AI Summary
About
Moonshot AI (月之暗面, “Dark Side of the Moon”) is a Beijing-based foundation-model company best known for Kimi, its long-context assistant, and the Kimi K2 family of open-weight models. It serves two distinct buyers: individuals and teams who subscribe to the Kimi assistant for chat, deep research, and agentic coding, and developers who call Kimi/Moonshot models over a per-token API. The company monetizes hosted inference and a managed assistant on top of weights it releases openly — a structurally similar bet to Europe’s Mistral AI, executed inside China’s brutally competitive model-price market.
Founded in March 2023 by Tsinghua schoolmates Yang Zhilin, Zhou Xinyu, and Wu Yuxin, Moonshot launched the Kimi assistant in October 2023 with a long-context hook — the first product to support 200,000-character Chinese input, later expanded to 2 million characters in a March 2024 upgrade that went viral across Chinese social media. That long-context positioning is the company’s founding differentiator and shows up directly in the price sheet: the legacy moonshot-v1 API charges by context window.
Moonshot is among China’s top-funded LLM startups, backed by Alibaba, Tencent, IDG Capital, 5Y Capital, Meituan, and China Mobile. Its valuation climbed from roughly $4.3B early on to about $10B (February 2026) and then to around $20B after raising ~$2B in May 2026 — a trajectory tied to demand for its open-weight models and a reported Hong Kong IPO targeted for the second half of 2026. The July 2025 release of Kimi K2 — a 1-trillion-parameter Mixture-of-Experts model with 32B active parameters — became the fastest-downloaded model on Hugging Face one day after launch and helped ignite an aggressive China model-price war.
In July 2026 Moonshot moved up-market with Kimi K3, a 2.8-trillion-parameter, natively multimodal flagship with a 1,048,576-token context window aimed at long-horizon coding, knowledge work, and deep reasoning. K3 carries the first genuinely premium rate card in the company’s history — $3.00 per 1M input tokens and $15.00 per 1M output — while the K2 family stays at the cheap end and the original context-tiered moonshot-v1 models are scheduled for full platform sunset on August 31, 2026.
Pricing summary : subscription assistant plus a cache-discounted per-model token API
Moonshot AI runs a two-track model: flat-rate freemium subscriptions for the Kimi assistant and pure usage-based pricing for the developer API, billed per million tokens. The dimensions are:
- Kimi assistant seats — a tempo-named ladder: Free/Adagio ($0), Moderato ($19/mo), Allegretto ($39/mo), Allegro ($99/mo), Vivace ($199/mo), each with an annual option billed once a year at $180, $372, $948 and $1,908 respectively — about 20% off twelve monthly payments.
- API tokens (Kimi K3) — the flagship, $3.00 in (cache miss) / $15.00 out per 1M, cache-hit input $0.30/M, 1,048,576-token context.
- API tokens (Kimi K2 family) — Kimi K2.5 at $0.60 in / $3.00 out, Kimi K2.6 and Kimi K2.7 Code at $0.95 in / $4.00 out, and a K2.7 Code HighSpeed variant at exactly double ($1.90 in / $8.00 out) for ~180 tokens/s output.
- API tokens (moonshot-v1, context-tiered) — the same model priced by context window: $0.20/$2.00 at 8k, $1.00/$3.00 at 32k, $2.00/$5.00 at 128k (in/out per 1M). Scheduled for full platform sunset on August 31.
- Context caching — cache-hit prompt prefixes billed 80–90% below cache-miss input (e.g. $0.10/M vs $0.60/M on K2.5; $0.30/M vs $3.00/M on K3). Caching is automatic on every current model.
- Recharge tiers — API rate limits scale with cumulative recharge, from Tier0 at $1 to Tier5 at $3,000; a $5 cumulative recharge earns a $5 voucher, and a K3-launch rebate returns 10–30% of a single top-up as vouchers through 2026-08-12.
- Batch and tool meters — separate BatchJob and WebSearch rate cards sit alongside the chat-completion meter.
What makes this different: Moonshot prices per-million-token billing publicly, but adds two China-market signatures — context-length as a price axis on the sunsetting legacy API and a deep context-caching discount it pioneered in 2024 — on top of open weights you can download and run yourself. Kimi K3 adds a third: a genuine 5× price ladder between the flagship and the K2 line, so model choice, not context length, is now the main cost lever.
Pricing by product
Kimi assistant — consumer & power-user plans (USD/mo)
| Tier | Price | Included | Key mechanics |
|---|---|---|---|
| Free (Adagio) | $0 | 6 agent credits; 1 concurrent agent task; 200 professional-database calls | Entry point; the original viral free product |
| Moderato | $19 / mo ($180 / yr, i.e. $15 / mo) | 60 agent credits; Deep Research; 25 Agent Swarm uses; Kimi Code 1×; 2,000 professional-database calls | ”Popular” power-user tier |
| Allegretto | $39 / mo ($372 / yr, i.e. $31 / mo) | 150 agent credits; Kimi Claw; 50 Agent Swarm uses; 5× code credits; 5,000 professional-database calls | Agentic workloads |
| Allegro | $99 / mo ($948 / yr, i.e. $79 / mo) | 360 agent credits; 120 Agent Swarm uses; 15× code credits; 12,000 professional-database calls | Heavy agent + code use |
| Vivace | $199 / mo ($1,908 / yr, i.e. $159 / mo) | 720 agent credits; 240 Agent Swarm uses; 30× code credits; 24,000 professional-database calls | Top consumer tier |
| Tipping (“Give Kimi some snacks”, “Send Kimi a flower”) | $0.99 each | Optional one-off gratuity purchases inside the iOS app | Consumer tipping mechanic, live since 2024 |
Annual billing is charged once a year and saves a flat ~20% ($48 / $96 / $240 / $480 per year respectively). Agent credit counts are Moonshot’s own “approximate values based on typical task token consumption”; agent features share one credit pool while Kimi Code has a separate pool, and K2.6 usage does not consume credits. Buying the same tiers through Apple’s in-app purchase uses Apple price points that differ slightly from the web card — $180.99 / $374.99 / $949.00 / $1,999.00 per year. The original Kimi assistant launched free in October 2023 and added a viral “tipping/recharge” feature in May 2024 to buy priority during capacity crunches.
