AI Summary
About
Hyperbolic (Hyperbolic Labs) is a San Francisco-based “open-access AI cloud” founded in 2023 by Jasper Zhang (CEO) and Yuchen Jin (CTO). It now sells compute across four surfaces on a pure pay-as-you-go basis: On-Demand GPUs (hourly, full SSH/root, no commitment), Reserved GPUs (the same hardware prepaid for a fixed term at a discount), Private Cloud (single-tenant, custom contract), and a Serverless Inference API that runs open-weight models (Llama, Qwen, DeepSeek and more) billed per million tokens. The self-serve surfaces are publicly priced with no subscription or seat minimum — buyers purchase compute credits and draw them down by usage.
Hyperbolic’s distinguishing idea is a DePIN-style supply model: rather than build out its own data centers, it aggregates underused GPU capacity from third-party data centers and operators and resells it, which lets it refresh per-hour rates weekly as supply shifts. The company raised roughly $20M total — a seed round around $7M in July 2024 and a $12M Series A in December 2024 led by Variant and Polychain Capital. It reports 200,000+ engineers on the platform and 25+ open-source models served via API, and it is one of Hugging Face’s third-party inference providers. Customers and references include Hugging Face, Quora, Cornell, UC Berkeley, the LMSYS Chatbot Arena, and Reve AI.
For current pricing, see the on-demand and reserved GPU page, the serverless inference page, and the billing docs. Hyperbolic sits in the AI infrastructure and compute category alongside GPU-cloud rivals and open-model inference hosts.
Pricing summary : GPU-hours, per-million-token inference and prepaid credits
Hyperbolic is pure usage-based across four surfaces with two headline value metrics and a prepaid-credit wallet underneath. There are no subscription tiers, seats, or platform fees — you buy compute credits and every meter draws them down.
- On-Demand GPUs — billed per GPU-hour, hourly for the life of the instance. Published starting rates (July 2026): H100 SXM $2.89, H200 $3.49, B200 $5.99 per GPU-hour, with the wider catalog advertised from $0.20/GPU/hr. Rates are refreshed weekly based on the best available rates from suppliers, but the rate displayed at instance creation is locked for that instance’s lifetime. No minimum commitment, no hidden or egress fees.
- Reserved — the same GPUs and setup at a discounted prepaid $/GPU/hour, paid in full up front for a fixed term. 1-month minimum, with self-serve terms available from 1 week to 1 month; no early termination.
- Private Cloud — dedicated single-tenant infrastructure on a custom contract, negotiated per deal on multi-month to multi-year commitments and billed separately from credits.
- Serverless Inference — billed per million tokens against open-weight models. Each model carries its own rate, from $0.10/M for small Llama models up to $4.00/M for Llama-3.1-405B. Storage volumes attached to instances are metered separately, hourly per GB of provisioned capacity.
Compute credits carry a $5 minimum purchase, are always 1:1 with the dollar amount, and never expire. That $5 is also the account gate: the default Free tier carries no minimum spend but may not launch GPU instances or storage volumes, and a one-time $5 deposit automatically promotes the account to Pro, which unlocks them. To launch an on-demand instance your balance must then cover at least one hour of runtime across all instances; there is no minimum charge beyond that.
What makes this different: two value metrics serve two buyers from one wallet — infrastructure teams that want raw GPU-hours for training and custom serving, and developers that want a per-token serverless API without managing GPUs. And unlike a pure spot market, Hyperbolic pairs weekly, supplier-driven rate refreshes with a per-instance price lock, so the number you saw at launch is the number you keep paying — a hybrid of marketplace pricing and committed-use discounting.
Pricing by product
Hyperbolic sells GPU compute in three commitment shapes plus a serverless token API. Starting rates below are the published on-demand figures as of July 2026; rates are refreshed weekly and vary by region and availability.
