AI Summary
About
Mistral AI is a Paris-based foundation-model company that builds open-weight and commercial large language models, plus the consumer/team AI assistant now branded Vibe (formerly Le Chat). It serves two distinct buyers from one pricing page: developers who call models over a per-token API (la Plateforme / Mistral Studio), and individuals and teams who subscribe to the Vibe assistant for chat, search, image generation, and agentic coding. Enterprise deployments — private, self-hosted, or on-prem with custom models — are sold separately through a sales motion.
Founded in April 2023 by ex-DeepMind and ex-Meta researchers Arthur Mensch, Guillaume Lample, and Timothée Lacroix, Mistral has become Europe’s flagship foundation-model lab. It raised a €1.7B Series C in September 2025 led by chip-equipment maker ASML, valuing the company at roughly $14B, with prior backing from Andreessen Horowitz, Lightspeed, General Catalyst, Nvidia, and France’s Bpifrance. Its EU base is itself a positioning asset — Mistral sells “sovereign AI” with regional data-processing controls to financial-services, public-sector, and manufacturing customers (ASML, CMA CGM, HSBC, BMW are named references).
The model catalog spans open-weight families (Mistral Large 3, Mistral Small 4, Ministral, Mixtral, Devstral, Magistral, Voxtral) and premier models (Mistral Medium 3.5, Codestral, OCR 4, Magistral Medium). Open models carry permissive licenses (Apache 2.0 / modified MIT) for research and individual use, while commercial production deployments require a Mistral license — a positioning that differentiates Mistral from closed-weight competitors like OpenAI and Anthropic. That open-weight strategy is the strategic anchor of the whole price sheet: you can download the weights for free, but Mistral monetizes hosted inference per token on la Plateforme and packages a managed assistant on top.
Pricing summary : subscription assistant plus pure per-token API
Mistral AI runs a two-track model: flat-rate freemium subscriptions for the Vibe assistant (formerly Le Chat) and pure usage-based pricing for the developer API, billed per million tokens. The dimensions are:
- Vibe assistant seats — Free ($0), Pro ($14.99/mo), Team ($24.99/user/mo with a $50/mo block for extra users), Enterprise (custom). A discounted student plan is $5.99/mo.
- API tokens — separate input and output rates per million tokens, varying by model (e.g. Mistral Small 4 at $0.15 in / $0.6 out up to Mistral Medium 3.5 at $1.5 in / $7.5 out). Batch processing gets a 50% discount.
- Non-token API units — OCR 4 billed per 1,000 pages ($4, or $5 with Document AI), audio per minute or per 1k characters, and tool calls (web search, code execution, image generation, premium news) billed per 1,000 calls/images.
- Fine-tuning — per-token training cost plus a per-model-per-month storage fee, with a minimum fee per job.
- PAYG overage — Vibe subscribers can extend past plan limits by paying at API rate (“Extend usage with PAYG credits”).
What makes this different: Mistral exposes raw per-million-token billing publicly across 30+ open and premier models — the same metering primitive whether you self-serve the API or buy the consumer assistant — rather than burying inference cost inside opaque seat tiers.
Pricing by product
Vibe assistant (formerly Le Chat) — consumer & team plans
| Tier | Price | Included | Key mechanics |
|---|---|---|---|
| Free | $0 | Web + mobile access to SOTA models; limited messages, web searches, and coding sessions; image generation; 100+ connectors | Entry point for the AI assistant |
| Pro | $14.99 / mo | More messages & web searches, all-day coding (CLI, IDE, web), up to 40× image generations, chat & email support | ”Popular” tier; subject to fair-usage limits |
| Education | $5.99 / mo | Same as Pro | Verified students at accredited institutions; max 12 months; new users only |
| Team | $24.99 / user/mo | Everything in Pro plus up to 30GB storage/user, domain verification, data export, Admin API, SAML SSO | Add user blocks at $50/mo via the Users stepper |
| Enterprise | Contact us | Custom models, agents & workflows; audit logs; SAML SSO; white label; self-host / private cloud / on-prem | Sales-led, quoted |
API — text & reasoning models (per million tokens, USD)
| Model | Input /M | Output /M | Key mechanics |
|---|---|---|---|
| Mistral Small 4 | $0.15 | $0.6 | Open, Apache 2.0; cost-sensitive default |
| Mistral Large 3 | $0.5 | $1.5 | Open-weight flagship, multimodal |
| Mistral Medium 3.5 | $1.5 | $7.5 | Premier flagship; coding + reasoning |
| Magistral Medium | $2 | $5 | Premier reasoning model |
| Magistral Small | $0.5 | $1.5 | Lightweight reasoning |
| Devstral 2 (medium) | $0.4 | $2 | Agentic coding |
| Devstral Small 2 | $0.1 | $0.3 | Lightweight coding agent |
| Codestral | $0.3 | $0.9 | Low-latency code completion |
| Ministral 3B / 8B / 14B | $0.1 / $0.15 / $0.2 | $0.1 / $0.15 / $0.2 | Edge models; flat in/out rate |
| Mistral NeMo | $0.15 | $0.15 | Open lightweight |
| Mixtral 8x7B | $0.7 | $0.7 | Open SMoE |
| Mistral Embed / Codestral Embed | $0.1 / $0.15 | — | Embeddings (input only) |
| Mistral Moderation | $0.1 | — | Content classifier |
Batch processing gets a 50% discount on token rates.
