AI Summary
About
Vast.ai is a GPU rental marketplace that connects users who need GPU compute with independent hosts — from individual machines to full data centers — who list their hardware and set their own prices. Rather than publishing a fixed price list like a traditional cloud provider, Vast.ai lets supply and demand set per-second GPU rates across 40+ data centers and 68+ GPU types, spanning consumer cards (RTX 3060, 3090, 4090, 5090) through datacenter accelerators (A100, H100, H200, B200, B300). The model is positioned explicitly against fixed-rate clouds: “hosts compete for your business rather than locking you into fixed rates.”
The company serves a broad spectrum of buyers: solo ML researchers and indie developers renting a single 4090 for a few dollars, startups running interruptible batch training to cut costs, and teams deploying autoscaling inference through Vast Serverless. Because the marketplace aggregates idle and purpose-built capacity worldwide, Vast positions on price — it markets itself as offering “structurally lower prices” than centralized clouds, with no markup layered on top of host-set rates. The Secure Cloud tier adds SOC 2 Type I-certified, isolated machines for healthcare, finance, and regulated workloads.
Vast.ai competes with other GPU-cloud marketplaces and rental providers in the corpus — RunPod, DeepInfra, Novita AI, Lightning AI, and fal.ai — but is the purest expression of the auction/marketplace model, where price discovery happens per machine in real time rather than via a vendor-published rate card. It is a privately held company; revenue and valuation figures are not publicly disclosed.
Pricing summary : How Vast.ai’s GPU marketplace and per-second metering work
Vast.ai uses a marketplace usage model with three per-second-metered cost dimensions and three rental types that trade price against priority. There is no fixed price list — each host sets its own rates, so prices fluctuate with real-time supply and demand. Total cost is the sum of three components:
- GPU compute ($/hr, dynamic): Charged per second the instance is active. Rates are host-set and vary by GPU model, GPU count, host reliability, geographic region, and live market conditions. Representative on-demand market rates captured July 2026 (Vast’s public marketplace API): RTX 4090 $0.136-$0.349/hr, RTX 5090 $0.227-$0.407/hr, A100 80GB $0.401-$0.934/hr, H100 $1.045-$2.747/hr per GPU, H200 $1.936-$3.816/hr, B200 $6.752-$6.877/hr per GPU.
- Storage ($/GB/hr): Billed continuously for every second the instance exists — including stopped instances. Only deleting the instance stops storage billing.
- Bandwidth ($/TB): Charged per byte transferred, both upload and download, at host-set rates, regardless of instance state.
On top of those dimensions sit three rental types: On-Demand (guaranteed, high priority), Interruptible (a spot/auction bid that is 50%+ cheaper but preemptible), and Reserved (pre-pay 1/3/6-month terms for up to 50% off). Vast Serverless layers autoscaling on top with no surcharge — it bills at the same per-second rate as direct rentals.
What makes this different: Vast.ai has no vendor-set rate card at all. Price discovery is genuinely market-driven — interruptible rentals are a live second-price auction — making it the purest pure-usage marketplace in the GPU-cloud corpus.