GPU compute (commitment shapes)
| Surface | Price | Included | Key mechanics |
|---|---|---|---|
| On-Demand | $/GPU/hour, from $0.20/GPU/hr | Full SSH / root (VM or bare metal); 8–128+ GPU clusters; up to 24 TB local NVMe; 99.5% uptime SLA | No minimum commitment; billed hourly for the life of the instance; rate locked at creation |
| Reserved | Discounted prepaid $/GPU/hour | Same GPUs, networking and setup as On-Demand at a lower rate; 99.5% uptime SLA | Paid in full up front; 1-month minimum (self-serve terms from 1 week to 1 month); no early termination |
| Private Cloud | Custom contract | Single-tenant, network isolation, optional managed Kubernetes / Slurm; custom SLA; dedicated direct-to-engineer support 24×7 | Sales-led; multi-month to multi-year; billed separately, not from credits |
| Storage volumes | Hourly, per GB of provisioned capacity | Network storage that lives independently of instances; attachable network storage advertised at ~$0.0766/TB/month | Billed on total volume size regardless of capacity used or data transferred; terminate anytime |
On-Demand GPU starting rates (per GPU-hour)
| GPU | Starting price | Included | Key mechanics |
|---|---|---|---|
| NVIDIA B200 | $5.99 /GPU-hr | Blackwell, 192 GB HBM3e, 8 TB/s memory bandwidth | Frontier-scale training and highest-throughput inference |
| NVIDIA H200 | $3.49 /GPU-hr | Hopper, 141 GB HBM3e, 4.8 TB/s memory bandwidth | Large-model training and memory-bound inference |
| NVIDIA H100 SXM | $2.89 /GPU-hr | Hopper, 80 GB HBM3, 3.35 TB/s memory bandwidth | Mainstream training, fine-tuning and inference |
| Wider GPU catalog | Advertised “from $0.20 /GPU/hr” | Marketplace feature copy still names RTX 4090, RTX 3080 and RTX 3070, but the on-demand docs list only “H100 80GB, H200 141GB, and B200 192GB” | No consumer-GPU per-card rate is published anywhere, and no card at or near $0.20/GPU/hr appeared in the live console — treat $0.20 as a marketing floor, not a bookable rate, and check app.hyperbolic.ai/gpus |
Rates are “refreshed weekly based on the best available rates from suppliers on our platform”, so the per-hour price is dynamic. Node configuration for H100 / H200 is 8 GPUs per node with up to 160 vCPUs, 1.5 TB RAM and 24 TB local NVMe; multi-node clusters use Ethernet or InfiniBand (up to 3.2 Tb/s, NDR / ConnectX-7). Hourly billing carries no hidden or egress fees, and failed instances are never charged.
Serverless Inference (per million tokens)
| Model | Price | Included | Key mechanics |
|---|---|---|---|
| Llama-3.2-3B / Llama-3.1-8B / Llama 3.1 8B (BF16) - Base | $0.10 /1M tokens | Full-precision (BF16) open weights via OpenAI-compatible API | Smallest, cheapest open models |
| Qwen2.5-Coder-32B | $0.20 /1M tokens | Code-specialized mid-size model | Cheapest coding endpoint on the card |
| Llama-3.1-70B / Llama-3-70B / Qwen2.5-72B / Qwen2-VL-72B-Instruct / Hermes-3-70B | $0.40 /1M tokens | 70B-class general and vision-language models | The volume tier of the rate card — five SKUs at one price |
| DeepSeek-V2.5 | $2.00 /1M tokens | Larger reasoning / MoE model | 5× the 70B rate |
| Llama-3.1-405B | $4.00 /1M tokens | Frontier-scale open model | 40× the small-Llama rate |
Each model has its own per-million-token rate; larger models cost more per token. The pricing block also carries Text-Image, VLM and Text-Audio tabs, but those tabs currently throw a client-side error on hyperbolic.ai/inference, so their per-generation rates are unknown from the public page. Serverless inference has no minimum commitment and a 99.9% SLA.
Account tiers (rate limits and platform access, not token prices)
| Tier | Pricing model | Included | Key mechanics |
|---|---|---|---|
| Free (marketed as “Basic”) | No minimum spend | 60 RPM rate limit; 100 IP address limit; full precision (BF16) SOTA open-source models; full control over data | Default plan for new accounts — but “you may not launch GPU instances nor storage volumes with a free-tier account” |
| Pro | Pay-as-you-go | 600 RPM rate limit; 100 IP address limit; same model access as Free, plus GPU instances and storage volumes | ”You must deposit at least $5 one-time to automatically become a pro-tier user” — 10× the request rate at the same per-token price |
| Enterprise | Custom hourly pricing billed by GPU type | Unlimited rate limit and unlimited IP limit; SOTA open-source models plus custom models; dedicated instances; fine-tuning services | Dedicated support “Available Upon Request”; sales-led — “Contact Us” |
Tiers gate request rate and platform access, not the published token price — every tier pays the same per-million-token rate card. The one-time $5 credit deposit is what converts a Free account into a Pro account, so it doubles as the GPU-rental entry ticket. Dedicated model hosting is single-tenant GPU instances with private endpoints, billed hourly with unlimited requests.