API — non-token units & tools (USD)
| Service | Price | Key mechanics |
|---|---|---|
| OCR 4 | $4 / 1,000 pages ($5 / 1,000 with Document AI) | Document extraction |
| Voxtral TTS | $0.016 / 1k characters | Text-to-speech |
| Voxtral Mini Transcribe 2 | $0.003 / min ($0.006 / min realtime) | Transcription |
| Voxtral Small (audio + text) | $0.004 audio + $0.1 text in / $0.4 out | Speech understanding |
| Web search | $30 / 1,000 calls | Agent tool |
| Code execution | $30 / 1,000 calls | Agent tool |
| Image generation | $100 / 1,000 images | Agent tool |
| Premium news | $50 / 1,000 calls | Agent tool |
| Libraries | OCR $3/1K pages + indexing $1/M tok + $0.01/call | Document store for agents |
| Fine-tuning (classifier) | $1/M tokens training, $2/mo per model storage, min $4/job | One-off training + storage |
Sales motions across products: PLG / self-serve for the Vibe Free, Pro, Education, and Team plans and the entire pay-as-you-go API; sales-led for Enterprise deployments and Enterprise APIs (regional data controls, SLAs, premium support).
Hidden costs : What Mistral AI users actually pay
Mistral’s headline rates are unusually transparent, but the real bill is shaped by three things the tier prices don’t show: the output-token premium on premier models, the separately-billed agent tools, and the Team seat-block stepper. Two archetypes show how the total assembles.
Archetype 1 — a developer running a document-extraction + RAG agent on the API. Processing 5,000 PDF pages a day with OCR 4, then answering questions with Mistral Medium 3.5 (assume ~2M input + ~0.5M output tokens/day), plus 10,000 web-search tool calls a month.
| Line item | Monthly cost |
|---|---|
| OCR 4 — 150,000 pages @ $4 / 1,000 | $600 |
| Mistral Medium 3.5 input — ~60M tok @ $1.5/M | $90 |
| Mistral Medium 3.5 output — ~15M tok @ $7.5/M | $112.50 |
| Web search tool — 10,000 calls @ $30 / 1,000 | $300 |
| Estimated total | ~$1,102.50/mo |
The lesson: on Medium 3.5 the $7.5/M output rate is 5× the input rate, so output-heavy workloads (long answers, code generation) dominate — and the agent tools (web search, code execution at $30/1k calls, image generation at $100/1k) are billed entirely outside the token meter. A 50% batch discount can roughly halve the token lines if the workload tolerates asynchronous processing.
Archetype 2 — a 12-person team on Vibe Team. Twelve seats at $24.99/user/mo, with two users routinely exceeding their plan message and coding limits and extending via PAYG credits at API rate.
| Line item | Monthly cost |
|---|---|
| Vibe Team — 12 seats @ $24.99 | $299.88 |
| PAYG overage credits (2 heavy users, est.) | ~$40 |
| Estimated total | ~$340/mo |
Here the surprise is mild by design: instead of a hard block at the plan ceiling, Vibe lets heavy users “extend usage with PAYG credits” at API rate, so a team’s bill flexes upward gradually rather than forcing an Enterprise upsell. Storage (up to 30GB/user) is bundled, not metered.
