AI Summary
About
AI21 Labs is a Tel Aviv-based foundation-model company building large language models for the enterprise — most prominently the Jamba family of hybrid SSM-Transformer models and Maestro, which as of mid-2026 is sold as “an optimization framework for real-world AI agents” that routes, compresses, and decomposes agent requests in flight to cut what they cost. Unlike consumer-first labs, AI21 sells almost entirely to developers and businesses: there are no per-seat chat subscriptions on its pricing page, just a free trial, pure per-million-token billing for the Jamba API, and a sales-led Custom Plan for organizations that need volume discounts, premium rate limits, or private-cloud hosting.
Founded in November 2017 by Stanford AI professor Yoav Shoham, Ori Goshen, and Mobileye founder Amnon Shashua, AI21 is one of the oldest independent foundation-model labs — it shipped Jurassic-1 in 2021, well before the post-ChatGPT wave. It raised an oversubscribed $208M Series C in 2023 at a 1.4B valuation, with Google, Nvidia, and Intel Capital among its backers, bringing total funding to roughly 336M raised.
Strategically, AI21 has moved from a two-product company — the consumer Wordtune writing assistant plus the Jurassic API — toward an enterprise-only foundation-model and orchestration posture. Wordtune still exists, but the center of gravity shifted in 2024 to Jamba (open-weight, 256k context) and in 2025 to Maestro. That pivot reshaped the pricing: the consumer-facing task APIs of the Jurassic era collapsed into a clean per-token Jamba API, while the highest-value product, Maestro, abandoned per-token billing entirely for a quoted, budget-controlled enterprise model. AI21 competes with open-weight peers like Mistral AI and closed-weight leaders like OpenAI, differentiating on long-context efficiency and a deliberately developer-simple price sheet.
Pricing summary : How AI21 Labs’s pricing model works
AI21 Labs runs a pure usage-based API with no consumer seat tiers. The public ladder has just three rungs, and the real meter is tokens:
- Free Trial — “$10 credits for 7 days”, no credit card needed. A pure evaluation funnel into the paid meter. (The docs pricing page states a different duration for the same $10: “a $10 credit good for three months” — treat 7 days as the marketing-page figure and three months as the docs figure until AI21 reconciles them.)
- Pay As You Go — usage-based billing per million tokens for the Jamba foundation-model APIs and SDK, with unlimited seats (seats are free; tokens are the only meter). Per-token costs are computed per thousand (K) or per million (M) with no rounding, and charged monthly from the account creation date.
- Custom Plan — sales-led, quoted: everything in Pay As You Go plus volume discounts, premium API rate limits, private cloud hosting, priority support, a dedicated account manager, and expert AI consultancy. No public floor price.
Per-model token rates (USD per 1M tokens): Jamba Mini at $0.2 input / $0.4 output and Jamba Large at $2 input / $8 output. Maestro sits outside this table — it carries no published price at all and is contact-sales only. Usage bought through a cloud host (AWS Bedrock or SageMaker, Microsoft Azure) is priced by that provider instead: Bedrock charges a per-token fee, SageMaker charges by usage time and instance type.
What makes this different: AI21 charges for inference and nothing else on the self-serve path — seats are unlimited and free, there is no monthly platform fee, and the only consumer-style packaging is a 7-day trial. Its tokenizer is itself a pricing lever: AI21 claims ~30% more English text per token than rivals, so the effective per-word cost undercuts the headline per-token rate.
Pricing by product
Plans (self-serve + sales-led)
| Tier | Price | Included | Key mechanics |
|---|---|---|---|
| Free Trial | $10 credits | ”$10 credits for 7 days”, no credit card needed; credit covers the APIs, SDK, and playground | Pure evaluation funnel; docs state the same $10 credit is “good for three months” |
| Pay As You Go | Usage-based | Per-token Jamba APIs & SDK, unlimited seats | Tokens are the only meter; per-K/per-M with no rounding, billed monthly from account creation date |
| Custom Plan | Contact sales | Everything in the Pay As You Go Plan + volume discounts, premium API rate limits, private cloud hosting, priority support, dedicated account manager, expert AI consultancy | Sales-led, quoted, no public floor |
Jamba foundation models (per 1M tokens, USD)
| Model | Input /M | Output /M | Key mechanics |
|---|---|---|---|
| Jamba Mini | $0.2 | $0.4 | Efficient, lightweight; 256k context; open-weight |
| Jamba Large | $2 | $8 | Most powerful long-context; 256k context; open-weight |
Output is billed at 2x–4x input on both models (4x on Large). The 256k-token context window is shared across both.