Pricing by product
GPU rental (three rental types)
| Tier | Price | Included | Key mechanics |
|---|---|---|---|
| Interruptible (Spot) | Bid-based, often 50%+ cheaper | Same hardware as on-demand, accessed via an auction bid; preemptible | ”Best value; paused (not destroyed) when outbid — checkpoint & resume” |
| On-Demand | Host-set $/hr (dynamic) | Guaranteed, high-priority capacity; spin up/down anytime | ”Most popular; per-second billing, no interruptions” |
| Reserved | Up to 50% off on-demand | Pre-pay 1, 3, or 6-month terms; guaranteed capacity on that machine | ”Sales/self-serve; credits locked to one host, cannot migrate” |
Representative on-demand market rates (captured July 2026 — dynamic, not list prices)
| GPU (1x, on-demand) | Representative rate (min–median) | Notes |
|---|---|---|
| RTX 3090 (24 GB) | $0.058–$0.149 /hr | Cheapest card captured; popular budget training GPU |
| RTX 5060 Ti (16 GB) | $0.069–$0.100 /hr | Entry consumer-class card |
| RTX A5000 (24 GB) | $0.074–$0.232 /hr | Workstation-class Ampere card |
| RTX 4090 (24/48 GB) | $0.136–$0.349 /hr | Most-rented prosumer card; rate varies widely by host |
| RTX 5090 (32 GB) | $0.227–$0.407 /hr | Newer consumer flagship |
| A100 (80 GB) | $0.401–$0.934 /hr | PCIE and SXM4 variants |
| A800 PCIE (80 GB) | $0.667–$0.668 /hr | A100-class export variant; thin supply |
| H100 (NVL / SXM) | $1.045–$2.747 /hr | NVL and SXM per-GPU rates |
| H200 (141 GB) | $1.936–$3.816 /hr | H200 and H200 NVL per-GPU rates |
| B200 (179 GB) | $6.752–$6.877 /hr | Per-GPU rate; scarce, priced above prior-gen |
| B300 (269 GB) | $7.813 /hr | Newest flagship; single-host offer at capture time |
All GPU rates above are live marketplace prices set by individual hosts and fluctuate continuously — they are representative min-to-median snapshots from Vast’s public marketplace API on 2026-07-14, not fixed list prices. Consumer GPU rates fell sharply versus the June 2026 snapshot while newest-gen (B200/B300) rose, illustrating the marketplace’s supply-driven volatility. Multi-GPU machines bill at roughly the per-GPU rate times the GPU count. Every instance also incurs separate storage ($/GB/hr) and bandwidth ($/TB) charges.
Storage & bandwidth (always billed alongside GPU)
| Dimension | Unit | Mechanics |
|---|---|---|
| Storage | $/GB/hr | Host-set; billed every second the instance exists (any state except offline), stopped included |
| Bandwidth | $/TB | Host-set; charged per byte for upload and download, any instance state |
Vast Serverless
| Tier | Price | Included | Key mechanics |
|---|---|---|---|
| Serverless | Same per-second rate as direct rentals | Autoscaling GPU workers, 68+ GPU types, 500+ locations, SOC 2 Type I | ”No serverless tier or surcharge; $5 minimum to start” |
Serverless bills per worker state: GPU compute is billed for Ready and Loading workers (not Creating or Inactive), while storage and bandwidth are billed for all worker states. The autoscaling engine recruits the best price-performance worker from the marketplace when scaling up and removes the worst price-performance GPU first when scaling down.
Sales motions across products: PLG / self-serve for on-demand, interruptible, and serverless (sign up, add credits, rent); sales-led / self-serve hybrid for reserved capacity and enterprise/Secure Cloud (Contact Sales).
Hidden costs : Storage on stopped instances and bandwidth that the $/hr never shows
The headline GPU $/hr understates the real bill because storage keeps charging on stopped instances and bandwidth is metered separately and invisibly in the per-hour figure. Two real-world examples:
Heavy individual — RTX 4090 on-demand, left stopped between runs
| Line item | Monthly cost |
|---|---|
| RTX 4090 on-demand, ~$0.80/hr × 200 active hours | $160 |
| Storage (1 TB disk) billed 24/7 including stopped time | $30 |
| Bandwidth — pulling datasets + pushing checkpoints (~2 TB) | $20 |
| Total | $210 |
The active compute is only ~$160, but a large disk left attached around the clock plus dataset/checkpoint transfer adds ~30% — and stopping the instance does not stop the storage meter.
Reserved conversion example (from Vast’s own docs)
| Line item | Monthly cost |
|---|---|
| On-demand reference: $1/hr × 720 hrs | $720 |
| Reserved (1-month pre-pay) rate | $576 |
| Effective discount | −$144 (20%) |
Vast’s documented worked example shows a 1-month reservation at $576 vs $720 on-demand — a 20% saving — with deeper discounts (up to 50%) on longer commitments. The catch: cancel early and your refund is the remaining deposit minus the discount already received, and credits are locked to that one machine.
Want to estimate your own Vast.ai bill? Use the Vast.ai pricing calculator to model your monthly cost based on GPU type, rental hours, storage size, and bandwidth.