Want to estimate your own Mistral AI bill? Use the Mistral AI pricing calculator to model your costs based on token volume, agent-tool calls, and seat count.
Pricing evolution : Mistral AI pricing history and changes
Mistral’s pricing has evolved along two tracks. The API has billed per million tokens since la Plateforme opened in late 2023, and its headline rates held remarkably stable — until July 2026, when Mistral pushed through its first token-rate increases (Small 4, OCR, transcription) while leaving the Vibe consumer ladder untouched. The consumer side, meanwhile, went from free-only to a paid subscription ladder, then rebranded into an agent platform. The dated milestones below are reconstructed from primary announcements and contemporaneous press; quarter-level cadence will be tightened with archived snapshots on a later pass.
Cadence
| Quarter | Price changes | Product / SKU additions | Notes |
|---|---|---|---|
| 2023 Q3 | 1 | 1 | La Plateforme API launches with per-million-token input/output pricing |
| 2024 Q1 | 0 | 1 | Le Chat assistant launches free; no paid consumer SKU yet |
| 2025 Q1 | 1 | 1 | 2025-02-06 Le Chat mobile apps + Pro subscription at $14.99/mo introduced |
| 2025 Q2 | 0 | 1 | Le Chat Enterprise launches (custom-priced, Google Cloud Marketplace) |
| 2026 Q2 | 0 | 1 | 2026-05 Le Chat rebrands to Vibe; tier prices carry over, assistant becomes a work + code agent |
| 2026 Q3 | 3 | 0 | 2026-07-06 first API-side price increases: Mistral Small 4 $0.1/$0.3 → $0.15/$0.6, OCR 4 $2 → $4/1K pages, Voxtral Mini Transcribe 2 $0.002 → $0.003/min; Vibe consumer ladder held flat |
Tracked range: 2023 Q3–2026 Q3. Quarters not listed had no publicly announced price or SKU change. Dated milestones below cite primary/secondary sources; per-snapshot price reconstruction is a later pass.
Notable changes
- 2023-09 — La Plateforme API opens with per-million-token billing, establishing token metering before any subscription existed (Mistral docs).
- 2024-02 — Le Chat launches free, positioned as a privacy-focused European alternative to ChatGPT.
- 2025-02-06 — Pro tier introduced at $14.99/mo alongside iOS/Android apps — a deliberate undercut of ChatGPT Plus ($20/mo) (reported by Maginative and TechCrunch).
- 2025-05 — Le Chat Enterprise launches with private deployments, SSO, and audit logs; distributed via Google Cloud Marketplace.
- 2025-09 — €1.7B Series C led by ASML at a ~$14B valuation funds the data-center and enterprise push (reported by CNBC).
- 2026-05 — Le Chat rebrands to Vibe and adds Work Mode + Code Mode (CLI/IDE coding via Devstral); the Free / Pro $14.99 / Team $24.99 / Enterprise ladder carries over (reported by VentureBeat; confirmed on Mistral’s help center).
- 2026-07-06 — First developer-API price increase: Mistral Small 4 rises from $0.1/$0.3 to $0.15 in / $0.6 out per M tokens (a 50% input, 100% output bump), the document model upgrades to OCR 4 at $4/1,000 pages ($5 with Document AI, up from OCR 3 at $2/$3), and Voxtral Mini Transcribe 2 moves to $0.003/min with a new $0.006/min realtime variant. The Vibe consumer ladder and the flagship/agent-tool rates held flat; API pricing and Enterprise deployments also graduated from in-page tabs to their own URLs (/pricing/api/, /pricing/enterprise-deployments).
The Le Chat → Vibe rebrand in detail
The May 2026 rebrand was a repositioning, not a repricing. Tier names and prices stayed put — Free, Pro at $14.99/mo, Team at $24.99/user/mo, Enterprise on request — but the product shifted from “chat window” to autonomous work-and-code agent: a Work Mode that plugs into Google Workspace, Outlook, SharePoint, Slack, and GitHub, and a Code Mode that spins up isolated cloud environments to write code and open pull requests via Devstral. The pricing implication is that the same flat seat now buys far more agentic compute, which Mistral absorbs by routing overage through PAYG credits at API rate rather than raising the sticker price — a bet that bundling agent capability into the existing tiers wins share faster than charging for it.