Maestro (agent optimization framework)
| Service | Price | Key mechanics |
|---|---|---|
| Maestro | No public price — contact sales | ”Optimization framework for real-world AI agents”: routes, compresses, and decomposes every request in flight with no code change; automatic budget & compute scaling keeps runs inside a stated cost and latency budget; maps the cost / accuracy / latency frontier; attributes spend to the team, repo, and agent that caused it |
Cloud-hosted Jamba (third-party billing)
| Host | Price | Key mechanics |
|---|---|---|
| AWS Bedrock | Set by AWS | Per-token fee charged by the cloud provider, not AI21 |
| AWS SageMaker | Set by AWS | Billed by usage time and instance type rather than tokens |
| Microsoft Azure | Set by Microsoft | Provider sets its own pricing structure |
Sales motions across products: PLG / self-serve for the Free Trial and Pay As You Go Jamba API; sales-led for the Custom Plan and Maestro (private deployment, volume, support).
Hidden costs : What AI21 Labs users actually pay
AI21’s self-serve sheet is unusually simple — no seat fees, no platform minimum, no per-request task-API surcharges — so the “hidden” cost is really just the shape of token consumption: the output premium on Jamba Large, and the jump from self-serve to a quoted Custom Plan once you need rate-limit headroom or private hosting.
Archetype — a long-context RAG application on the Jamba API. A team summarizing and answering over long documents on Jamba Large, running ~50M input tokens and ~12M output tokens a month, plus a lighter Jamba Mini classifier path at ~30M input / 10M output.
| Line item | Monthly cost |
|---|---|
| Jamba Large input — 50M tok @ $2/M | $100 |
| Jamba Large output — 12M tok @ $8/M | $96 |
| Jamba Mini input — 30M tok @ $0.2/M | $6 |
| Jamba Mini output — 10M tok @ $0.4/M | $4 |
| Estimated total | ~$206/mo |
The lesson: on Jamba Large the $8/M output rate is 4x the input rate, so output-heavy work (long generations, verbose answers) dominates the bill even when input token counts are large. Routing simpler steps to Jamba Mini ($0.2/$0.4) is the main cost lever, and AI21’s ~30% denser tokenizer means the real token count for a given English workload runs lower than a naive word-count estimate suggests. The genuine step-change is Maestro: once you need its planning/orchestration layer, you leave the published per-token sheet entirely for a budget-controlled, sales-quoted price.
Want to estimate your own AI21 Labs bill? Use the AI21 Labs pricing calculator to model your costs based on token volume per model.
Pricing evolution : AI21 Labs pricing history and changes
AI21’s pricing has tracked a clear strategic arc: from a Jurassic-era two-layer model (per-token base models plus per-request task APIs and a consumer Wordtune subscription) toward a clean, single-meter per-token Jamba API — and then a deliberate move up the stack with Maestro, which abandons token pricing for a quoted enterprise deal. The July 2026 repositioning is the sharpest expression of that arc yet: Maestro is no longer sold as a capability you add, but as a way to spend less on the agents you already run. The dated milestones below are reconstructed from primary announcements, contemporaneous press, and the live pricing captures.
Cadence
| Quarter | Price changes | Product / SKU additions | Notes |
|---|---|---|---|
| 2021 Q3 | 1 | 1 | Jurassic-1 + AI21 Studio API launch with per-token pricing |
| 2023 Q1 | 0 | 1 | Jurassic-2 + task-specific APIs (answers, summarize, paraphrase) |
| 2024 Q1 | 0 | 1 | 2024-03 Jamba launches (open-weight, 256k context) |
| 2024 Q3 | 0 | 1 | 2024-08 Jamba 1.5 Mini & Large; GA on Amazon Bedrock |
| 2025 Q1 | 0 | 1 | 2025-03 Maestro introduced (budget-parameter pricing) |
| 2025 Q4 | 0 | 1 | 2025-12 Maestro GA in Amazon VPC |
| 2026 Q3 | 0 | 0 | 2026-07-22 Maestro repackaged from an orchestration system into an agent cost-optimization framework, adding per-team / per-repo / per-agent spend attribution; no rate or plan moved |
Tracked range: 2021 Q3–2026 Q3. Quarters not listed had no publicly announced price or SKU change. The headline Jamba token rates (Mini $0.2/$0.4, Large $2/$8), the three-rung plan ladder, and the $10 trial credit have all held steady from the 2026-06 capture through the 2026-07 one — every change in the last year has been positioning, not price.