API — Kimi K3 (flagship, per 1M tokens, USD)
| Model | Input /M (cache miss) | Output /M | Cache-hit input /M | Context window |
|---|---|---|---|---|
| kimi-k3 | $3.00 | $15.00 | $0.30 | 1,048,576 tokens |
K3 always reasons; reasoning depth is set per request via reasoning_effort (low / high / max, default max) with no separate reasoning-token line item. Automatic context caching, ToolCalls, JSON mode, structured output and internet search are included in the rate.
API — Kimi K2 family (per 1M tokens, USD)
| Model | Input /M (cache miss) | Output /M | Cache-hit input /M | Context window |
|---|---|---|---|---|
| kimi-k2.7-code | $0.95 | $4.00 | $0.19 | 262,144 tokens |
| kimi-k2.7-code-highspeed | $1.90 | $8.00 | $0.38 | 262,144 tokens |
| kimi-k2.6 | $0.95 | $4.00 | $0.16 | 262,144 tokens |
| kimi-k2.5 | $0.60 | $3.00 | $0.10 | 262,144 tokens |
HighSpeed is the same model as Kimi K2.7 Code at exactly double every rate, bought purely for throughput (~180 tokens/s output, up to 260 tokens/s in short contexts). Cache-hit input is billed 80–90% below cache-miss across the family, and the K2 weights are published on Hugging Face.
API — moonshot-v1 (context-length-tiered, per 1M tokens, USD)
| Model | Input /M | Output /M | Context window | Key mechanics |
|---|---|---|---|---|
| moonshot-v1-8k | $0.20 | $2.00 | 8,192 tokens | Same model, 8k context window |
| moonshot-v1-32k | $1.00 | $3.00 | 32,768 tokens | 4× context, 5× input price |
| moonshot-v1-128k | $2.00 | $5.00 | 131,072 tokens | 16× context, 10× input price |
The -vision-preview variants of all three tiers carry identical rates. The legacy moonshot-v1 family prices the same model by context window — context length is literally the meter — and Moonshot’s own docs now flag “full platform sunset expected on August 31”. The Kimi K2/K3 models fold long context into a single per-model rate instead.
Sales motions across products: PLG / self-serve for the Kimi assistant tiers and the entire pay-as-you-go API; recharge tiers and top-up rebates reward larger prepaid balances. A “Verify Organization” enterprise track exists for flexible rate limits, multi-project deployments, SLA-backed reliability and dedicated support, but it publishes no separate rate card — the public rate card is the anchor.
Hidden costs : What Moonshot AI (Kimi) users actually pay
Moonshot’s headline rates are among the lowest in the market, but the real bill is shaped by three things the sticker price doesn’t show: whether your prompts actually hit the cache, which context tier you land on with the legacy API, and the output-token premium that dominates generation-heavy workloads. Two archetypes show how the total assembles.
Archetype 1 — a developer running a long-context RAG agent on Kimi K2.5. Assume ~60M input + ~15M output tokens a month, with a stable system prompt and document context that hits the cache about 60% of the time.
| Line item | Monthly cost |
|---|---|
| K2.5 input — 24M cache-miss tok @ $0.60/M | $14.40 |
| K2.5 input — 36M cache-hit tok @ $0.10/M | $3.60 |
| K2.5 output — 15M tok @ $3.00/M | $45.00 |
| Estimated total | ~$63/mo |
The lesson: cache hits collapse the input line — the 36M cached tokens cost less than $4, versus ~$21.60 if they all missed. But output is the dominant meter at $3.00/M (5× the cache-miss input rate), so generation-heavy work (long answers, code) drives the bill regardless of how well you cache.
Archetype 2 — a legacy app pinned to moonshot-v1-128k for full-document context. A team feeds whole documents into the 128k context window, running ~20M input + ~5M output tokens a month.
| Line item | Monthly cost |
|---|---|
| moonshot-v1-128k input — 20M tok @ $2.00/M | $40.00 |
| moonshot-v1-128k output — 5M tok @ $5.00/M | $25.00 |
| Estimated total | ~$65/mo |
Here the surprise is the context-tier tax: the same workload on moonshot-v1-8k would cost $0.20/$2.00 (about $14/mo), so reaching for the 128k window is a roughly 4–5× premium. The fix is usually to migrate to a Kimi K2 model, which folds long context into one flat per-model rate plus caching rather than charging an escalating context tier.
Want to estimate your own Moonshot AI bill? Use the Moonshot AI pricing calculator to model your costs based on token volume, cache-hit rate, context tier, and assistant seats.
Pricing evolution : Moonshot AI pricing history and changes
Moonshot’s pricing evolved along two tracks. The Kimi assistant went from a free, long-context novelty (2023) to a tempo-named subscription ladder; the API moved from context-tiered moonshot-v1 rates (2024) to an aggressive open-weight Kimi K2 price war (2025), then its first material price increase with K2.6 (April 2026) and its first genuinely premium tier with Kimi K3 (July 2026). The dated milestones below are reconstructed from primary announcements and contemporaneous press.
Cadence
| Quarter | Price changes | Product / SKU additions | Notes |
|---|---|---|---|
| 2023 Q4 | 0 | 1 | Kimi assistant launches free, built around long context |
| 2024 Q1 | 1 | 1 | 2M-character context goes viral; context-tiered moonshot-v1 API live |
| 2024 Q2 | 1 | 1 | Viral tipping/recharge feature; context caching pioneered |
| 2025 Q3 | 1 | 1 | Kimi K2 open-weight launch ignites a price war |
| 2026 Q1 | 0 | 1 | Kimi K2.5 adds vision + agent swarm; deep cache discount |
| 2026 Q2 | 1 | 1 | Kimi K2.6 raises input 58%; legacy K2 hits end-of-life |
| 2026 Q3 | 1 | 3 | Kimi K3 opens a $3.00/$15.00 ceiling; K2.7 Code + HighSpeed added; moonshot-v1 flagged for an August 31 sunset |
Tracked range: 2023 Q4–2026 Q3. Quarters not listed had no publicly announced price or SKU change. Dated milestones below cite primary/secondary sources; the China-native RMB card may move on a different cadence than the international USD card.