What’s unique : Mistral AI’s distinctive pricing mechanics
1. Open weights, metered inference. Mistral gives away the model weights — Mistral Small 4 under Apache 2.0, Mistral Medium 3.5 under a modified MIT license — yet charges per token to call them on its hosted API. The price you pay isn’t for the model, it’s for managed inference, fine-tuning storage, and the surrounding tooling. This decouples the open-source goodwill from the revenue line and lets enterprises self-host the same weights they could buy as a service, a hedge against lock-in that closed-weight rivals can’t match.
2. One meter, two products. The same per-million-token primitive prices both the developer API and the consumer Vibe assistant. When a Vibe subscriber exceeds their plan, the overage is billed at API rate via “extend usage with PAYG credits” — so the consumer subscription and the developer API are not separate pricing systems but two packagings of one meter. Few AI vendors expose the underlying token economics this directly to consumer buyers.
3. EU-sovereign packaging as a price-able dimension. Mistral sells regional data-processing controls, system-level SLAs, and premium support as “Enterprise APIs” — turning data residency and sovereignty into a quoted upgrade rather than a free compliance checkbox. For European financial-services and public-sector buyers, that positioning is itself the value metric.
4. Agent tools billed outside the token meter. Web search ($30/1k calls), code execution ($30/1k), image generation ($100/1k images), and premium news ($50/1k) are priced per action, not per token. As Vibe becomes an agent platform, these per-action fees — not raw inference — become the variable cost that scales with agentic usage, a structural shift toward outcome-shaped pricing.
Strengths & weaknesses
| Strengths | Weaknesses |
|---|---|
| Fully public per-million-token rates across 30+ models — no “contact sales” wall for inference | Output-token premium on premier models (Medium 3.5 at $7.5/M, 5× input) can surprise output-heavy workloads |
| Open weights let buyers self-host the same models, a credible lock-in hedge | Agent tools (search, code exec, images) billed separately from tokens — total cost is harder to predict than the headline rate implies |
| Pro at $14.99 deliberately undercuts ChatGPT Plus ($20) and Claude Pro ($20) | Vibe plan limits are “subject to fair usage” rather than published hard quotas — opacity on the consumer side |
| PAYG overage at API rate avoids hard blocks and forced Enterprise upsells | Fine-tuning carries a monthly per-model storage charge ($2/mo) that accrues even when the model is idle |
| EU data-residency and sovereignty packaged as a sellable Enterprise dimension | Enterprise (deployments + Enterprise APIs) is fully sales-gated — no public floor price |
| 50% batch discount and edge models (Ministral, $0.1/M flat) keep cost-sensitive workloads cheap | Frequent rebrands (Le Chat → Vibe) and model renames make historical price tracking harder |
Billing UX : usage tracking and overage controls
- Mistral Studio usage dashboard — detailed tracking of API usage with metrics for calls, endpoints, and user activity, breaking down cost by service (completion, OCR, fine-tuning) to monitor and optimize consumption.
- Extend usage with PAYG credits — Vibe subscribers can keep going past their plan limit by paying only for what they use beyond it, charged at API rate rather than being hard-blocked.
- Per-seat add controls (Team) — a
$50/mo / Usersstepper lets Team admins add user blocks on top of the $24.99/user/mo base; pricing updates live as seats are added. - Model training opt-out — every plan exposes a “Model training: Opt-out” control over whether data is used for training.
- Currency toggle — the pricing page offers a USD ($) / EUR (€) switch; prices are shown excluding taxes.
- Admin API (Team/Enterprise) — programmatic management of users, teams, and permissions; Enterprise adds audit logs and data export for compliance tracking.
- Fine-tuning cost controls — per-model storage is billed monthly irrespective of usage, and models can be deleted any time to stop the storage charge; a minimum $4 fee applies per fine-tuning job.
Strategic wins : Why Mistral AI’s pricing decisions worked
1. Pricing the service, not the model
By open-sourcing the weights and charging only for hosted inference, fine-tuning, and tooling, Mistral turned its biggest cost — model R&D — into a marketing asset rather than a paywalled product. Developers evangelize the open models; enterprises pay for managed inference and sovereignty. This separates goodwill from revenue and is the inverse of the closed-weight playbook. See usage-based pricing strategy for why metering the delivery rather than the artifact scales.