Notable changes
- 2021-08 — Jurassic-1 ships with AI21 Studio, establishing per-token API billing (250k-token vocabulary).
- 2023-03 — Jurassic-2 plus task-specific APIs (contextual answers, summarize, paraphrase, grammar), a brief two-layer model later folded into pure token pricing.
- 2023-11 — $208M Series C at a 1.4B valuation (Google, Nvidia, Intel Capital), funding the enterprise pivot.
- 2024-03 — Jamba launches: hybrid Mamba SSM + Transformer MoE, 256k context, open weights — the strategic shift to open-weight enterprise inference.
- 2024-08 — Jamba 1.5 Mini & Large under the Jamba Open Model License; GA on Amazon Bedrock (Sep 2024), plus Vertex AI, Azure, NVIDIA NIM.
- 2025-03 — Maestro introduced with budget-parameter pricing rather than per-token billing — a deliberate move from token metering toward outcome-shaped enterprise pricing.
- 2025-12 — Maestro reaches GA in Amazon VPC; Jamba API stays pure per-token (Mini $0.2/$0.4, Large $2/$8).
- 2026-07-22 — Maestro is repositioned from “AI planning & orchestration” to “an optimization framework for real-world AI agents” that “cuts what they cost — without touching what they deliver”, leading with the claim that “most agent budgets are over half recoverable waste” and adding per-team / per-repo / per-agent spend attribution plus a cost / accuracy / latency frontier. Packaging only: Jamba rates, the plan ladder, and the $10 trial credit are unchanged, and Maestro stays contact-sales with no public price.
- 2026-07-22 — The docs pricing page surfaces a trial-duration contradiction that had gone unnoticed: it calls the $10 credit “good for three months” while the marketing pricing page advertises “7 days” — a ~12x spread on the same offer, unresolved across AI21’s two surfaces.
The consumer-to-enterprise pivot in detail
AI21 began as a two-front company: the consumer Wordtune writing assistant (launched 2020, several million users) and the Jurassic developer API. After the 2023 Series C, it concentrated on reliable enterprise AI, and the pricing followed. The Jurassic-era patchwork — per-token base models, per-request task APIs, and a consumer subscription — gave way to a single per-token Jamba meter with free unlimited seats. The most telling move is Maestro: instead of extending the token meter to its agentic orchestration layer, AI21 priced it by a budget parameter and sold it through enterprise quotes. That bifurcation — public, simple, per-token for the models; quoted and budget-controlled for the layer above — is the signature of a lab pricing the outcome separately from the raw inference underneath it.
The July 2026 repositioning completes the logic. Maestro no longer asks buyers to fund a new capability; it asks them to recover an existing line item, leading with “most agent budgets are over half recoverable waste” and offering per-team, per-repo and per-agent attribution to prove where that waste sits. The budget dial survives as “automatic budget & compute scaling”, but it is now a feature of a cost story rather than the pricing mechanic itself. Commercially this is a shift in which budget AI21 competes for: a planning system is bought from an R&D or platform budget against other tooling, while a spend-optimizer is bought against the buyer’s own inference bill and self-justifies at any size — the same argument cloud FinOps vendors have used for a decade, applied to agent runs instead of instances. It also quietly moves AI21’s value metric off its own meter: the more Maestro succeeds, the fewer Jamba tokens a customer burns, so AI21 is now selling a product that can shrink its own usage-based revenue. That only pencils if the Maestro quote captures a share of the savings, which is precisely the number AI21 does not publish.
What’s unique : AI21 Labs’s distinctive pricing mechanics
1. Unlimited free seats, tokens as the only meter. AI21’s Pay As You Go plan explicitly bundles unlimited seats — there is no per-user fee anywhere on the self-serve path. The entire self-serve bill is tokens consumed, which makes the cost model unusually legible: no seat math, no platform minimum, just input/output rates per model. This is the inverse of seat-anchored SaaS and a purer expression of usage-based pricing than most peers.