Sales motions across products: self-serve / PLG for On-Demand GPUs, Reserved (up to 1 month) and Serverless Inference on the Free/Pro account tiers; sales-led for Private Cloud, large reserved commitments and the Enterprise tier.
Hidden costs : What Hyperbolic users actually pay
Hyperbolic’s headline rates are clean pay-as-you-go, but a few items shape the real bill:
| Line item | Cost |
|---|---|
| GPU-hour (e.g. 8× H100 SXM node) | $2.89/GPU/hr → ~$23.12/hr for the node |
| Inference tokens | Per-model, $0.10–$4.00 /1M tokens |
| Storage volumes | Hourly, per GB of provisioned capacity — billed on total volume size regardless of what you actually use |
| Credit purchase floor | $5 minimum per compute-credit purchase |
| Launch balance requirement | Must hold enough credit to cover 1 hour of runtime across all instances |
| Weekly rate drift | Published per-hour rate can move week to week for new instances |
| Reserved / Private Cloud | Prepaid in full, or sales-quoted per contract |
Three real-world cost drivers stand out. First, the headline price is a moving target for new instances: rates refresh weekly off supplier availability, so the rate you budgeted can shift before your next launch — though the price lock means a running instance keeps the rate it started at. Second, storage is billed on provisioned size, not usage — a large volume attached “just in case” bills at full size hourly whether or not you fill it. Third, because supply is aggregated from third parties, capacity and reliability vary by GPU type and region; teams that need guaranteed capacity are steered to Reserved (prepaid, no early termination) or Private Cloud (custom contract). Hyperbolic offsets some of the risk with ready-state billing — instances that never become ready are never charged, and failed reserved instances are refunded in full.
Want to estimate your own Hyperbolic bill? Use the Hyperbolic pricing calculator to model your costs based on GPU type, hours, and token volume.
Pricing evolution : Hyperbolic pricing history and changes
Cadence
| Period | Price changes | Product / SKU additions | Notes |
|---|---|---|---|
| 2024 H2 | — | GPU marketplace + serverless inference live | H100 advertised from ~$0.99/hr post-Series A |
| 2025 | Per-model inference rate card stabilized | Image (SDXL, FLUX), VLM, audio modalities added | 70B-class at $0.40/M; 405B at $4.00/M |
| 2026 Q2 | Marketplace starting rates published | Reserved clusters, dedicated hosting | H100 from $1.50/hr; weekly supplier-rate refresh |
| 2026 Q3 | 3 (H100, H200, B200 starting rates all reset upward) | Private Cloud, Reserved self-serve, storage volumes, Auto Top-Up | H100 SXM to $2.89, H200 $3.49, B200 $5.99; consumer-GPU per-hour rates pulled from the page; catalog floor advertised at $0.20/GPU/hr |
Tracked range: 2024–present. Published GPU rates are dynamic (weekly supplier-rate refresh), so point-in-time figures reflect the capture date.
Notable changes
- Late 2024 — After a $12M Series A (Dec 2024, led by Variant and Polychain), both surfaces were live; early marketing advertised H100 rental from roughly $0.99/hr and per-million-token open-model inference.
- 2025 — Inference settled into a per-model rate card (3B–8B Llama at $0.10/M, 70B-class at $0.40/M, DeepSeek-V2.5 at $2.00/M, Llama-3.1-405B at $4.00/M), with image, VLM, and audio modalities added.
- June 2026 — Marketplace published on-demand starting rates (H100 SXM $1.50, H200 $2.40, B200 $3.50, RTX 4090 $0.30, RTX 3070 $0.16), refreshed weekly from supplier rates.
- July 2026 — Published starting rates reset sharply upward: H100 SXM $2.89, H200 $3.49, B200 $5.99 per GPU-hour, with the consumer-GPU per-hour rates removed from the page in favour of a “from $0.20/GPU/hr” catalog floor. Packaging is now four surfaces (On-Demand, Reserved, Private Cloud, Serverless Inference) with prepaid compute credits ($5 minimum, never expiring), Auto Top-Up, per-instance price lock, separately metered storage volumes, and 99.5% / 99.9% uptime SLAs. Serverless per-million-token rates are unchanged.