Notable changes
- 2023-10 — Kimi assistant launches free, built around 200,000-character long context (Wikipedia).
- 2024-03 — Lossless context expands to 2,000,000 Chinese characters and goes viral; context-tiered moonshot-v1 API (8k/32k/128k) is live.
- 2024-05 — Viral tipping/recharge feature lets users pay for priority during capacity crunches; API rate limits tier by cumulative recharge.
- 2024-07 — Context caching pioneered, cutting cache-hit input ~80–85% below cache-miss.
- 2025-07 — Kimi K2 open-weight (1T-param MoE) launches at aggressive rates and tops Hugging Face downloads, pressuring OpenAI/Anthropic on price (HPCwire).
- 2026-02 — Kimi K2.5 adds vision and agent swarm at $0.60 in / $3.00 out, cache-hit input $0.10/M; top-up bonus program reinforces recharge.
- 2026-04 — Kimi K2.6 raises input 58% ($0.60 to $0.95/M) and output to $4.00/M — read as a pre-IPO commercialization signal (KuCoin); legacy K2 reaches end-of-life 2026-05-25.
- 2026-07-15 — A K3 launch top-up rebate opens through 2026-08-12: 10–30% of a single top-up returned as vouchers, capped at $4,000 and valid 90 days, on the pay-as-you-go API only.
- 2026-07-16 — Kimi K3 launches at $3.00 in / $15.00 out per 1M (cache-hit input $0.30/M, 1,048,576-token context) — the first genuinely premium rate on Moonshot’s card, roughly 3.2× the input and 3.75× the output of K2.6. Kimi K2.7 Code lands at $0.95/$4.00 with a HighSpeed variant priced at exactly double ($1.90/$8.00) that buys throughput, not capability.
- 2026-07-21 — Moonshot’s model-pricing overview flags the legacy moonshot-v1 family for “full platform sunset expected on August 31”, and the legacy Kimi K2 0711/0905/Turbo and K2 Thinking models disappear from the card entirely.
- 2026-07-19 — Reports (Yahoo Finance and Investing.com; The Information on 2026-07-20) that Moonshot is seeking investor approval to begin a Hong Kong IPO, targeting a listing within six months of the Kimi K3 debut — moving the long-”reported” listing from backdrop to an active process. No price change accompanies the plan, but an IPO track historically ends a lab’s deepest-discount phase as margin disclosure begins, which is consistent with the direction the card has already taken: the +58% K2.6 increase and the K3 ceiling both read as pre-IPO commercialization rather than reversible promotions.
The Kimi K2.6 price increase in detail
The April 2026 K2.6 release broke a two-year pattern of cuts. Input rose 58% from $0.60 to $0.95 per 1M tokens, output climbed to $4.00/M (21 to 27 yuan RMB), and even the cache-hit input rate ticked up (0.7 to 1.1 yuan RMB). After years of using aggressive pricing to win developer share, Moonshot raised rates on its flagship model — which observers read as deliberate proof of “commercialization capability” ahead of a reported Hong Kong listing in the second half of 2026, following competitors Zhipu and MiniMax to public markets. The strategic read: a lab that can raise prices on a leading model without losing its developer base is a more investable lab, and the open-weight escape hatch (download K2.6 yourself) blunts the backlash a closed-weight increase would trigger.
The Kimi K3 ceiling and the moonshot-v1 sunset in detail
July 2026 did to the shape of the rate card what April did to its level. Kimi K3 (2026-07-16) is priced 3.2× the input and 3.75× the output of K2.6, but nothing below it moved — K2.6, K2.5 and the new K2.7 Code all still sit at or under $0.95 in / $4.00 out. That is the difference between raising a price and adding a rung: K2.6 repriced the model everyone was already calling, while K3 asks existing workloads to opt in. The practical effect is a genuine 5× ladder where model selection, not context length, is now the primary cost lever — and the first time a Moonshot bill can plausibly run into four figures. Re-running the long-context RAG archetype from Hidden costs (60M input at a 60% cache-hit rate, 15M output) on K3 instead of K2.5 takes it from roughly $63/mo to roughly $308/mo, with output alone accounting for $225 of it.
Caching is what keeps that ladder navigable. K3’s cache-hit input is 90% below its cache-miss rate ($0.30 vs $3.00), a deeper discount than the ~83% on K2.5 and K2.6 — so a reused prompt prefix on the flagship costs only 3× what it costs on K2.5, even though a fresh one costs 5×. Moonshot has effectively made cache discipline the deciding factor in whether K3 is affordable, and mis-designed prefixes are now the single most expensive mistake on the platform.
The August 31 moonshot-v1 sunset (flagged 2026-07-21) retires the mechanic that defined Moonshot’s early card — the same model priced by context window — and it is not price-neutral for the teams still on it. A workload pinned to moonshot-v1-128k ($2.00/$5.00) lands on Kimi K2.5 at $0.60/$3.00 with double the context window, a substantial cut. A workload on moonshot-v1-8k moves the other way: at $0.20 in / $2.00 out it is the cheapest input rate Moonshot publishes, and its nearest live successor costs 3× the input and 1.5× the output. The sunset therefore quietly lifts the floor of the platform while K3 lifts the ceiling, and it does so on roughly a six-week clock with no published migration mapping — the sharpest edge of the July changes for buyers with production traffic on legacy SKUs.
What’s unique : Moonshot AI’s distinctive pricing mechanics
1. Context length as a price axis — now being retired. The legacy moonshot-v1 family charges different per-token rates for the same model depending on the context window you request — $0.20/$2.00 at 8k up to $2.00/$5.00 at 128k per 1M tokens. Most vendors charge one rate and cap context; Moonshot, whose founding differentiator was long context, turned the context window itself into a billable tier. The Kimi K2 and K3 models folded that into a single flat per-model rate, and the August 31 sunset announced on 2026-07-21 ends the mechanic outright — a rare, datable example of a pricing axis being decommissioned once the product stopped needing it.