2. A deliberate $5 undercut on the consumer tier
Launching Pro at $14.99/mo against ChatGPT Plus and Claude Pro at $20 gave Mistral a clean price story for European buyers without racing to free. The $5 gap is small enough to protect margin but large enough to headline, and it anchors Mistral as the value option in a market where the leaders converged on $20. This mirrors the shift away from rigid per-user licensing toward flexible, value-anchored consumer pricing.
3. One meter spanning developer and consumer
Reusing the per-token API meter as the overage mechanism for consumer subscriptions (“extend usage with PAYG credits at API rate”) means Mistral maintains a single billing primitive instead of two disconnected systems. It lets power users on Vibe spill over gracefully and keeps the economics legible. Choosing one durable usage metric early is a discipline most multi-product vendors learn too late.
Areas to improve : Gaps in Mistral AI’s pricing approach
1. Publish hard quotas, not just “fair usage”
The Vibe consumer tiers gate features behind “subject to fair usage limits” rather than stating message, search, or coding caps numerically. That opacity invites exactly the bill-shock and unpredictability anxiety usage pricing is supposed to remove. A concrete per-tier quota table — even approximate — would let buyers self-select without fear of silent throttling.
2. Surface agent-tool costs in the headline
Web search, code execution, and image generation are billed per action ($30–$100 per 1,000) entirely outside the token rate. As Vibe becomes an agent platform, these dominate cost for agentic workloads but are buried below the model table. A combined “estimated cost per agent run” view in Mistral Studio would make total cost predictable before a customer commits.
3. Expose an Enterprise floor or starting point
Both Enterprise deployments and the Enterprise APIs are fully sales-gated with no public anchor. A published starting price or a worked example (as some peers do) would shorten the evaluation cycle for mid-market buyers who can’t justify a sales call but outgrow the Team plan. Compare how other AI companies stage their enterprise transparency.
Monetization stack & signals : how Mistral AI builds & buys its revenue engine
Buys 4 Builds 0 13 open roles
Mistral is firmly buy-not-build on the revenue engine: a Lago case study confirms it chose Lago to meter and bill its paid API and Vibe products rather than build billing in-house ("instead of building a billing system from scratch … Mistral reached out to us"), runs payments through several Stripe accounts, and an internal "SAP Platform Lead" role names Lago, Kyriba, Pigment and Payflows as the SAP-integrated finance systems. Investment is concentrated on the commercial org rather than billing engineering: a dedicated "Product Monetisation & Pricing Lead" plus monetization-leaning product roles (Cloud Partnerships, Mistral Vibe), seven RevOps "Solution Operations" hires standardizing on Salesforce + Looker, and a very large customer-success build-out (~30 AI Deployment Strategist / solutions / enterprise-support roles) reflecting the enterprise/sovereign-deployment sales motion.
-
“Instead of building a billing system from scratch (which can be a nightmare), Mistral reached out to us to power the billing for their paid products.”
-
“Mistral has several Stripe Payments accounts and we helped them connect to them seamlessly.”
- SAP Revenue recognition inferred Job post Jan 2026
“Lead the integration of SAP with key business systems (Kyriba, Pigment, Lago, Payflows, etc.), ensuring data consistency and process automation”
-
“Strong analytical skills, with experience in Salesforce, data warehouses, and BI tools (e.g., Looker, Hex, BigQuery)”
- Product Monetisation & Pricing Lead Monetization Jun 1, 2026
- Product Manager, Cloud Partnerships Monetization Jun 1, 2026
- Product Manager, Mistral Vibe Monetization Jun 1, 2026
- Product Operations Manager Monetization Jun 1, 2026
- AI Deployment Strategist (Paris / London / Singapore / USA / EMEA) Customer success May 27, 2026
- Technical Support Engineer, Enterprise Customer success May 27, 2026
- Partner Solution Architect - EMEA Customer success May 27, 2026
- Solution Operations Manager, Revenue Growth RevOps seen Apr 30, 2026
- Solution Operations Manager, People Growth RevOps seen Apr 30, 2026
- Solution Operations Manager - Singapore RevOps seen Apr 30, 2026
- Product Manager, AI Studio Growth seen Mar 12, 2026
- Product Marketing Manager, Solutions Growth seen Mar 12, 2026
- Senior Product Marketing Manager - Studio Growth seen Mar 12, 2026
- +35 more matched roles
Signals reviewed · derived from public job posts, press & filings
Job postings fill and close over time — once a posting is filled we keep it as a dated citation (the quoted evidence remains); use View open roles for current listings.