The July 2026 rate reset in detail
Between the 15 June and 21 July 2026 captures, every published on-demand starting rate moved up at once: H100 SXM $1.50 → $2.89 (+93%), H200 $2.40 → $3.49 (+45%), B200 $3.50 → $5.99 (+71%). Nothing about the pricing mechanism changed — the page still says rates are “refreshed weekly based on the best available rates from suppliers” — which is precisely the point: a marketplace rate that floats with aggregated third-party supply can float upward as hard as it floats down, and it does so without a repricing announcement, a migration path, or a grandfathering policy, because none of those artefacts exist in a spot model.
Who actually paid the increase is the more useful question. Because the per-instance price lock holds the rate shown at instance creation for that instance’s life, a team already running an H100 job through the June rate kept $1.50/hr; the +93% applies only to the next launch. That splits the buyer population cleanly: long-running workloads absorbed nothing, while burst and experiment traffic — the buyers most attracted by a $1.50 headline — saw their unit cost nearly double between one launch and the next. The two mitigations Hyperbolic ships against exactly that risk (the price lock, and self-serve Reserved terms starting at one week) both reward buyers who commit, so the practical effect of the reset is to push price-sensitive users off pure on-demand and onto the commitment ladder.
The delisting compounds it for the low end. RTX 4090 at $0.30 and RTX 3070 at $0.16 were the cheapest verifiable numbers on the page; replacing them with a “from $0.20/GPU/hr” catalog floor leaves the budget tier priced but no longer checkable without signing in — a step back from the published-rate posture that is otherwise Hyperbolic’s clearest differentiator. Serverless inference, by contrast, did not move a cent: the $0.10–$4.00 per-million-token card is identical across both captures, which is the sharpest available evidence that Hyperbolic deliberately runs a volatile meter and a stable meter side by side.
The direction of travel is therefore a maturing four-surface cloud rather than a cheap-GPU marketplace: published per-hour rates that float weekly with supplier supply but lock per instance, a commitment ladder that now starts self-serve at one week and runs to multi-year Private Cloud contracts, and a stable per-token inference rate card sitting on top.
What’s unique : Hyperbolic’s distinctive pricing mechanics
1. Two value metrics, one account. Hyperbolic prices GPU-hours on the marketplace and per-million-tokens on serverless inference from a single prepaid balance — serving infra teams and API developers without forcing either into the other’s billing model.
2. Weekly-refreshed, supplier-driven marketplace rates that move both ways. Because it aggregates third-party GPU supply (a DePIN model), Hyperbolic refreshes per-hour rates weekly off the best available supplier prices — a spot price rather than a fixed list price, which is unusual for raw-GPU rental. July 2026 showed what that means in practice: H100 SXM went from $1.50 to $2.89/GPU/hr in five weeks with no announcement, because a marketplace rate has no announcement to make.
3. Published rates plus a documented price lock — and the lock is the load-bearing half. Hyperbolic publishes both per-GPU-hour starting rates and per-model token rates openly (no sales call to see numbers), and then locks the per-hour rate shown at instance creation for that instance’s whole lifetime. In a stable market that reads as a nicety; after the July 2026 reset it is the actual product, because it is the only thing that stopped a +93% supplier repricing from landing on workloads already in flight. The documented exception is equally telling — Hyperbolic reserves the right to ask for an increase on instances running “at significantly below-market rates for a long time”, so the lock is a shock absorber, not a perpetual grandfather clause.
4. A commitment ladder that starts at one week. Reserved capacity is now self-serve in-app from one week to one month at a discounted prepaid rate, with larger terms and single-tenant Private Cloud going through sales. Most GPU clouds jump straight from hourly to annual contracts; a one-week prepaid step lets a buyer buy predictability for a single training run rather than a fiscal year — which is exactly the escape hatch a weekly-floating on-demand rate creates demand for.