2. The tokenizer as a price lever. AI21 markets a ~30% denser tokenizer — an average token covers about one word / six English characters — and frames it explicitly as a cost advantage: the same English workload consumes ~30% fewer tokens, so the effective per-word price beats the headline per-token rate. Few labs sell the tokenizer itself as a pricing feature.
3. The premium product is sold as a subtraction from your bill, not an addition to it. Maestro breaks from per-token billing entirely, and since 2026-07-22 it is pitched as an optimization framework that “cuts what they cost — without touching what they deliver”, opening on the claim that most agent budgets are over half recoverable waste. Customers still set a cost-and-latency budget that parallel execution paths compete inside, but the sale is now against money the buyer is already spending rather than a new capability line — a structural step toward outcome-shaped pricing where the outcome being sold is a smaller invoice.
4. FinOps-grade attribution applied to agent runs. Maestro breaks spend down to the team, repo, and agent that caused it and maps a cost / accuracy / latency frontier so buyers can pick a point deliberately. Chargeback-style allocation is standard in cloud cost governance but rare from a foundation-model lab, and it points at a real gap in AI21’s own self-serve product: the Jamba API bills tokens with no equivalent breakdown, so the attribution buyers need most is only available on the sales-gated side.
Strengths & weaknesses
| Strengths | Weaknesses |
|---|---|
| Fully public per-token Jamba rates (Mini $0.2/$0.4, Large $2/$8) — no “contact sales” wall for inference | Only two models on the public sheet — far narrower catalog than Mistral or OpenAI for buyers comparing options |
| Unlimited free seats; tokens are the only self-serve meter — exceptionally legible cost model | Output premium on Jamba Large ($8/M, 4x input) can surprise generation-heavy workloads |
| Open-weight Jamba (256k context) lets buyers self-host the same models — a credible lock-in hedge | Maestro now makes a quantified savings claim (“over half recoverable waste”) while publishing no price — buyers can size the benefit but not the payback |
| Maestro attributes spend to the team, repo, and agent that caused it — FinOps-grade allocation, rare from a model lab | That attribution exists only on the sales-gated side; the self-serve Jamba meter offers no equivalent cost breakdown |
| ~30% denser tokenizer lowers the effective per-word cost below the headline token rate | Custom Plan (volume, private cloud, support) is fully sales-gated with no published floor |
| $10 trial with no credit card lowers evaluation friction | Trial length contradicts itself across surfaces — “7 days” on the pricing page vs “three months” in the docs, a ~12x spread on the same credit |
| Rate stability: two consecutive captures (2026-06, 2026-07) show identical token rates and plan ladder | No batch discount, cached-input rate, or context-tier pricing published — fewer optimization levers than peers |
| Long, deep-tech founder pedigree and multi-cloud availability (Bedrock, Vertex, Azure, VPC) | Frequent product re-architecture (Jurassic to Jamba to Maestro) makes historical price tracking harder |
Billing UX : AI21 Labs billing controls and transparency
- Free trial credits — new accounts get a $10 usage credit with no credit card, spendable across the APIs, the SDK, and the playground; billing information is only required once the trial credit is exhausted or expires. The pricing page states “7 days”; the docs pricing page states “three months” for the same $10 credit.
- Account > Model usage — the named in-product view for token counts and costs per model, the single dimension that drives the self-serve bill.
- Account > Billing & Plans — the named control for viewing or changing your billing plan (trial → Pay As You Go → customized plan).
- No-rounding token math — per-token costs are computed per thousand (K) or per million (M) with no rounding (AI21’s own worked example: 1,500 tokens at $0.10/K = $0.15), and usage is charged monthly from the account creation date.
- Unlimited seats — no per-user billing to manage; team size is decoupled from cost entirely on Pay As You Go.
- Maestro budget & compute scaling — Maestro’s “automatic budget & compute scaling” keeps parallel execution paths inside a stated cost and latency budget, and its spend-attribution view breaks cost down to the team, repo, and agent that caused it.
- Multi-cloud billing options — Jamba is hosted on AWS SageMaker and Bedrock and on Microsoft Azure, where each provider sets its own pricing structure (Bedrock per token; SageMaker by usage time and instance type), so usage can be consolidated onto an existing cloud bill instead of a separate AI21 invoice.
- Custom Plan controls — premium API rate limits, volume discounts, and private-cloud hosting are negotiated as part of the sales-led Custom Plan, with a dedicated account manager for ongoing cost governance.
