hour compute as a primary monetization surface beyond the free Hub.
- · Hugging Face started in 2016 as a teen-focused chatbot app — the name comes from the 🤗 emoji — before pivoting to become the GitHub of machine learning, now hosting well over a million public models.
- · For Inference Providers, Hugging Face takes no markup at all: it charges the exact provider rate and passes it through, monetizing instead via subscriptions, dedicated endpoints, and Spaces hardware.
- · Every account, even free ones, gets a small monthly inference allowance — $0.10 for free users, $2 per seat on paid plans — that quietly turns the free Hub into a metered top-of-funnel.
Questions & answers
- How does Hugging Face's pricing work?
- Hugging Face keeps the core Hub (models, datasets, Spaces) free and charges through four surfaces. PRO ($9/mo) and Team/Enterprise ($20 and $50 per user/mo) are seat subscriptions that lift quotas and add governance. Inference Endpoints bill per-hour by instance for dedicated managed deployments. Spaces hardware bills per-hour for GPU/CPU upgrades. Inference Providers bills pay-as-you-go per-token/request, passed through to partner providers with no HF markup.
- How much does Hugging Face PRO cost?
- As of June 2026, PRO is $9/month for an individual. It raises private and public storage limits, gives 20x inference credits and 8x ZeroGPU quota, and includes $2/month of Inference Providers credits. Team plans are $20/user/mo and Enterprise is $50/user/mo, both seat-based.
- How much does it cost to run a GPU on Hugging Face Inference Endpoints?
- Inference Endpoints are billed per-hour by instance, metered by the minute. As of July 2026, an NVIDIA T4 starts at $0.50/hr, L4 at $0.80, A10G at $1.00, A100 at $2.50/hr on AWS (or $3.60 on GCP), H200 at $5.00, and an H100 at $10.00/GPU/hr on GCP. AWS separately added its own H100 at $4.50/hr plus two Blackwell-generation cards, RTX PRO 6000 at $2.75/hr and B200 at $9.25/hr. CPU endpoints start at about $0.033/hr. Endpoints require an active subscription and a card on file; there is no free GPU endpoint.
- Does Hugging Face have a free tier?
- Yes. The Hub itself is free with unlimited public models, datasets and Spaces, a free CPU Spaces tier, and $0.10/month of Inference Providers credits. Paid compute (Inference Endpoints, Spaces GPU upgrades) and subscriptions sit on top of that free base. There is no free dedicated GPU.
- Does Hugging Face mark up inference pricing?
- No. For Inference Providers, Hugging Face explicitly charges the same rates as the underlying provider and passes the cost through with no markup. You consume your monthly credits first ($0.10 free, $2/seat on paid plans), then pay-as-you-go by purchasing additional credits.