Strengths & weaknesses
| Strengths | Weaknesses |
|---|---|
| Transparent per-GPU-hour and per-token rates, published without a sales call | Published rates can reset hard between checks — H100 SXM +93% in five weeks (Jun→Jul 2026) |
| Per-instance price lock kept in-flight workloads on their original rate through the July 2026 reset | Only three GPUs still carry a published per-hour rate; the “from $0.20/GPU/hr” floor is no longer verifiable on the page |
| Serverless token card held steady while GPU rates moved — predictability where developers need it | Aggregated third-party supply can vary in capacity and reliability by GPU and region |
| Commitment ladder is self-serve from one week, not just annual contracts | Reserved is prepaid in full with no early termination; Private Cloud is sales-quoted and billed outside credits |
| Two value metrics from one never-expiring prepaid balance, with Auto Top-Up | The Free tier is API-only — it cannot launch GPU instances or storage volumes until a one-time $5 deposit promotes the account to Pro, on top of a 1-hour runtime balance floor |
| OpenAI-compatible API, zero data retention on inference | Storage bills on provisioned size, and image/audio per-generation rates are absent from the pricing page |
Billing UX : prepaid compute credits, price lock and Auto Top-Up
- Compute credits — the account wallet. Purchasable at any time with a $5 minimum, always 1:1 with the dollar amount purchased, held as a positive balance, and they never expire. Deposit from the dashboard (“Deposit” in the upper-right), then complete checkout.
- Account tier is set by deposit, not by a plan picker — new accounts land on the Free tier (no minimum spend, 60 RPM, 100 IP addresses) which “may not launch GPU instances nor storage volumes”. Depositing at least $5 one-time automatically promotes the account to Pro (600 RPM, full platform access, pay-as-you-go); Enterprise is custom-quoted with unlimited limits. The per-million-token rate card is identical on all three.
- Auto Top-Up — configure a balance threshold (“When my balance goes below…”) and a top-up amount (“Automatically add…”) against a stored default payment method. Hyperbolic evaluates the balance every 10 minutes, uses a backoff strategy on failed charges, and warns that it “may miss massive spikes of usage that rapidly deplete your balance within that timeframe”; it recommends a threshold of 72h of usage and a top-up of 24h of usage.
- Price lock — “the cost per hour per GPU displayed during instance creation is locked in for the duration of the instance”, with one stated exception: Hyperbolic “may reach out about a price increase if you have had on-demand instances running at significantly below-market rates for a long time”.
- Balance requirements — before creating an on-demand instance your balance must cover at least one hour of runtime across all your instances, including the new one. There is no minimum charge — you may terminate at any time, including before the instance becomes ready.
- Ready-state billing — billing starts the moment an instance is fully provisioned and SSH-accessible. Anything that fails to become ready inside the ~3-hour provisioning timeout is auto-terminated and never charged; a failed reserved instance is refunded in full to your balance immediately. The marketplace page also promises notification “within 3 minutes if an instance fails”.
- Four separate meters on one balance — serverless inference (per API call), GPU instances (on-demand hourly / reserved up-front), and storage volumes (hourly, per GB of capacity) all draw down credits. Private Cloud is billed separately under contract, not from credits.
- Zero-balance consequences, spelled out — at zero or negative balance you may be unable to launch instances, running instances may be terminated, and storage volumes are terminated after a 30-day grace period to recover data.
- Public list pricing — per-GPU-hour starting rates and the per-model token card are published rather than gated behind a sales call; only Reserved rates, Private Cloud and the Enterprise inference tier are quoted.
- Payment methods — “pay with wire / ACH upfront or monthly, or pay as you go via credit card / stripe.”
Strategic wins : Why Hyperbolic’s pricing decisions worked
1. Framing the rate card as a marketplace, not a list price
By reselling underused third-party GPU capacity at openly published, weekly-refreshed rates, Hyperbolic got the visibility of a public rate card without the commitment of a list price — a wedge into the price-sensitive AI-research and indie-developer segment. July 2026 proved the second half of that trade: raising H100 SXM 93%, H200 45% and B200 71% in a single refresh required no price-increase notice, no grandfathering scheme and no customer email, because “refreshed weekly from supplier rates” had already set the expectation. Very few vendors can reprice that steeply without a trust event; framing the meter as a market is what buys that room. See how AI companies structure pricing.
2. Two value metrics that capture two buyers
Pricing GPU-hours for infra teams and per-million-tokens for API developers from one account lets Hyperbolic monetize both the “I want raw compute” and the “I just want a model endpoint” buyer without making either adopt the other’s mental model. Related: outcome-based pricing trends.
3. A stable token rate card on top of a spot GPU market
Layering a fixed per-model inference rate card over a fluctuating spot GPU marketplace gives developers predictability where they want it (token price) while letting raw compute float with supply. The July 2026 capture is the cleanest proof that this is a deliberate split rather than an accident of timing: GPU-hour rates rose 45–93% in the same week that the $0.10–$4.00 per-million-token card stayed byte-for-byte identical. An application team building on the inference API felt nothing; a team renting bare H100s repriced. See choosing the right usage metric.