Strategic wins : Why AI21 Labs’s pricing decisions worked
1. Collapsing a messy two-layer model into one clean meter
The Jurassic era mixed per-token base models, per-request task APIs, and a consumer Wordtune subscription. By concentrating on Jamba and billing purely per token with free unlimited seats, AI21 made its self-serve pricing dramatically easier to reason about — a buyer can model their bill from two rates and a token estimate. See usage-based pricing strategy for why a single durable meter scales better than a patchwork.
2. Pricing orchestration above the token line — and, since July 2026, selling it against the buyer’s own bill
Rather than stretching the token meter onto Maestro, AI21 priced the orchestration layer by a budget parameter and sold it through enterprise quotes, capturing the value of a validated multi-step outcome separately from raw inference. The 2026-07-22 repositioning makes that commercially easier: framed as an optimization framework that cuts agent cost, Maestro is funded from spend the buyer has already approved rather than from a new tooling budget, which shortens the internal case and gives the sales team a number to argue about instead of a category to explain. It mirrors the broader shift away from per-token toward outcome-based pricing — with the twist that the outcome sold here is a lower invoice.
3. Turning the tokenizer into a price argument
Most labs treat tokenization as plumbing. AI21 markets its ~30% denser tokenizer as a cost advantage, giving its sales motion a concrete “you pay for fewer tokens” story that reframes a raw rate comparison. It’s a reminder that the unit you meter is itself a competitive lever, not just an accounting detail.
Areas to improve : Gaps in AI21 Labs’s pricing approach
1. Price the savings claim Maestro now leads with
Since 2026-07-22 Maestro’s headline promise is financial — “most agent budgets are over half recoverable waste” — but the fee that unlocks it is still quoted, so a buyer can size the benefit and not the payback. A savings pitch with an unpriced product is an ROI equation missing one side, and it invites exactly the cost-unpredictability anxiety the product claims to fix. The concrete fix is to price against the thing being claimed: publish a percentage-of-verified-savings rate, or a floor plus a worked example (“$X/mo on $Y of agent spend, break-even at Z% reduction”). A gain-share also resolves the awkward incentive — Maestro shrinking a customer’s Jamba consumption should raise AI21’s revenue, not cut it.
2. Reconcile the trial duration across surfaces
The pricing page advertises the $10 credit for “7 days”; the docs pricing page calls the same credit “good for three months”. That is a ~12x spread on the first commitment AI21 asks a developer to make, and evaluation planning depends on which number is true. Whichever is correct, one page should be corrected and both should quote the same figure — a self-serve funnel that contradicts itself at the trial step erodes trust before the buyer ever sees a token rate.
3. Add optimization levers to the token sheet
Peers publish batch discounts, cached-input rates, and context-tier pricing; AI21’s sheet is just two flat input/output pairs. Adding even a batch or cached-input discount would give cost-sensitive workloads a reason to optimize on AI21 rather than route to a cheaper rival — and would make the ~30% tokenizer claim land harder against a fuller comparison.
4. Surface a broader public model line
With only Jamba Mini and Large on the public sheet, buyers comparing breadth see a thin catalog next to Mistral AI or OpenAI. Publishing fine-tuning, embedding, or specialized-model rates — even if narrow — would signal a fuller platform and reduce the perception that AI21 is a two-model shop.
Monetization stack & signals : how AI21 Labs builds & buys its revenue engine
Buys 1 Builds 1
PLG core, mostly buy: a first-party token meter on bought AWS Bedrock/SageMaker and Azure marketplace rails. The bridge to watch is a sales-led enterprise overlay — Maestro and the quoted Custom plan — grafted onto that self-serve spine, no revenue roles open yet.
-
“Per-token costs are per thousand (K) or per million (M), with no rounding... once your trial usage is exceeded or expires, you must provide valid billing information in your account to continue using the AI21 platform.”
-
“AI21 models are hosted on several cloud providers, including AWS SageMaker and Bedrock, and Microsoft Azure, where each provider sets their own pricing structures.”
Signals reviewed · derived from product docs
Key takeaways
- One meter beats a patchwork. AI21 collapsed Jurassic-era per-token base models, per-request task APIs, and a consumer subscription into a single per-token Jamba meter with free seats — making its self-serve cost legible from two rates and a token estimate.