Pricing evolution : From a pure GPU auction to serverless on the same meter
Cadence
| Quarter | Price changes | Product / SKU additions | Notes |
|---|---|---|---|
| 2026 Q2 | 0 | 0 | First corpus capture (2026-06-02): documented three-component cost model, three rental types, and serverless billing at the same per-second rate; GPU $/hr is continuously dynamic so individual rates change minute-to-minute. |
Tracked range: 2026-06-02 only (first capture). Vast.ai publishes no fixed rate card, so “price changes” at the SKU level are not meaningful — GPU rates float continuously with the marketplace. Future captures will track structural changes (rental types, serverless billing, storage/bandwidth model).
Notable changes
- 2026-06-02 — First capture: confirmed the marketplace model (hosts set their own $/hr), per-second billing, the on-demand / interruptible / reserved rental types, and Vast Serverless billing at the same per-second rate as direct rentals with a $5 minimum (source: vast.ai/pricing and docs.vast.ai).
What’s unique : A real-time GPU auction with no vendor rate card
1. No vendor-set price list — the market sets every rate. Unlike RunPod, DeepInfra, or fal.ai, which publish fixed per-GPU or per-token rates, Vast.ai has no rate card. Each host machine sets its own $/hr, and prices float continuously with supply and demand across 40+ data centers. The same RTX 4090 can cost $0.68 on one host and $0.88 on another at the same moment.
2. Interruptible rentals are a genuine spot auction. Interruptible instances work like a second-price auction: you set a bid, and your job runs while you remain the highest bidder for that machine. Get outbid and your instance is paused (not destroyed), so checkpointed workloads resume. This is structurally closer to AWS Spot than to the “discounted fixed rate” most competitors call spot.
3. Serverless carries zero pricing premium. Vast Serverless bills at the exact same per-second rate as renting the underlying GPU — no separate tier, no surcharge. The autoscaling engine recruits the best price-performance worker from the open marketplace and sheds the worst price-performance GPU first, so customers ride marketplace pricing even for managed inference.
4. Three usage dimensions, all host-set. GPU ($/hr), storage ($/GB/hr), and bandwidth ($/TB) are each priced independently by the host. Buyers can sort and filter on all three, making total-cost optimization a search problem rather than a tier-selection problem.
Strengths & weaknesses
| Strengths | Weaknesses |
|---|---|
| Structurally lowest GPU prices via real competition between hosts | No fixed rate card — prices are hard to predict or budget against |
| Per-second billing with no minimum hours or rounding | Storage keeps billing on stopped instances; easy to forget and overpay |
| Genuine spot auction (interruptible) for 50%+ savings | Interruptible jobs can be preempted at any time; needs checkpointing |
| Reserved pre-pay for up to 50% off without leaving the marketplace | Reserved credits locked to one machine, cannot migrate between hosts |
| Serverless at no premium over direct rental | Bandwidth costs are invisible in the displayed $/hr and surprise users |
| Huge hardware breadth (68+ GPU types, consumer to B300) | Host reliability varies; cheaper hosts may have lower reliability scores |
Billing UX : Prepaid credits, autobilling, and per-component price breakdowns
- Prepaid credits balance — you must add credits before starting any instance; the Credits Panel shows current balance and live spend on instances and storage volumes.
- Add Credits (Stripe + crypto) — one-time top-ups via credit card (Stripe), BitPay, or Crypto.com from the billing page.
- Autobilling threshold — automatically tops up from a saved card when the balance hits a configurable threshold, with a recommended low-balance email alert at ~75% of that threshold.
- Hover price breakdown — hovering over any instance’s price (on the Search page or Instances console) reveals the per-component split: GPU $/hr, reserved disk storage, and upload/download bandwidth rates.
- Save / discount badge — a green badge on each instance card opens the reserved pre-pay flow (1/3/6-month periods) and shows the calculated deposit and discount automatically.
- Transaction History table — Invoices and Charges tabs itemize every charge by type (GPU usage, reserved disk storage, upload/download), with an Export button to generate custom-range invoices.