2. Context caching as the headline cost lever — and it deepens as the sticker rises. Moonshot pioneered context caching for LLM APIs in 2024, billing cache-hit prompt prefixes 80–90% below cache-miss. The discount is not uniform: it is ~83% on K2.5 ($0.10 vs $0.60) and K2.6, but 90% on Kimi K3 ($0.30 vs $3.00), so a reused prefix on the flagship costs only 3× the K2.5 rate while a fresh one costs 5×. For agents and RAG systems, caching — not the sticker rate — is what actually determines the bill, and Moonshot was early enough that the primitive shaped how the broader token economics market now prices repeated context.
3. Throughput sold as a flat 2× SKU. Kimi K2.7 Code HighSpeed is the same model with the same 262,144-token context, priced at exactly double every meter — $1.90 in / $8.00 out / $0.38 cache-hit versus $0.95 / $4.00 / $0.19 — and what you buy is speed (~180 tokens/s output, up to 260 in short contexts). Most vendors bury latency in an enterprise contract or a provisioned-capacity commitment; Moonshot exposes it as a model id you can switch to per request, with a doubling that needs no calculator. It is the cleanest expression yet of speed as an independently priced dimension rather than a bundled service level.
4. Open weights plus a recharge-tiered, price-war API. Kimi K2 models ship open-weight under a modified MIT license, yet Moonshot monetizes hosted inference at rates aggressive enough to pressure OpenAI and Anthropic. Layered on top is a recharge model — API rate limits scale with cumulative top-ups from $1 (Tier0) to $3,000 (Tier5), and launch promotions grant 10–30% voucher credit on large single top-ups. The K3 rebate running to 2026-08-12 shows how sharp that mechanic has become: one reward per Organization ID, calculated only from the highest-value transaction on the day of your first top-up in the window, on non-refundable balance. It is an uncontracted prepaid commit that pushes buyers to make one big, immediate prepayment — consumer psychology doing the work an annual contract normally does.
Strengths & weaknesses
| Strengths | Weaknesses |
|---|---|
| Among the lowest public per-million-token rates — Kimi K2.5 at $0.60 in / $3.00 out undercuts most Western frontier models, and K3’s arrival left every K2 rate untouched | Output-token premium dominates: output is 5× the cache-miss input rate on both K2.5 ($3.00/M) and K3 ($15.00/M), surprising generation-heavy workloads |
| Deep context-caching discount (80–90% off) rewards stable system prompts, and it is deepest on the priciest model (90% on K3) | Real cost depends heavily on cache-hit rate, which is hard to predict before deployment — and the penalty for getting it wrong scales with the K3 sticker |
| Open weights under modified MIT license — a credible self-host hedge against lock-in | Flagship access is now a genuine premium: K3 at $3.00/$15.00 is ~5× the K2 line, so “Kimi is cheap” no longer describes the whole card |
| Fully public rate card — no “contact sales” wall for either the assistant or the API, including the K3 flagship | Two price increases in four months (K2.6 +58% input, then the K3 ceiling) confirm the era of relentless cuts is over |
| Free Kimi assistant, a low $19 entry tier, and a flat ~20% annual discount seed and retain adoption | The plan card at kimi.com/membership/pricing renders nothing to a logged-out visitor; the real numbers live in a help-center article most buyers never reach, and the iOS in-app prices are a third, slightly different set |
| Recharge tiers and the 10–30% K3 launch rebate reward committed developers without formal commit contracts | The moonshot-v1 sunset (August 31) and the removal of legacy K2 / K2 Thinking SKUs force migration on a ~six-week clock, with no published successor mapping |
Billing UX : usage tracking and overage controls
- Recharge-tiered rate limits — a published six-row table maps cumulative recharge to throughput: Tier0 at $1 (3 RPM, 500,000 TPM, 1,500,000 TPD), Tier1 at $10 (200 RPM, 2M TPM, unlimited TPD), Tier2 at $20, Tier3 at $100, Tier4 at $1,000 and Tier5 at $3,000 (1,000 concurrent, 10,000 RPM, 5M TPM). You must recharge at least $1 before any call, and Moonshot reserves the right to temporarily tighten limits when the cluster is saturated.
- Cumulative-recharge starter voucher — reaching $5 of cumulative recharge automatically grants a $5 voucher. Vouchers themselves do not count toward the cumulative-recharge total that unlocks the next tier.
- K3 Launch Top-Up Rebate (2026-07-15 to 2026-08-12) — a single top-up of ≥ $20 earns a tiered voucher: 10% at $20–$99, 20% at $100–$299, 25% at $300–$999 and 30% at ≥ $1,000, capped at $4,000 per voucher and valid 90 days. One reward per Organization ID, calculated only from the highest-value transaction on the day of your first top-up in the period — all other top-ups are excluded. Applies only to the Kimi API Open Platform (pay-as-you-go), not to the Kimi app or Kimi Code. Voucher balance is deducted before cash, and recharge amounts are non-refundable.
- Automatic context caching — every current model (K3, K2.7 Code, K2.6, K2.5) supports automatic context caching, and the cache-hit input rate is a separate published column billed 80–90% below cache-miss.
- Per-request reasoning control — K3 exposes a top-level
reasoning_effortfield (low/high/max, defaultmax), so the cost of thinking is a request-level dial rather than a separate SKU. - Tax handling at checkout — the rate card states that prices exclude applicable taxes and that tax is calculated at checkout based on your jurisdiction.
- Open-weight escape hatch — because the K2 family is published on Hugging Face, teams can self-host to cap cost rather than scaling hosted spend.
- Consumer annual billing — each paid Kimi tier has a matching once-a-year price ($180 / $372 / $948 / $1,908, i.e. $15 / $31 / $79 / $159 per month), a flat ~20% commit-for-discount lever on the consumer side. Credits reset at the start of each billing cycle, on the subscription anniversary rather than the calendar month.
- Currency split — an international USD card (platform.kimi.ai) sits alongside a China-native RMB ¥ card, with rates and availability that can differ by region.
Strategic wins : Why Moonshot AI’s pricing decisions worked
1. Turning long context into a price axis, then a brand
Moonshot built its early reputation on long context, then priced it directly — the moonshot-v1 context tiers made “how much context you need” a literal billing dimension. That tied the headline differentiator to the revenue line and trained the market to associate Kimi with long-context value before the price war began. The July 2026 sunset closes the loop cleanly: once a 262,144-token window became table stakes on K2 and K3 shipped with 1,048,576, the axis had nothing left to sort buyers by, and Moonshot retired it rather than defending it. See choosing the right usage metric for why aligning the meter with the differentiator compounds — and why a meter has a shelf life.