Key takeaways
- Give away the artifact, charge for the delivery. Open-sourcing the weights and metering hosted inference turns R&D into distribution and keeps the revenue line on managed service. The free thing seeds adoption; the paid thing is operational convenience and sovereignty.
- One meter beats two systems. Reusing the per-token API rate as the consumer overage mechanism keeps billing legible and avoids building a second pricing engine. Pick a durable value metric and let every product packaging route through it.
- A small, headline-able undercut can anchor a category. Mistral’s $14.99 vs $20 gap is deliberate: large enough to lead with, small enough to protect margin. Price relative to the reference competitor, not to zero — and when costs rise, defend the visible anchor by taking the increase elsewhere: in July 2026 Mistral held the Vibe $14.99/$24.99 ladder flat and pushed its first price rise onto the developer API (Small 4 to $0.15/$0.6, OCR 4 to $4/1K) instead.
- Graceful overflow beats hard caps. Letting subscribers “extend with PAYG credits at API rate” converts a churn moment (hitting a wall) into incremental revenue, without forcing a premature Enterprise upsell.
- Package compliance as a product. Turning EU data residency and SLAs into a quoted Enterprise dimension monetizes regulatory positioning that competitors give away as a checkbox.
UBP implications
- Tokens are the universal AI meter — and they can surface all the way to consumers. Mistral shows that the same per-million-token primitive that prices a developer API can also meter consumer-subscription overage, collapsing two pricing systems into one. UBP practitioners should look for the single underlying unit that every packaging can route through.
- Open weights reshape the value question from “what” to “where.” When the model is free to download, the priced dimension becomes hosting, fine-tuning storage, and compliance — not the model itself. UBP design has to follow the cost driver that customers can’t trivially replicate, not the headline artifact.
- Agent platforms push the meter from tokens toward actions. As assistants become agents, per-action tool fees (search, code execution, images) become the variable cost that scales with value delivered — an early signal of the move from token-based toward outcome-shaped pricing that UBP strategists should plan for.
Sources
- Mistral AI pricing page — Vibe assistant plans (accessed 2026-07-06)
- Mistral AI pricing page — API per-token rates (accessed 2026-07-06)
- Mistral AI pricing page — Enterprise deployments (accessed 2026-07-06)
- Mistral AI documentation (accessed 2026-07-06)
- Mistral AI Help Center — “Le Chat is now Vibe” (accessed 2026-05-31)
- Mistral AI Help Center — student/teacher Education-plan discount (accessed 2026-07-06)
- Mistral AI news / blog (accessed 2026-07-06)
- Browse the pricing blueprint corpus
Bottom line
Mistral AI prices two surfaces from one meter: a freemium Vibe assistant ($0–$24.99/user/mo) and a fully public per-token API spanning 30+ open and premier models. The open-weight strategy turns model R&D into distribution and keeps revenue on hosted inference, fine-tuning, and EU-sovereign packaging — a structurally different bet from the closed-weight $20-a-seat consensus. The main friction is opacity on consumer fair-usage limits and sales-gated enterprise; the strongest move is letting the same token rate gracefully absorb overage instead of hard-blocking users.
Want to compare Mistral AI against other foundation-model providers? See OpenAI and Perplexity AI, or browse the full pricing blueprint.
Pricing timeline : Major events on a vertical axis
Each milestone below corresponds to a public pricing change, product launch, or material adjustment. Major events use a filled marker; minor adjustments use a faded one.
API rates rise: Mistral Small 4 to $0.15/$0.6, OCR 4 to $4/1K pages
Live capture shows API-side price increases while Vibe consumer plans hold: Mistral Small 4 moves from $0.1/$0.3 to $0.15/$0.6 per M tokens, and the OCR model (now OCR 4) jumps from $2 to $4 per 1,000 pages ($5 with Document AI). Voxtral Mini Transcribe 2 is $0.003/min ($0.006 realtime). Vibe Free/$14.99 Pro/$24.99 Team/Enterprise and the $5.99 student plan are unchanged. API pricing and Enterprise deployments moved from #tabs to their own URLs (/pricing/api/, /pricing/enterprise-deployments).