- Repositioning can change which budget you’re sold from without moving a price. AI21 changed no rate on 2026-07-22, but reframing Maestro from an orchestration system into an agent cost-optimizer moved the purchase from a new-tooling budget onto the buyer’s existing inference bill — more commercial leverage than most discounts buy. The catch is that a savings pitch needs a price: claiming “over half recoverable waste” while staying quote-only hands buyers half an ROI equation.
- The tokenizer is a pricing lever. A ~30% denser tokenizer means the effective per-word cost beats the headline per-token rate — AI21 sells that efficiency as a cost argument, not just a technical footnote.
- Output dominates the bill on premier models. Jamba Large’s $8/M output is 4x its input rate, so generation-heavy workloads pay far more than input-token counts suggest — routing simpler steps to Jamba Mini is the main lever.
- Open weights hedge lock-in. Jamba’s open-weight license (256k context) lets buyers self-host the same models they call per token — the same playbook that anchors Mistral’s strategy.
UBP implications
- A single token meter with free seats is the cleanest UBP story available. AI21 shows that decoupling seats from cost entirely — billing only tokens — produces a model buyers can estimate without seat math or platform minimums. UBP designers should look for the one unit every customer can reason about directly.
- The agent layer is where vendors start selling against your meter instead of on it. Maestro’s July 2026 turn — from orchestration capability to a framework that cuts agent spend, with per-team, per-repo and per-agent attribution — shows the premium SKU being priced on money saved rather than units consumed. UBP strategists should expect that inversion, and design for the incentive problem it creates: a vendor whose optimizer reduces its own usage revenue needs a gain-share or a floor, or the two products quietly compete.
- The metering unit itself can be a differentiator. AI21’s ~30% denser tokenizer reframes a rate comparison: a “cheaper” per-token rival can still be more expensive per delivered word. UBP practitioners should define the value metric so that efficiency gains accrue to the customer’s visible bill.
Sources
- AI21 Labs pricing page (accessed 2026-07-22)
- AI21 docs — Usage & pricing (accessed 2026-07-22)
- AI21 docs — Jamba foundation models (current model versions, context windows, deprecations) (accessed 2026-07-22)
- AI21 docs — Maestro overview (budget parameter; no published price) (accessed 2026-07-22)
- AI21 Maestro — product page (accessed 2026-07-22)
- AI21 contact sales — Custom Plan (accessed 2026-07-22)
- AI21 blog — Meet Maestro: AI planning & orchestration (accessed 2026-07-22)
- AI21 changelog (accessed 2026-07-22)
- Browse the pricing blueprint corpus
Bottom line
AI21 Labs prices like an enterprise foundation-model lab, not a consumer app: a $10 trial credit funnels into a pure per-million-token Jamba API (Mini $0.2/$0.4, Large $2/$8) with free unlimited seats, while a sales-led Custom Plan handles volume, private cloud, and support. Its sharpest moves are collapsing the Jurassic-era patchwork into a single legible token meter, selling its denser tokenizer as a cost advantage, and — since July 2026 — repositioning Maestro from an orchestration system into a framework that cuts what production agents cost, complete with per-team, per-repo and per-agent spend attribution. That reframing is smart packaging on an unchanged price sheet, but it also raises the bar: a product sold on recovering waste needs a published price for buyers to compute the payback, and AI21 still doesn’t offer one. The remaining gaps are that opaque Maestro number, a thin public model line, no batch or cached-input levers, and a trial length that reads as 7 days on one page and three months on another.
Want to compare AI21 Labs against other foundation-model providers? See Mistral AI and OpenAI, or browse the full pricing blueprint.
Pricing timeline : Major events on a vertical axis
Each milestone below corresponds to a public pricing change, product launch, or material adjustment. Major events use a filled marker; minor adjustments use a faded one.
Maestro repositioned as an agent cost-optimization framework
The Maestro page drops the 'AI planning & orchestration system' framing for 'an optimization framework for real-world AI agents' that 'cuts what they cost — without touching what they deliver', adding per-team / per-repo / per-agent spend attribution and a cost/accuracy/latency frontier. Jamba token rates are unchanged (Mini $0.2/$0.4, Large $2/$8 per 1M) and Maestro stays quote-only.