2. Pioneering context caching as a cost lever
By shipping context caching in 2024 — billing cache hits ~80–85% cheaper — Moonshot gave developers a way to slash real costs on stable, repeated context, which made aggressive headline rates even more attractive for agentic and RAG workloads. It was early enough to influence how the broader market now prices reused context, a structural win beyond any single rate. This is the usage-based pricing discipline of pricing the marginal cost, not the gross call.
3. Open weights plus a price war to win developer share
Releasing Kimi K2 open-weight and pricing hosted inference aggressively enough to top Hugging Face downloads turned model R&D into distribution — developers evangelize the open models while Moonshot monetizes managed inference and the assistant. Pairing that with recharge bonuses built a committed-spend base, mirroring the shift away from rigid licensing toward flexible, usage-anchored monetization.
4. Raising the ceiling instead of raising the card
The July 2026 K3 launch took Moonshot’s top rate from $0.95/$4.00 to $3.00/$15.00 without moving a single existing price: K2.6, K2.5 and the new K2.7 Code all stayed put. That converts what would have been a 3× price increase into a self-selection problem — teams that need a 2.8T-parameter model with a 1M-token window pay for it, and everyone else keeps the rate they budgeted for. Compared with April’s K2.6 bump, which repriced the model developers were already calling and drew “price hike” coverage, the ceiling move buys the same revenue mix expansion with none of the migration friction, and it pairs the increase with a deeper 90% cache discount so the premium is escapable by design.
Areas to improve : Gaps in Moonshot AI’s pricing approach
1. Make total cost predictable before deployment
Because the bill hinges on cache-hit rate and model choice, the headline rate understates real spend — and Kimi K3 raised the cost of guessing wrong by roughly 5×. A “estimated cost per workload” calculator that factors expected cache hits, model tier and the K3-versus-K2 decision — surfaced before the first top-up rather than after — would reduce the bill-shock and unpredictability risk that usage pricing is meant to remove, especially now that a non-refundable prepaid balance funds the meter.
2. Publish the assistant plan card to logged-out buyers
The Kimi assistant tiers (Adagio through Vivace) lead with agent-credit counts and code-credit multipliers rather than numeric message and long-context caps, and the plan page at kimi.com/membership/pricing renders nothing to a logged-out visitor — a prospective subscriber has to find the help-center article to learn that annual billing runs $180 / $372 / $948 / $1,908, or read the App Store listing and get a slightly different set of Apple price points. Publishing those numbers on the plan card itself with concrete per-tier quotas would let buyers self-select without fear of silent throttling during capacity crunches — the very problem the 2024 tipping feature exposed — and would make the consumer track as verifiable as the API card already is.
3. Give the moonshot-v1 sunset a published migration path
The August 31 sunset lands roughly six weeks after it appeared in the docs, and the docs state the date without naming a successor per SKU or explaining what the move costs. moonshot-v1-128k users get cheaper tokens and double the context on Kimi K2.5; moonshot-v1-8k users lose the cheapest input rate on the platform and pay about 3× more. A one-page mapping table with per-SKU rate deltas and a dated cutover checklist would turn a silent repricing into a decision buyers can plan around — the same discipline as picking a meter buyers can forecast, covered in understanding usage-based pricing models.
4. Reconcile the USD and RMB cards
The international USD card and China-native RMB ¥ card can diverge in rate, model availability, and cadence (the K2.6 increase was expressed partly in yuan). A clearer, reconciled cross-currency view would help global teams evaluating Moonshot against other AI companies’ transparency avoid surprises tied to which card they land on.
Monetization stack & signals : how Moonshot AI builds & buys its revenue engine
Buys 0 Builds 1
Builds its own meter: the self-serve per-token API and the 2024 context-caching primitive are run in-house, disclosed in Moonshot's own pricing docs, not bought from a billing vendor. Hiring signal is genuinely unavailable — careers.kimi.com is region-gated with no Western public ATS.
-
“We bill both the Input and Output based on usage — Moonshot's own first-party API docs run per-1M-token input/output metering, plus a distinct lower cache-hit input rate via the Context Caching feature it introduced in 2024.”
Signals reviewed · derived from product docs
Key takeaways
- Price the differentiator — then retire the axis when the product absorbs it. Moonshot turned long context into a literal billing axis on moonshot-v1, then sunset that family on August 31, 2026 once million-token windows made the axis meaningless. A meter has a shelf life, and holding one past its usefulness is how price sheets calcify.
- Caching is the real meter. An 80–90% cache-hit discount means the sticker rate is only half the story, and Moonshot cut it deepest (90%) on its most expensive model — so the discount is doing the work of making a premium tier reachable rather than just rewarding good prompt hygiene.
- Open weights make aggressive pricing safer. Releasing Kimi K2 open-weight gave Moonshot distribution and an escape hatch that blunts backlash — even when it later raised prices on K2.6 and opened a 5× premium above it.
- Raise the ceiling, not the whole card. April’s +58% K2.6 bump repriced the model everyone was calling and read as a market signal; July’s Kimi K3 added a $3.00/$15.00 rung while leaving every existing rate alone, capturing high-end willingness-to-pay without forcing a single customer to migrate.
- Recharge mechanics carry consumer psychology into a dev API. Tiered rate limits and a launch rebate that only counts your first day’s largest top-up reward committed prepaid spend without formal commit contracts — a consumer-style lever applied to developer monetization.
UBP implications
- A billable dimension has a lifecycle, and retiring one is a repricing. Moonshot showed that “how much context you need” can be tiered and charged for — and then showed the other half of the lesson: when the capability commoditizes, the axis is decommissioned, and everyone sitting on its cheapest rung (moonshot-v1-8k at $0.20/M) gets silently repriced upward. UBP designers should plan the sunset of a meter with the same care as its launch.