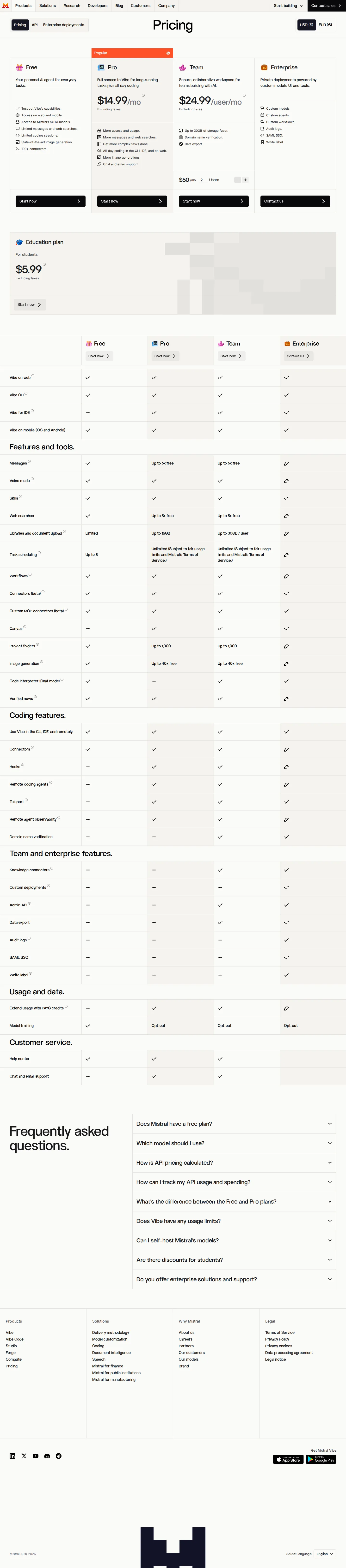
Live snapshot: Vibe plans + per-token API across 30+ models
Captured live USD pricing: Vibe Free/$14.99 Pro/$24.99 Team/Enterprise, student $5.99; API per-million-token rates across 30+ models (Mistral Small 4 $0.1/$0.3 to Medium 3.5 $1.5/$7.5); OCR, audio, embeddings, agent tools, and fine-tuning units.
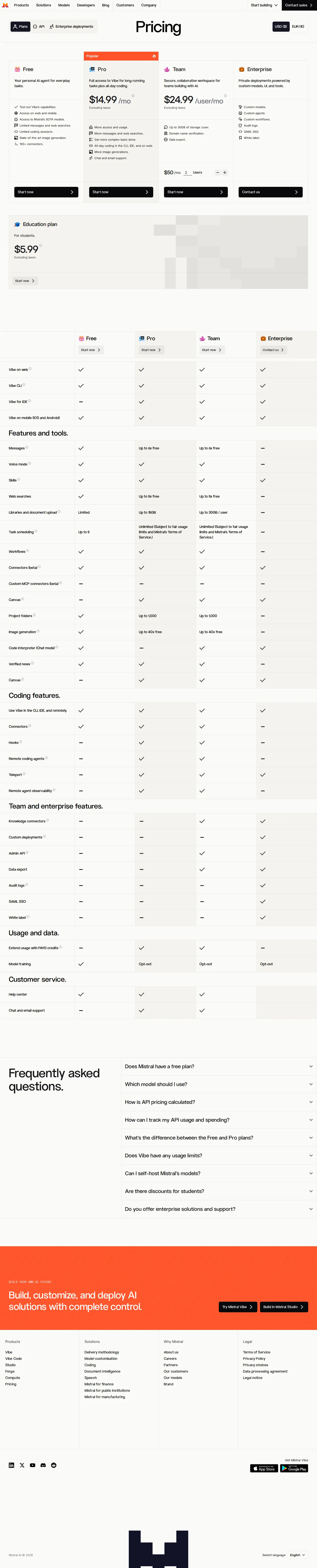
Le Chat rebrands to Vibe; tab becomes 'Plans', student plan $5.99
Wayback snapshot shows the rebrand to Vibe: the consumer tab is relabeled 'Plans', the standalone 'Mistral Code' tab is gone, and Pro now splits into Base $14.99/mo and Students $5.99/mo (excluding taxes). Pro adds 'Mistral Vibe for all-day coding, PAYG beyond', up to 15GB document storage and 1,000 projects; Team stays $24.99/mo ($50/mo for 2 users) with up to 30GB storage/user. Free still onboards via Le Chat. (Source: VentureBeat, Mistral Help Center, 2026-05.)