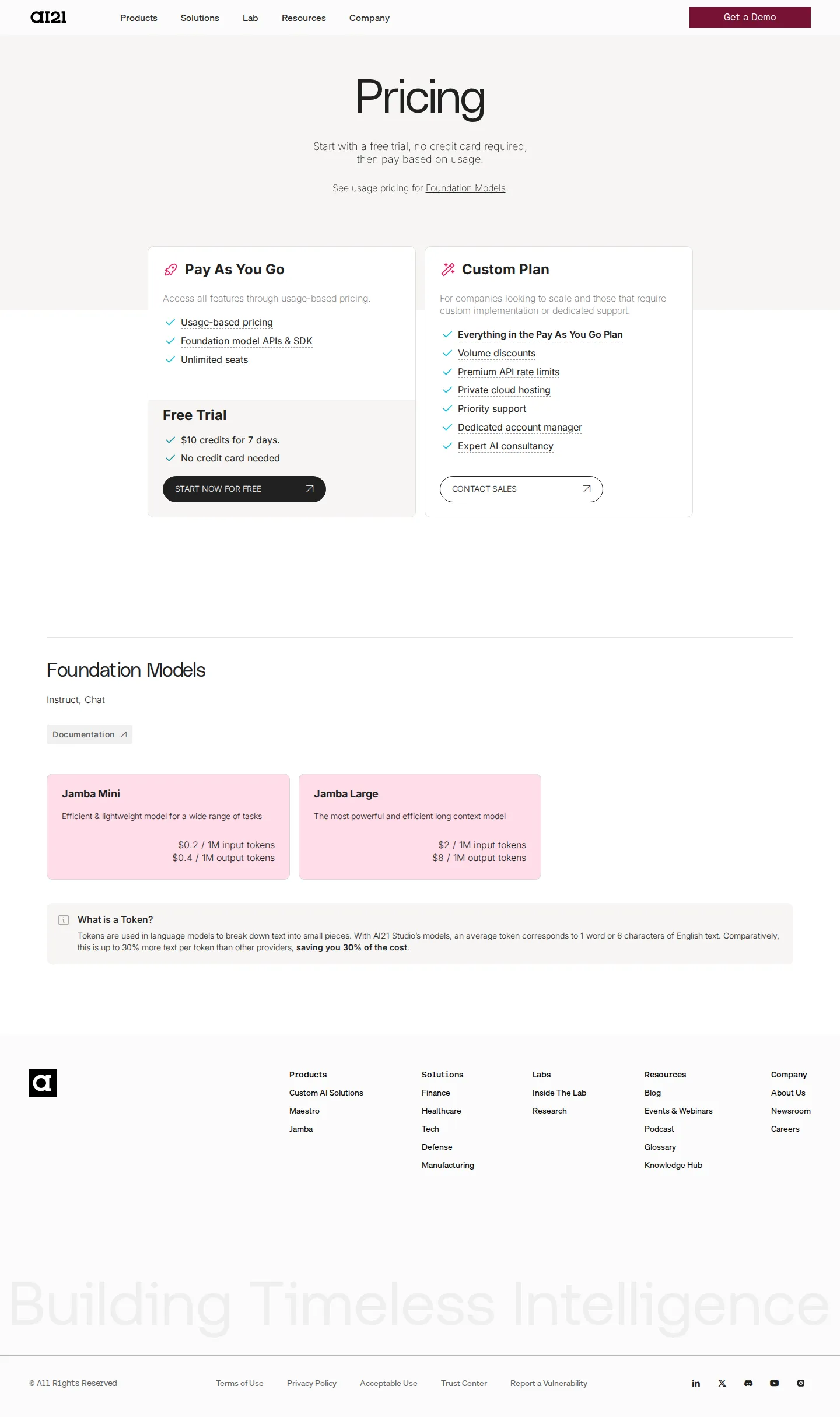
Live snapshot: pure per-token Jamba API + $10 trial + Custom
Captured live USD pricing at ai21.com/pricing: Free Trial ($10 credits / 7 days, no card), Pay As You Go (usage-based, unlimited seats), and a sales-led Custom Plan. Jamba Mini $0.2 in / $0.4 out and Jamba Large $2 in / $8 out per 1M tokens.
Maestro reaches GA in Amazon VPC
Maestro becomes generally available for deployment in Amazon Virtual Private Cloud on December 1, 2025, cementing the enterprise/agentic focus. Foundation-model API pricing remains pure per-token (Jamba Mini $0.2/$0.4, Jamba Large $2/$8 per 1M); Maestro stays quote-based.