- Price the marginal cost, not the gross call. Context caching prices reused context near its true marginal cost, which makes aggressive headline rates sustainable. Moonshot’s July move goes further by widening the cache discount to 90% exactly where the sticker is highest — the discount is what makes a 5× premium tier sellable, so the escape hatch should be designed alongside the increase, not after it.
- Open weights reshape the value question from “what” to “where” — and increasingly “how fast.” When the model is free to download, the priced dimension becomes managed inference, caching, and the assistant rather than the model itself; the K2.7 Code HighSpeed SKU, identical to its base model at exactly double every rate, shows throughput emerging as an independently priced meter. UBP design has to follow the cost driver customers can’t trivially replicate, an early signal of the move toward outcome-shaped pricing.
Sources
- Kimi API Platform (platform.moonshot.ai → platform.kimi.ai) (accessed 2026-07-21)
- Kimi API pricing documentation (accessed 2026-07-21)
- Flagship Model Kimi K3 pricing (accessed 2026-07-21)
- Coding Model Kimi K2.7 Code pricing (accessed 2026-07-21)
- Generation Model Moonshot V1 pricing (accessed 2026-07-21)
- Recharge and rate limiting tiers (accessed 2026-07-21)
- Kimi K3 Launch Top-Up Rebate terms (accessed 2026-07-21)
- Kimi Code (accessed 2026-07-21)
- Kimi assistant (accessed 2026-07-21)
- Kimi 企业版 (Kimi Enterprise) (accessed 2026-07-21)
- Kimi Help Center — Pricing details (monthly vs. annual plan table) (accessed 2026-07-21)
- Kimi Help Center — Membership plans overview (accessed 2026-07-21)
- Kimi Help Center — Credit update & usage rules (accessed 2026-07-21)
- Kimi iOS app in-app-purchase price list (Moonshot AI, App Store) (accessed 2026-07-21)
- Moonshot AI open weights on Hugging Face (accessed 2026-07-21)
- Browse the pricing blueprint corpus
Bottom line
Moonshot AI prices two surfaces from its Kimi platform: a tempo-named assistant ($0 Free to $199/mo Vivace, with annual billing a flat ~20% cheaper) and a per-token API that now spans a 30× range. July 2026 reshaped the card rather than just its level — Kimi K3 opened a genuinely premium ceiling at $3.00 in / $15.00 out while every K2 rate stayed put, and the context-tiered moonshot-v1 family was flagged for an August 31 sunset that retires context length as a billing axis. What remains constant is the deep context-caching discount Moonshot pioneered in 2024, now 90% off on K3, layered over open weights you can download and self-host. The main friction is cost predictability: the real bill depends on cache-hit rate and model choice far more than the headline rate suggests, and with K3 on the card the cost of choosing wrong is roughly 5× what it was.