- Negative-balance grace buffer — established accounts get a short negative-balance grace period sized to their average daily spend before instances are stopped and data scheduled for deletion.
Strategic wins : How the marketplace model compounds into a price advantage
1. Turning price discovery into the product
By refusing to publish a rate card and letting hosts compete, Vast.ai makes “lowest price” a structural outcome rather than a marketing claim. Every new host that joins adds downward pressure, and buyers see the real rate with no markup. This is a different lever from the usage-based pricing playbooks of fixed-rate clouds, and it is hard for a centralized provider to match without cannibalizing margin — see how this plays out across usage-based pricing in SaaS and AI.
2. A real auction for genuinely price-sensitive workloads
The interruptible spot auction captures the large segment of fault-tolerant batch jobs that don’t need guaranteed uptime, at 50%+ savings. It mirrors how AWS monetizes spare capacity, but here the spare capacity is third-party hardware — letting Vast clear inventory it doesn’t own. See our analysis of the hyperscaler GPU billing playbook for why this aligns incentives.
3. Serverless with no pricing tax
Charging serverless at the same per-second rate as direct rental removes the usual “managed convenience” surcharge competitors apply. It keeps the marketplace’s price advantage intact for inference customers and avoids a second, confusing rate card — a clean application of transparent usage-based billing.
Areas to improve : Making a dynamic market easier to budget against
1. Surface bandwidth in the headline price
Bandwidth is billed per TB but is invisible in the displayed $/hr, and Vast’s own FAQ admits users get “charged more per hour than expected” because of it. A blended “estimated all-in $/hr” that folds in typical bandwidth, shown next to the raw GPU rate, would cut bill-shock — a lesson from our coverage of AI cost unpredictability and bill shock.
2. Make stopped-instance storage cost unmissable
Storage billing continues on stopped instances, which surprises users who assume “stopped = free.” A persistent banner or a one-click “delete to stop storage charges” prompt on stopped instances would reduce silent spend.
3. Offer a price-stability option for budget-conscious teams
The pure auction is great for cost but bad for forecasting. A short-horizon “locked rate” (beyond the existing reserved pre-pay) — e.g., a 7-day fixed price on a chosen GPU class — would give finance teams something to budget against without forcing a long commitment.
Monetization stack & signals : how Vast.ai builds & buys its revenue engine
Buys 2 Builds 1
Self-serve marketplace that buys the rails it doesn't differentiate on — payments are Stripe (cards) plus BitPay/Crypto.com (crypto) — but keeps the part that IS the product in-house: the per-second meter that prices host-set GPU, storage, and bandwidth and runs the interruptible second-price auction. No revenue/lifecycle hiring is visible (first-party careers, all open roles are GPU/systems/security/research engineering), so the monetization machine looks complete and engineering-owned, not in build-out.
-
“You are charged the base active rental cost for every second your instance is in the active/connected state.”
Signals reviewed · derived from product docs
Key takeaways
- A marketplace can make “cheapest” a structural property. By letting hosts set and compete on price, Vast.ai turns low cost into an emergent outcome of supply rather than a promotional rate that must be defended.
- Auctions beat fixed discounts for clearing spare capacity. A genuine second-price spot auction extracts more value from interruptible inventory than a flat “spot discount,” and aligns the buyer’s bid with their true willingness to pay.
- Multi-dimensional metering needs single-dimensional clarity. Pricing GPU, storage, and bandwidth independently is honest but creates bill-shock risk; the lesson is to surface an all-in estimate even when you meter components separately.
- “No surcharge” is a powerful serverless wedge. Billing managed/serverless at the same rate as raw rental removes a friction point competitors leave in place and keeps the core price advantage intact.
- Prepaid credits shift collection risk but raise UX stakes. Requiring upfront credits eliminates non-payment risk, but makes autobilling, low-balance alerts, and grace buffers essential to avoid destroying customer data.
UBP implications
- Dynamic, market-set pricing is a viable alternative to vendor rate cards in commoditized compute. When the underlying resource is fungible (GPU-hours), a marketplace auction can out-compete any single vendor’s fixed list on price while still being fully usage-based.