Maestro AI planning & orchestration introduced
AI21 unveils Maestro, an enterprise AI planning and orchestration system that plans, validates, and corrects multi-step tasks at inference time. It is priced not per token but via a 'budget' parameter trading speed against cost and reliability — a structural move toward outcome-shaped, quoted enterprise pricing.
Jamba 1.5 Mini & Large under an open license; on Bedrock
Jamba 1.5 Mini and Large ship August 22-23, 2024 under the Jamba Open Model License (256k context; 12B/52B and 94B/398B active/total params) and reach GA on Amazon Bedrock in September 2024, plus Vertex AI, Azure, and NVIDIA NIM — establishing multi-cloud per-token availability.
Jamba launches — hybrid SSM-Transformer, open weights
AI21 releases Jamba on March 29, 2024 — the first production-grade hybrid Mamba SSM + Transformer mixture-of-experts model, with context up to 256,000 tokens and open weights. It signals the strategic pivot to open-weight enterprise models monetized through hosted per-token inference.
$208M Series C at $1.4B valuation funds enterprise pivot
AI21 closes an oversubscribed $208M Series C (an initial $155M in August 2023 topped up to $208M in November) at a 1.4B valuation, with Google, Nvidia, and Intel Capital among backers. The capital underwrites the shift from consumer Wordtune toward reliable enterprise foundation models.
Jurassic-2 + task-specific APIs
Jurassic-2 (J2) ships March 9, 2023 with faster responses and multilingual support, alongside task-specific APIs (contextual answers, summarize, paraphrase, grammar). Pricing stays per-token for the base models, with task APIs billed per request — a brief two-layer model later collapsed into pure token pricing.
Jurassic-1 launches with AI21 Studio API
AI21 opens AI21 Studio with Jurassic-1, a 178B-parameter model carrying a 250,000-token vocabulary, billed via per-token API credits. This establishes per-token metering as the core primitive years before Jamba — alongside the consumer Wordtune writing assistant launched in 2020.
- · AI21 Labs was co-founded in 2017 by Stanford professor Yoav Shoham, Ori Goshen, and Mobileye founder Amnon Shashua — making it one of the few foundation-model labs with a serial deep-tech founder team.
- · AI21 advertises a pricing edge in the tokenizer itself: it claims an average token covers ~1 word / 6 English characters, ~30% more text per token than other providers — so the same workload costs ~30% fewer tokens.
- · Jamba (March 2024) was the first production-grade hybrid Mamba SSM + Transformer mixture-of-experts model, pairing a 256,000-token context window with open weights under the Jamba Open Model License.
Questions & answers
- What is AI21 Labs's pricing model?
- AI21 Labs runs a pure usage-based API: you pay per million tokens for its Jamba models (Jamba Mini at $0.2 in / $0.4 out, Jamba Large at $2 in / $8 out). The public ladder is a $10 free trial, Pay As You Go, and a sales-led Custom Plan for volume discounts, private cloud, and support.
- Does AI21 Labs offer a free tier?
- Yes — a Free Trial of $10 in credits, with no credit card required. AI21's two surfaces disagree on how long it lasts: the pricing page says 7 days while the docs pricing page says the same $10 credit is good for three months. After the credit runs out you move to Pay As You Go and are billed per token for the Jamba APIs and SDK, with unlimited seats.
- How much do AI21's Jamba models cost per token?
- Jamba Mini is $0.2 per 1M input tokens and $0.4 per 1M output tokens. Jamba Large is $2 per 1M input tokens and $8 per 1M output tokens. AI21 also notes its tokenizer fits ~30% more English text per token than other providers.
- How is AI21 Maestro priced?
- Maestro has no published price and is sold by enterprise quote only. Since July 2026 AI21 positions it as an optimization framework that cuts what production AI agents cost — routing, compressing, and decomposing requests in flight, holding runs inside a stated cost and latency budget, and attributing spend to the team, repo, and agent that caused it. Because the fee is quoted, buyers cannot compute the payback on those savings without a sales call.
- Is AI21 Labs pricing usage-based or subscription?
- It is usage-based, not subscription. AI21 bills per million tokens on Pay As You Go for the Jamba API; there are no per-seat consumer plans. Enterprise customers move to a Custom Plan for volume discounts, premium rate limits, and private cloud hosting.