Want to compare Moonshot AI against other foundation-model providers? See Mistral AI and OpenAI, or browse the full pricing blueprint.
Pricing timeline : Major events on a vertical axis
Each milestone below corresponds to a public pricing change, product launch, or material adjustment. Major events use a filled marker; minor adjustments use a faded one.
moonshot-v1 sunset on August 31 retires context-as-a-meter
Moonshot's model-pricing overview now describes the Moonshot V1 family as the 'classic generation model series; full platform sunset expected on August 31', ending the mechanic that charged different per-token rates for the same model by context window ($0.20/$2.00 at 8k up to $2.00/$5.00 at 128k). The legacy Kimi K2 0711/0905/Turbo and K2 Thinking models have also disappeared from the card. Migration is not price-neutral: moonshot-v1-128k users move down to Kimi K2.5 at $0.60/$3.00 with double the context, while moonshot-v1-8k users lose the cheapest input rate on the platform and land on a 3× higher one.
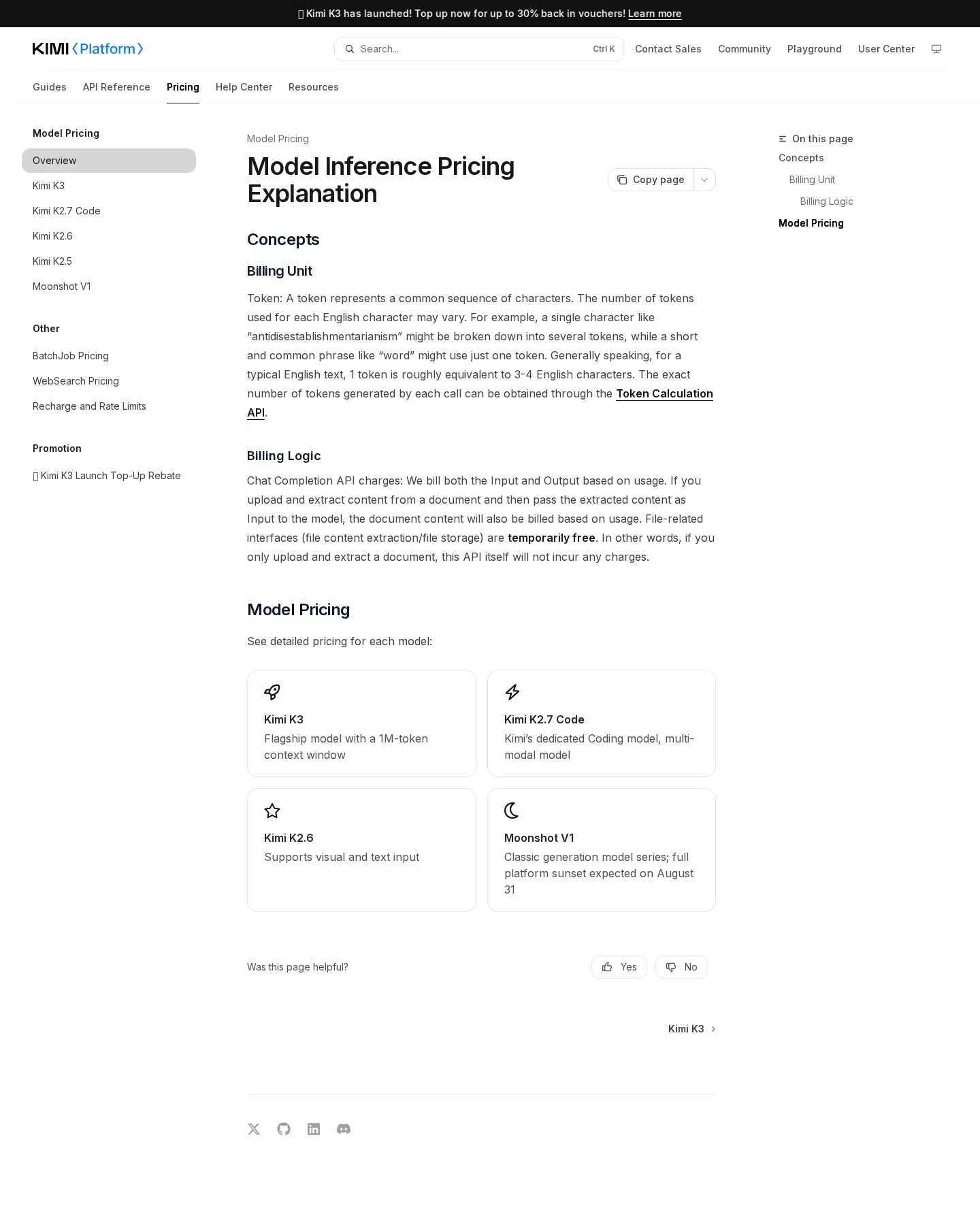
Kimi K3 launches at $3.00/$15.00 — a new price ceiling
Moonshot ships flagship Kimi K3 (2.8-trillion parameters, natively multimodal, 1,048,576-token context) on its research page dated 2026-07-16 and prices it at $3.00/M input (cache miss), $0.30/M cache-hit input and $15.00/M output — roughly 3.2× the input and 3.75× the output of Kimi K2.6. A coding SKU, Kimi K2.7 Code, sits below it at $0.19/$0.95/$4.00 per 1M with a HighSpeed variant at exactly double ($0.38/$1.90/$8.00) that buys throughput only. K2.6 and K2.5 rates are untouched, so the increase is a new rung above the ladder rather than a repricing across the card, and a launch top-up rebate (2026-07-15 to 2026-08-12) returns 10–30% of a single top-up as vouchers.
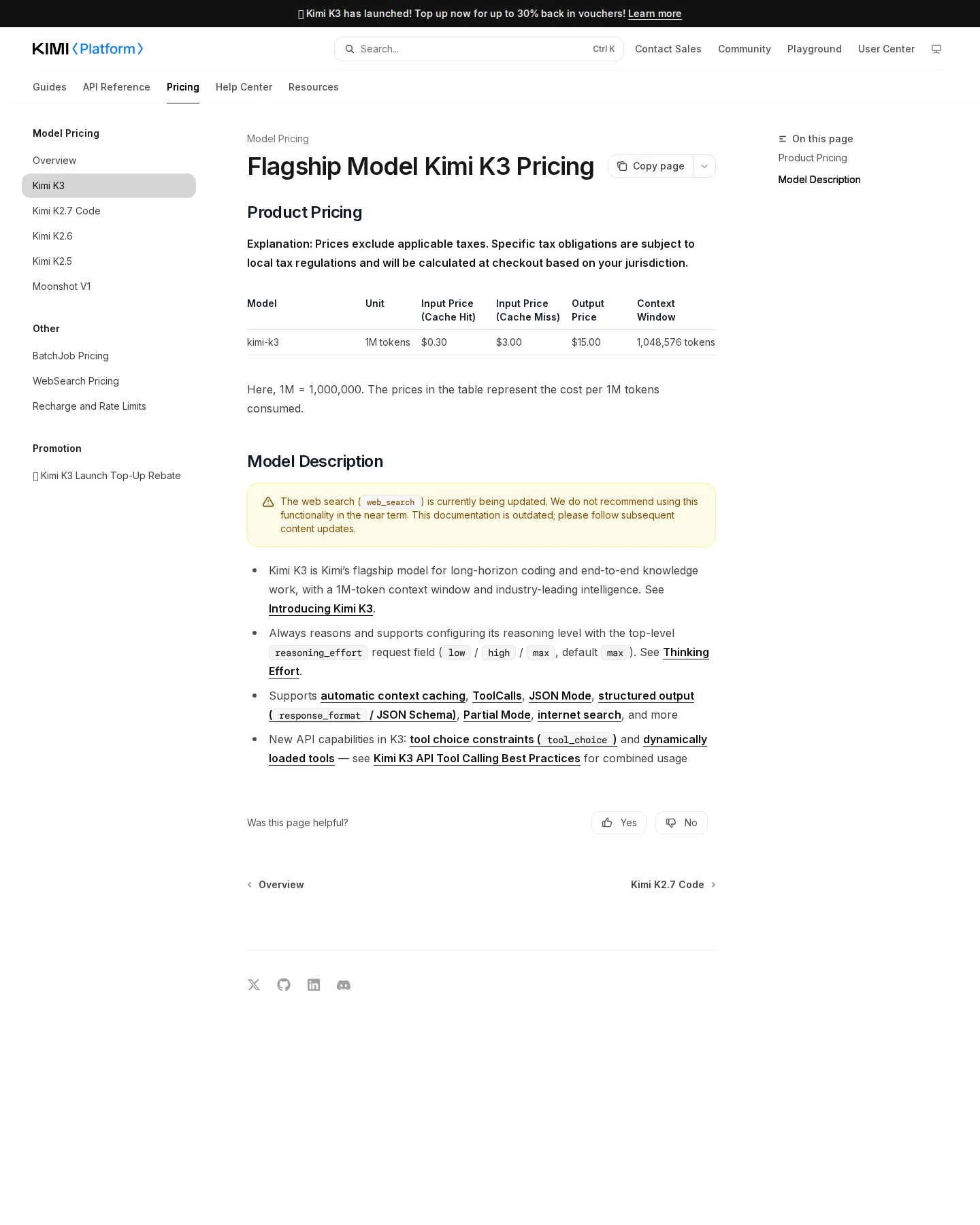
Live snapshot: two-track Kimi pricing reconstructed
Captured rates: Kimi assistant Free/$19/$39/$99/$199 per month; moonshot-v1 context-tiered API ($0.20/$2.00 at 8k up to $2.00/$5.00 at 128k); Kimi K2.5 $0.60/$3.00 (cache-hit $0.10) and K2.6 $0.95/$4.00 (cache-hit $0.16) per 1M tokens. The moonshot.cn capture returned a stale nginx page; prices reconstructed from the international card mirrors + press.