Areas to improve : Gaps in Hyperbolic’s pricing approach
1. Weekly rate drift is now a budgeting hazard, not a footnote
A rate that refreshes weekly is fine for short bursts, but the June-to-July 2026 move (H100 SXM $1.50 → $2.89) shows the drift can be large enough to invalidate a quarter’s capacity plan between two launches of the same job. The price lock protects instances already running and self-serve Reserved now buys a fixed rate from one week out, which covers a single training run — but neither helps a buyer who needs a forward number for a budget they must approve before any instance exists. Publishing a rolling rate history per GPU, or a short forward quote a buyer can hold for a few days, would close the gap between “transparent today” and “plannable next month”. See bill shock and cost unpredictability.
2. Delisting the consumer GPUs weakened the transparency claim
Pulling the RTX 4090 ($0.30) and RTX 3070 ($0.16) per-hour rates in July 2026 removed the only published numbers that substantiated the new “from $0.20/GPU/hr” catalog floor — the cheapest tier is now advertised but not checkable without signing in. That is the wrong direction for a vendor whose main differentiator against gated GPU clouds is that you can read the price. Restoring per-card starting rates for the full catalog, even with an explicit “refreshed weekly” caveat, would make the floor claim verifiable again.
3. Unpublished image/audio rates
Inference token rates are published, but per-generation image (SDXL, FLUX) and audio rates are not shown on the pricing page — and the modality tabs that should carry them currently fail to load, so a buyer cannot reach the numbers at all from the public surface. Rendering those rates as plain text alongside the token card, rather than behind interactive tabs, would extend the transparency that benefits the token products and make the rates survivable when the app misbehaves.
4. Capacity and reliability transparency
Because supply is aggregated from third parties, capacity and reliability can vary by GPU and region. Real-time availability and SLA clarity (without a sales call) would reduce the gap between a self-serve rate card and a self-serve experience.
Monetization stack & signals : how Hyperbolic builds & buys its revenue engine
Buys 0 Builds 1 2 open roles
Hyperbolic builds billing in-house — no monetization vendor is named. A platform engineer role owning billing, metering and usage tracking plus a Head of Finance running billing and reconciliation point to a self-built revenue engine atop its prepaid-credit core.
-
“Familiarity with billing systems, metering, usage tracking, and quota enforcement mechanisms”
- Staff Software Engineer - Platform/Infrastructure Billing engineering Jun 18, 2026
- Head of Finance RevOps Jun 18, 2026
Signals reviewed · derived from public job posts
Job postings fill and close over time — once a posting is filled we keep it as a dated citation (the quoted evidence remains); use View open roles for current listings.
Key takeaways
- Hyperbolic is pure usage-based across four surfaces — On-Demand, Reserved and Private Cloud GPUs billed per GPU-hour, plus serverless inference billed per million tokens — with no subscription or seat anywhere in the model. For the underlying model, see the introduction to usage-based pricing.
- A spot meter buys pricing freedom, and Hyperbolic used it — because rates are framed as weekly supplier refreshes rather than a list price, H100 SXM could move $1.50 → $2.89 (+93%) in July 2026 without a repricing announcement or a grandfathering scheme.
- A per-instance price lock is what makes a floating rate sellable — the lock kept running workloads on their pre-reset rate, so the increase landed only on new launches; without it, a 93% move would have been a churn event rather than a line-item change.
- The real frictions are rate drift and supply variability, not headline fees; teams that need a knowable number move to prepaid Reserved capacity (self-serve from one week) or a sales-quoted Private Cloud contract.
- Delisting prices is a costlier move than raising them — pulling the consumer-GPU per-hour rates left a “from $0.20/GPU/hr” claim no buyer can verify on the page, which erodes exactly the transparency that justified the open rate card in the first place.
UBP implications
- A spot meter and a fixed meter can coexist — and July 2026 is the receipt. Hyperbolic raised GPU-hour rates 45–93% in the same refresh that left its $0.10–$4.00 per-million-token card untouched, pricing each metric the way its supply behaves. Any business with both volatile and stable cost inputs can run the same split, so long as buyers can tell which meter they are standing on.
- Two value metrics widen the addressable buyer set. Offering raw GPU-hours and a per-token API from one account lets a vendor monetize both the infrastructure buyer and the application developer without forcing a single billing model.