Plan prices hold steady as product surface widens
Wayback snapshot confirms consumer pricing unchanged through Q3 2025 — Free $0/mo, Pro $14.99/mo, Team $24.99/user/mo (Add-users selector, $50/mo for 2), Enterprise Custom — while the Mistral Code tab persists alongside Le Chat, API pricing, and Enterprise deployments.
Mistral Code added as a dedicated pricing tab
Wayback snapshot shows a new 'Mistral Code' tab inserted into the pricing page between 'API pricing' and 'Enterprise deployments' (absent in the 2025-06 snapshot), surfacing the coding agent as its own billable product surface. Le Chat consumer plans are unchanged: Free $0, Pro $14.99/mo, Team $24.99/user/mo, Enterprise Custom.
Le Chat plan grid: Free / Pro $14.99 / Team $24.99 / Enterprise
Wayback snapshot of mistral.ai/pricing shows the full consumer plan grid: Free $0/mo, Pro $14.99/mo (with an 'I am a student' option), Team $24.99/user/mo ($49.98 for 2 users), and Enterprise (Custom, private deployments). Pricing page exposes three tabs — Le Chat, API pricing, Enterprise deployments — plus a USD/EUR currency toggle.
Le Chat Pro introduced at $14.99/mo
Mistral releases Le Chat on iOS and Android and introduces a Pro subscription at $14.99/mo — deliberately undercutting ChatGPT Plus ($20/mo). First consumer subscription SKU. (Source: Maginative, TechCrunch, 2025-02.)
Le Chat assistant launches (free)
Mistral ships Le Chat, a free conversational assistant positioned as a privacy-focused European alternative to ChatGPT. No paid consumer tier yet — monetization stays on the API side.
La Plateforme API launches with per-token pricing
Mistral opens its developer API (la Plateforme) shortly after the company's April 2023 founding, billing per million tokens with separate input and output rates — establishing token metering as the core primitive before any consumer subscription existed.
- · Mistral's Pro subscription launched at $14.99/mo in February 2025 — a deliberate $5 undercut of ChatGPT Plus ($20/mo).
- · The same per-million-token meter underpins both the developer API and the consumer Vibe assistant, with Vibe overages billed at API rate via PAYG credits.
- · Mistral ships open-weight models (Mistral Small 4 under Apache 2.0, Mistral Medium 3.5 under a modified MIT license) and charges per token to call them — a hybrid of open weights plus hosted inference.
Questions & answers
- What is Mistral AI's pricing model?
- Mistral runs a two-track model: flat-rate subscriptions for the Vibe assistant (Free, Pro $14.99/mo, Team $24.99/user/mo, Enterprise custom) and a pure usage-based API billed per million tokens across 30+ models.
- Does Mistral AI offer a free tier?
- Yes. The Vibe assistant has a Free plan ($0) with web and mobile access to Mistral's SOTA models, limited messages, web searches, and coding sessions, plus image generation and 100+ connectors.
- How much does the Vibe assistant (Le Chat) cost per month?
- Vibe Pro is $14.99/mo and Team is $24.99/user/mo (excluding tax). Verified students get a $5.99/mo education plan for up to 12 months. Enterprise is custom-quoted.
- How is Mistral API pricing calculated?
- Mistral charges per million tokens for both input and output. Rates range from Mistral Small 4 ($0.15 in / $0.6 out) to Mistral Medium 3.5 ($1.5 in / $7.5 out). Batch processing gets a 50% discount.
- When did Le Chat become Vibe?
- Mistral rebranded Le Chat to Vibe in May 2026, repositioning the assistant as a full work-and-code agent. The Pro subscription tier first launched at $14.99/mo in February 2025.
- Can I self-host Mistral's models?
- Yes. Open-weight models like Mistral Small 4 are Apache 2.0 licensed for research and individual use, while commercial production deployments require a separate Mistral license.