Kimi K2.6 raises prices 58% — a pre-IPO commercialization signal
Kimi K2.6 reaches GA around 2026-04-22 with the first material price increase: input up 58% from $0.60 to $0.95/M, output to $4.00/M (21 to 27 yuan RMB), cache-hit input to $0.16/M (0.7 to 1.1 yuan RMB). Read by observers as commercialization proof ahead of a reported Hong Kong listing. Legacy K2 models hit end-of-life 2026-05-25. (Source: KuCoin, OpenRouter; accessed 2026-06-11.)
Kimi K2.5 adds vision + agent swarm; deep cache discount
Kimi K2.5 launches open-weight with vision and agent-swarm capabilities at $0.60/M input (cache miss) / $3.00/M output, with cache-hit input at just $0.10/M — about 83% off. A top-up bonus program (20–30% voucher bonuses on large single top-ups) reinforces the recharge model. (Source: InfoQ, eesel, Kimi on X; accessed 2026-06-11.)
Kimi K2 Thinking adds reasoning at flat low rates
Kimi K2 Thinking ships on 2025-11-06 with a 262,144-token context and interleaved reasoning plus tool use, priced at $0.60/M input and $2.50/M output — holding the aggressive low-rate posture while moving up the capability curve. (Source: OpenRouter; accessed 2026-06-11.)
Kimi K2 open-weight launch ignites a price war
On 2025-07-11 Moonshot releases Kimi K2 open-weight — a 1-trillion-parameter Mixture-of-Experts model (32B active) — at aggressive API rates (around $0.15/M cache-hit input, $2.50/M output). It becomes the fastest-downloaded model on Hugging Face one day after launch and pressures OpenAI/Anthropic on price. (Source: HPCwire, Hugging Face; accessed 2026-06-11.)
Context caching pioneered to cut repeated-prompt cost
Moonshot rolls out context caching for its API — billing cache-hit prompt prefixes at a fraction of the cache-miss rate (roughly 80–85% off). It becomes a defining cost lever and an industry-influencing primitive other LLM vendors later adopt. (Source: aggregator/press reconstruction; accessed 2026-06-11.)
Viral 'tipping/recharge' reward to buy priority
Amid capacity crunches, Kimi introduces a paid tipping/recharge feature letting users pay to jump the queue and get priority during peak load — an early, much-discussed test of individual willingness-to-pay. API rate limits are also tiered by cumulative recharge. (Source: Baidu Baike, contemporaneous reporting; accessed 2026-06-11.)
2M-character context goes viral; per-token API live
Kimi expands lossless context from 200,000 to 2,000,000 Chinese characters, which goes viral across Chinese social media and drives a user surge. The moonshot-v1 developer API bills per million tokens with context-length-tiered rates (8k/32k/128k priced separately). (Source: Wikipedia, contemporaneous press; accessed 2026-06-11.)
Kimi assistant launches free, built around long context
Moonshot AI (founded March 2023) releases the Kimi assistant on 2023-10-09 — a free consumer chatbot positioned around long-context, the world's first product supporting 200,000-character Chinese input. Monetization is deferred; the product grows on the long-context hook. (Source: Wikipedia, Baidu Baike; accessed 2026-06-11.)
- · Moonshot AI's name (月之暗面, 'Dark Side of the Moon') comes from founder Yang Zhilin's favorite Pink Floyd album — the company launched on the album's 50th anniversary in March 2023.
- · The legacy moonshot-v1 API charges different per-token rates for the SAME model depending on context window: $0.20/$2.00 per 1M at 8k, but $2.00/$5.00 at 128k — context length is literally the price axis.
- · Moonshot pioneered context caching for LLM APIs in 2024; cache-hit input is billed ~80–85% below cache-miss (e.g. $0.10/M vs $0.60/M on Kimi K2.5).
Questions & answers
- What is Moonshot AI's pricing model?
- Moonshot runs a two-track model: subscriptions for the Kimi assistant (Free, then $19/$39/$99/$199 per month) and a usage-based per-token API. Every current API model is billed per million tokens with separate cache-hit and cache-miss input rates, and API rate limits scale with cumulative recharge.
- Does Moonshot AI (Kimi) offer a free tier?
- Yes. The Kimi assistant has a Free plan (named Adagio) at $0/mo with 6 agent credits, one concurrent agent task and 200 professional-database calls. The original Kimi assistant launched free in 2023 and became famous for long-context (up to 2 million Chinese characters).
- How much does the Kimi K3 API cost per million tokens?
- Kimi K3, the flagship model, is $3.00 input (cache miss) / $15.00 output per 1M tokens, with cache-hit input at $0.30/M and a 1,048,576-token context window. It is the most expensive model on Moonshot's card by a wide margin — K2.6 and K2.7 Code are $0.95 in / $4.00 out.
- Why does Moonshot charge different rates for the same model?
- The legacy moonshot-v1 family is context-length-tiered: moonshot-v1-8k is $0.20 in / $2.00 out, moonshot-v1-32k is $1.00 in / $3.00 out, and moonshot-v1-128k is $2.00 in / $5.00 out per 1M tokens. You pay more per token for a longer context window. That family is scheduled for full platform sunset on August 31, 2026; the Kimi K2/K3 models fold long context into one flat per-model rate instead.
- What is context caching and how much does it save?
- Moonshot pioneered context caching for LLM APIs in 2024. Repeated prompt prefixes that hit the cache are billed at a fraction of the cache-miss rate — 80–90% off on every current model (for example $0.10/M cache-hit vs $0.60/M cache-miss on Kimi K2.5, or $0.30/M vs $3.00/M on Kimi K3).
- Are Kimi models open-weight?
- Yes. Kimi K2 (a 1-trillion-parameter Mixture-of-Experts model launched July 2025) and its successors are released open-weight on Hugging Face under a modified MIT license, while Moonshot monetizes hosted inference per token and the managed Kimi assistant.