- Transparency is a wedge, but it is measured on the worst number you publish. Documenting the price lock, balance requirements and zero-balance consequences in the open lowers buyer friction against rivals that hide pricing behind sales calls — yet the same July 2026 update that raised three published rates also removed two, replacing checkable consumer-GPU prices with an unverifiable “from” floor. A rate card earns trust by staying complete through a price rise, not by being complete when prices are falling.
Sources
- Hyperbolic On-Demand and Reserved GPU pricing (accessed 2026-07-21)
- Hyperbolic Serverless Inference pricing (accessed 2026-07-21)
- Hyperbolic docs — GPU pricing (On-Demand, Reserved, Private Cloud, Storage Volumes) (accessed 2026-07-21)
- Hyperbolic docs — Billing and Payments (accessed 2026-07-21)
- Hyperbolic docs — Auto Top-Up (accessed 2026-07-21)
- Hyperbolic docs — Platform Comparison (accessed 2026-07-21)
- Hyperbolic docs — Account Management (Free / Pro / Enterprise account tiers) (accessed 2026-07-21)
- Hyperbolic docs — On-Demand GPUs overview (available GPU types) (accessed 2026-07-21)
- Hyperbolic console — live GPU rates and availability (accessed 2026-07-21)
- Hyperbolic — account setup (accessed 2026-07-21)
- Hyperbolic secures $20M total funding with Series A (accessed 2026-06-15)
Bottom line
Hyperbolic is a clean example of pure usage-based pricing for AI compute: GPUs billed per GPU-hour (H100 SXM from $2.89/hr, refreshed weekly off aggregated third-party supply) across three commitment shapes — On-Demand, prepaid Reserved, and contracted Private Cloud — alongside a serverless inference API billed per million tokens ($0.10–$4.00/M across open models). Everything self-serve draws down never-expiring prepaid compute credits, and the rate shown at instance creation is locked for that instance’s life. That lock did real work in July 2026, when the published H100 SXM rate jumped 93% in five weeks and the increase landed only on new launches — the clearest illustration of the bargain on offer here, which is a genuinely open rate card in exchange for a rate that can move sharply between one job and the next. The other trade-offs are storage billed on provisioned rather than used capacity, a cheapest tier now advertised as “from $0.20/GPU/hr” without per-card rates to check it against, and supply that varies by GPU and region — which steers reliability-sensitive and budget-bound teams toward Reserved or Private Cloud. Browse the pricing blueprint for more fully-researched company profiles, or compare Hyperbolic against other AI infrastructure and compute companies.
Pricing timeline : Major events on a vertical axis
Each milestone below corresponds to a public pricing change, product launch, or material adjustment. Major events use a filled marker; minor adjustments use a faded one.
GPU rates reset upward; four-surface platform with prepaid credits
Published on-demand starting rates move to H100 SXM $2.89, H200 $3.49 and B200 $5.99 per GPU-hour (catalog advertised from $0.20/GPU/hr), and the consumer-GPU per-hour rates are pulled from the page. Packaging is now four surfaces — On-Demand, Reserved, Private Cloud and Serverless Inference — funded by prepaid compute credits (minimum $5, never expiring) with Auto Top-Up, a per-instance price lock, and 99.5%/99.9% uptime SLAs. Serverless token rates are unchanged.