- Spot/auction mechanics are a legitimate UBP packaging layer, not just a discount. Exposing willingness-to-pay through bids lets a platform segment price-sensitive from latency-sensitive demand without separate plans.
- Component-level metering must be paired with all-in transparency. As more usage-based products meter multiple dimensions (compute + storage + egress), the winners will be those that keep the bill legible despite the underlying complexity.
Sources
- Vast.ai pricing page (accessed 2026-06-02)
- Vast.ai instances pricing docs (accessed 2026-06-02)
- Vast.ai billing docs (accessed 2026-06-02)
- Vast.ai reserved instances docs (accessed 2026-06-02)
- Vast.ai serverless product page (accessed 2026-06-02)
- Vast.ai serverless pricing docs (accessed 2026-06-02)
- Vast.ai marketplace console (live GPU listings) (accessed 2026-06-02)
Browse the full pricing blueprint to compare Vast.ai against other GPU-cloud and usage-based pricing models.
Bottom line
Vast.ai is the purest expression of usage-based GPU pricing in the corpus: no rate card, no fixed tiers — just a real-time auction where independent hosts compete on per-second rates for compute, storage, and bandwidth. It rewards buyers who treat cost as a search-and-optimize problem and punishes those who forget that storage keeps billing on stopped instances. For fault-tolerant and price-sensitive AI workloads, it is structurally hard to beat; for teams that need predictable budgets, the same dynamism is its biggest friction.
Pricing timeline : Major events on a vertical axis
Each milestone below corresponds to a public pricing change, product launch, or material adjustment. Major events use a filled marker; minor adjustments use a faded one.
Live marketplace rates — on-demand, interruptible, reserved, serverless
Captured live console marketplace rates and the documented three-component cost model (GPU $/hr + storage $/GB/hr + bandwidth $/TB), the three rental types (on-demand / interruptible-spot / reserved up to 50% off), and Vast Serverless billing at the same per-second rate as direct rentals with a $5 minimum.
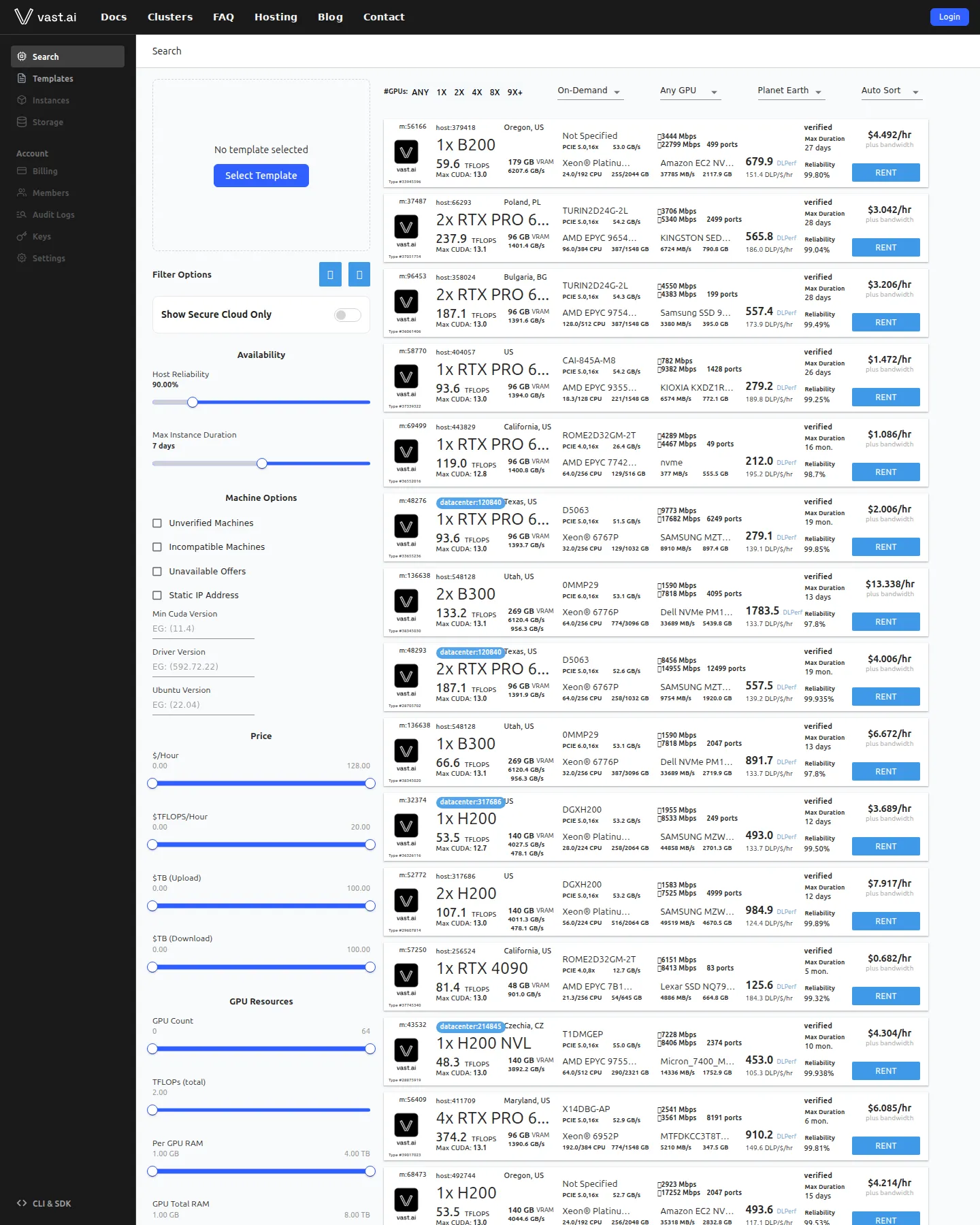
- · Vast.ai has no list price for GPUs at all — every $/hr rate is set by the individual host machine and floats with marketplace supply and demand, so the same RTX 4090 can cost $0.14 on one host and $0.35 on another at the same moment.