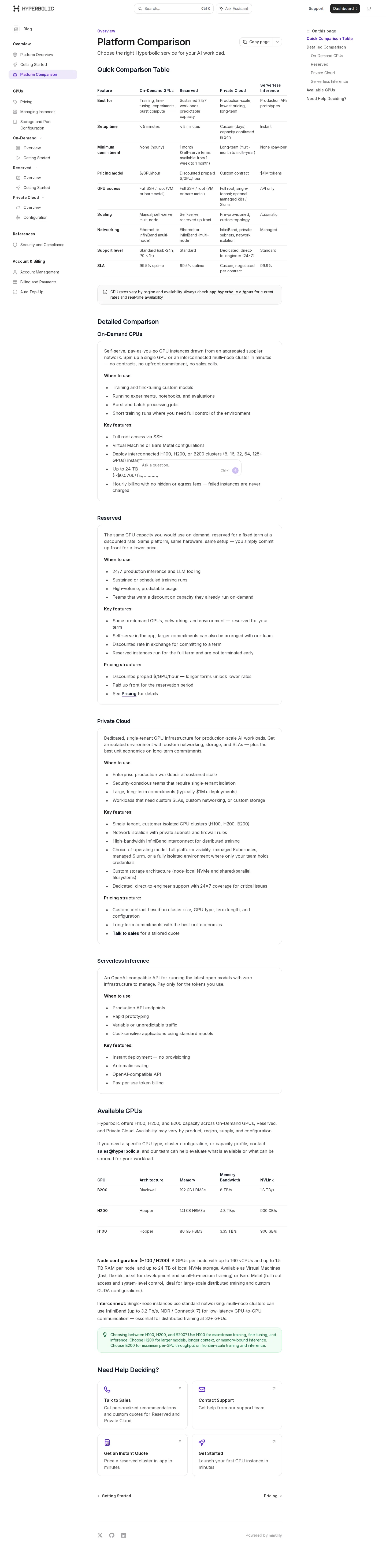
Marketplace starting rates published; H100 from $1.50/hr
GPU marketplace shows on-demand starting rates: H100 SXM $1.50, H200 $2.40, B200 $3.50, RTX 4090 $0.30, RTX 3070 $0.16 per GPU-hour, refreshed weekly from supplier rates. Inference rate card unchanged.
Per-million-token inference rate card stabilizes
Inference settled into a per-model rate card: $0.10/M for 3B-8B Llama, $0.40/M for 70B-class models, $2.00/M for DeepSeek-V2.5, and $4.00/M for Llama-3.1-405B, with image (SDXL, FLUX) and audio modalities added.
Two usage surfaces live; H100 advertised from ~$0.99/hr
After its $12M Series A (Dec 2024), Hyperbolic offered both a GPU marketplace and a serverless inference API. Early marketing cited H100 rental from roughly $0.99/hr, with open-model inference billed per million tokens.
- · Hyperbolic prices two different value metrics from one account: GPU-hours on its marketplace and per-million-tokens on serverless inference.
- · It runs a DePIN-style model — aggregating underused GPU capacity from third-party data centers and operators — and accepts wire/ACH upfront or monthly as well as pay-as-you-go card payments.
- · Marketplace GPU rates are refreshed weekly based on the best available supplier rates, but the per-hour rate shown when you create an instance is then locked for that instance's whole lifetime.
Questions & answers
- What is Hyperbolic's pricing model?
- Pure usage-based, pay-as-you-go. Hyperbolic bills per GPU-hour on On-Demand and Reserved GPUs and per million tokens on its serverless inference API, with storage volumes billed hourly per GB. There are no subscription tiers or seat fees — you buy compute credits and draw them down by consumption. Private Cloud is a negotiated custom contract billed separately.
- How much does an H100 cost on Hyperbolic?
- As of July 2026, an NVIDIA H100 SXM starts at $2.89/GPU/hr, H200 at $3.49, and B200 at $5.99 per GPU-hour, with the wider catalog advertised from $0.20/GPU/hr. Rates are refreshed weekly based on the best available supplier rates, so the per-hour price is dynamic and can move a long way: the published H100 SXM rate was $1.50/GPU/hr in June 2026, so it rose 93% in about five weeks. The rate displayed when you create an instance is locked for that instance's lifetime, so a refresh only affects your next launch.
- How is Hyperbolic's inference pricing charged?
- Serverless inference is billed per million tokens, with each open-weight model carrying its own rate: $0.10/M for Llama-3.1-8B and Llama-3.2-3B, $0.20/M for Qwen2.5-Coder-32B, $0.40/M for 70B-class models like Llama-3.1-70B and Qwen2.5-72B, $2.00/M for DeepSeek-V2.5, and $4.00/M for Llama-3.1-405B. You pay only for the tokens you consume.
- Does Hyperbolic have a free tier?
- Yes, but it is API-only. Hyperbolic's account docs define a Free tier as the default plan for new accounts with no minimum spend required, capped at 60 requests per minute and 100 IP addresses — the same limits the inference page markets as its Basic tier. Free-tier accounts may not launch GPU instances or storage volumes; a one-time $5 deposit automatically upgrades you to Pro (600 RPM) and unlocks them. Compute credits are 1:1 with the dollar amount and never expire, and there is no published free token allowance.
- What is Hyperbolic's price lock?
- The cost per hour per GPU displayed during instance creation is locked in for the duration of that instance. Hyperbolic reserves one exception: in rare circumstances it may reach out about a price increase if you have had on-demand instances running at significantly below-market rates for a long time.