- · Interruptible instances are a true second-price auction: you set a bid, and your job runs while you are the highest bidder for that machine — get outbid and your instance is paused, not destroyed.
- · Vast Serverless carries zero pricing premium — it bills at the exact same per-second rate as renting the underlying GPU directly, with no separate serverless tier or surcharge, recruiting the best price-performance worker from the open marketplace.
Questions & answers
- How much does a GPU cost on Vast.ai?
- There is no fixed price — Vast.ai is a marketplace where each host sets its own per-second rate, so prices float with supply and demand. As captured in July 2026, on-demand rates ran roughly $0.136-$0.349/hr for an RTX 4090, $0.401-$0.934/hr for an A100 80GB, $1.045-$2.747/hr per H100, and $6.752-$6.877/hr per B200, before bandwidth.
- What is the difference between on-demand and interruptible instances?
- On-demand instances are guaranteed and run at the host's fixed rate. Interruptible instances are a spot/auction bid — they are typically 50%+ cheaper but can be paused (preempted) when another user outbids you, making them best for fault-tolerant, checkpointable workloads.
- Can I get a discount for long-term GPU use on Vast.ai?
- Yes. You can convert any on-demand instance to a Reserved instance by pre-paying for a 1-, 3-, or 6-month term, for up to 50% off. Pre-paid credits are locked to that specific machine and cannot migrate between hosts.
- How does Vast.ai bill for storage and bandwidth?
- Storage is charged per GB per hour for every second your instance exists (including stopped instances — only deleting the instance stops storage billing). Bandwidth is charged per TB for both upload and download, at host-set rates, on top of the GPU $/hr.
- How does Vast Serverless pricing work?
- Vast Serverless autoscales GPU workers from the marketplace and bills per second at the same rate as renting the underlying GPU directly — there is no separate serverless tier or surcharge. A $5 minimum is required to get started; you pay only for active and loading workers' compute, plus storage and bandwidth on all worker states.
- How do I pay for Vast.ai?
- Vast.ai uses a prepaid credits model. You add credits via Stripe (credit cards) or crypto (BitPay, Crypto.com) and can enable autobilling to top up automatically. There are no refunds on spent credits, and crypto-purchased credits cannot be refunded.